CVPR2019 | 专门为卷积神经网络设计的训练方法:RePr
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
CVPR2019 accepted list已经放出,极市已将目前收集到的公开论文总结到github上(包括本文及pdf下载),后续会不断更新,欢迎关注,也欢迎大家提交自己的论文:
https://github.com/extreme-assistant/cvpr2019 。今天介绍的CVPR论文是针对卷积神经网络的训练方法。

作者 | ywsun
论文链接 | https://arxiv.org/abs/1811.07275
原文地址 | https://zhuanlan.zhihu.com/p/58095683
这篇文章初看abstract和introduction,差点以为是model pruning,看到后面发现是针对卷积神经网络的训练方法,而且这个方法比较简单,但文章通过大量的分析和实验,验证了提出的训练方法非常有效,在cifar、ImageNet、VQA、object detection上涨点很多,个人觉得paper writing/representation做的非常好,ablation study做的非常充分,是我目前看过的CVPR2019中最好的一篇文章。
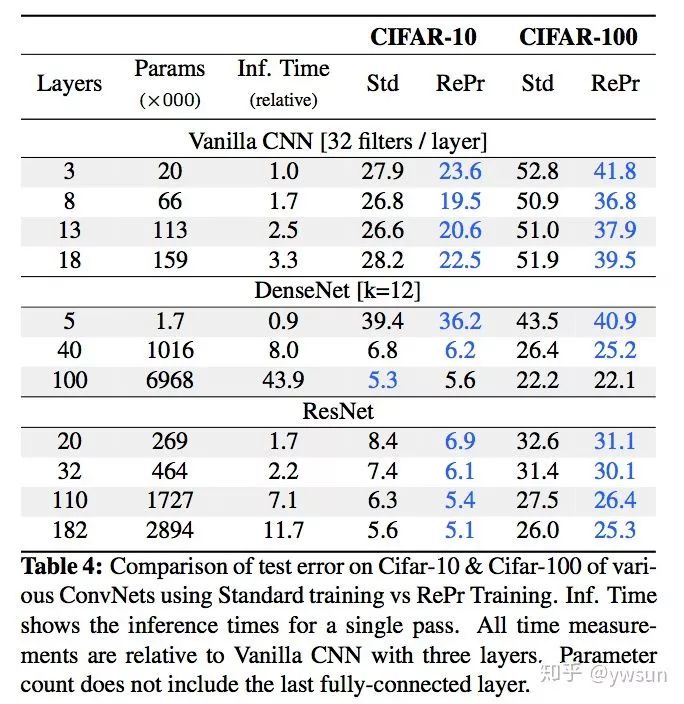
先来看效果图,用新的训练方法,测试准确率远远超过了标准的训练方法,是不是amazing?
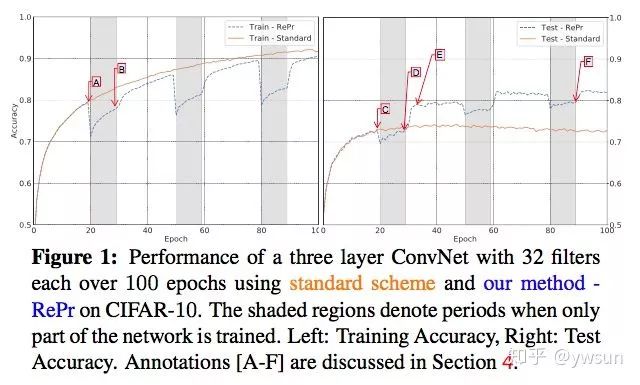
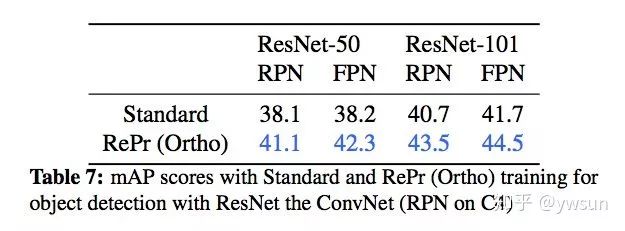
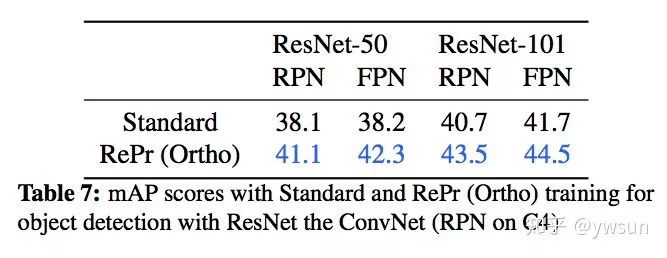
下面看看在object detection上的测试结果,RePr在ResNet50-FPN上有4.1个点的提升,在ResNet101-FPN有2.8个点的提升,可以说是非常明显了。
Introduction
卷积神经网络在视觉任务中取得了SOTA性能,我们会为不同的任务单独设计不同的网络结构,虽然网络结构不同,但使用的优化方法都是一样的,而且这些优化方法将网络权重视为单独的个体,没有考虑彼此之前的相关性。而事实上,网络权重之间是有很大联系的。为了获取最好的性能,网络经常过参数化(over-parameterized)。然而即使是过参数化的网络,也会存在很多冗余的参数。model pruning证明了一个大的网络可以通过丢弃一部分参数权重得到一个性能损失不大的小网络,从而实现网络压缩和加速。
因此文章提出了一个新的训练方法。既然网络中有些参数权重是多余,那我们训练的时候把他们丢弃(pruning),接着训练剩下的网络,为了不损失模型的capacity,然后再把丢弃的参数拿回来,效果是不是会好一点呢?基于这个想法,文章作者任务有几个重要的点:一是pruning哪些权重,而是如何再把丢弃的权重拿回来让他们发挥更大的作用。本文的一个贡献在于提出了一个metric,用于选择哪些filters丢弃。同时作者指出,即使是一个参数很少( under-parameterized )的网络,也会出现学到冗余的参数的情况,这不仅仅在多参数的网络中存在,原因就在于训练过程低效。
Motivation
特征之间的相关性越高,其泛化性能越差。为了降低特征之间的相关性,有人提出了各种方法,比如在损失函数中加入特征相关性的项,在优化目标函数的时候使的模型自动学习出低相关的特征,然而并没有什么效果。还有通过分析不同层的特征并进行聚类,这种方法在实际中不可行因为计算量巨大。还有人尝试过loss添加正则项让模型学习到相互正交的权重,最后也发现收效甚微。实验发现,仅仅通过正则化项让网络自动学习到正交的权重是不够的,文章提出的训练方法其实已经隐式地起到了正则化效果,并且对模型的收敛没有任何影响。
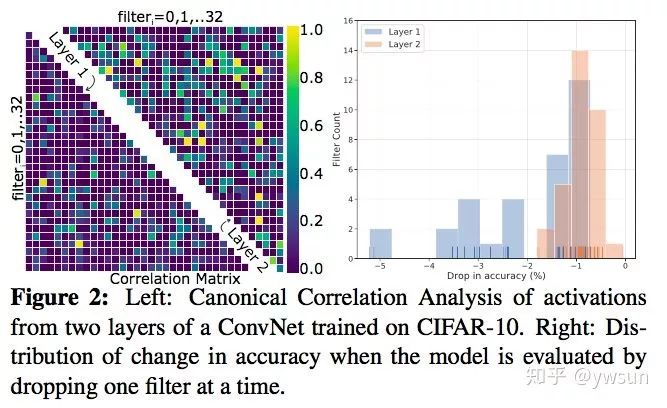
为了说明即使是参数少的模型,由于训练的低效,也会存在大量冗余的卷积核,通过一个比较小的卷积神经网络,作者可视化了不同层的卷积核对性能的影响,如下图右,layer2的大部分卷积核对性能的影响仅仅只有1%,即使是浅层的layer1,也存在大量不重要的权重。
新的训练方法:RePr
训练过程如下:方式比较简单,先训练整个网络,根据metric drop掉30%的filter,再训练剩下的网络,再把drop的filter拿回来,用于现有filters正交的方式初始化。迭代这个过程N次。

算法中最重要的其实这个metric,即如何选出需要drop的filters。
文章写的很明白,一个layer的多个卷积核可以用一个matrix表示,也就是 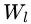
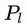
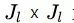
同时文章还说明了,计算这个metric是在一个layer内,但rank是在所有layer进行的,目的是为了不让layer这个因数影响filter的rank,避开layer的差异性,同时也不引入过多的超参。

文章一个值得称赞的点就是ablation study部分做的非常详细而充分。文章做了大量的对比实验,对该方法涉及的参数进行了讨论,并对比了不同的optimization的影响,同时也比较了dropout、knowledge distillation,指出该方法不仅和他们有很大区别,与他们结合还能得到更好的结果。
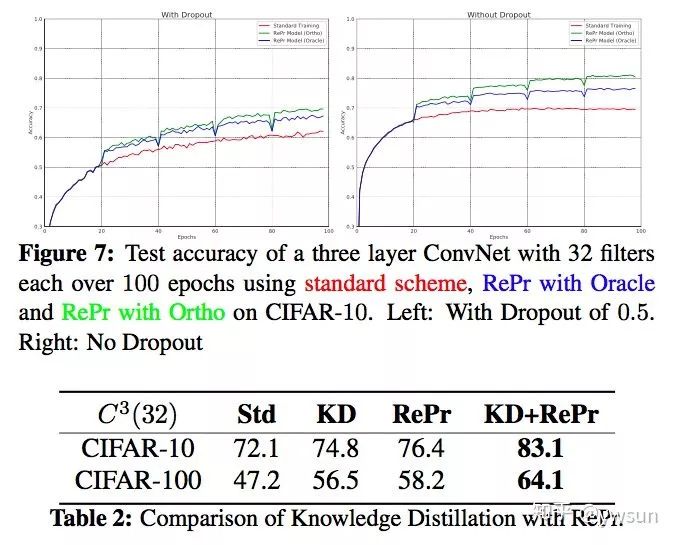
Results
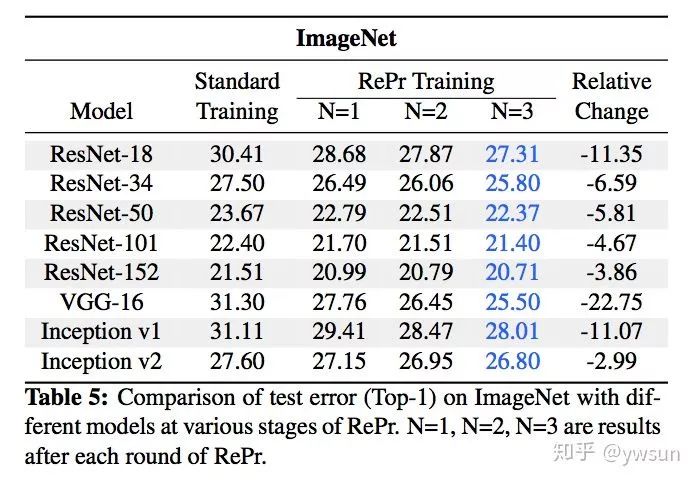
作者做了大量实验,验证该方法在cifar10,cifar100,imagenets上都能取得很好的性能。
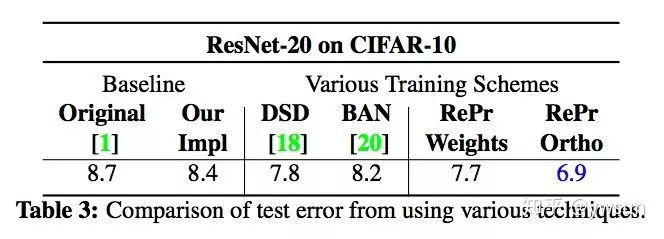
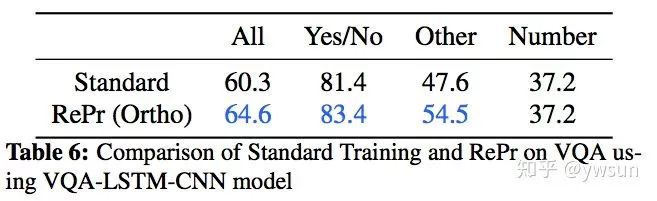
这是RePr早其他task上的表现,VQA上有不同程度的涨点,效果明显。
object detection上涨点达到了ResNet50 4.1个点,ResNet101 2.8个点,可是说是非常明显了。
总的来说,这是一篇看起来真正做work的paper,做法简单有效,实验充分合理,相信很多人会去复现这篇paper,有些超参还是需要调一调的,具体效果如何还需要看实际情况,特别是detection部分,如果真的work,未来会成为刷SOTA的一个标配。
几个疑问的点:
为何文章中说ResNet、Inception的设计是为了减低feature之间的相关性?
对detection部分work比较感兴趣,希望知道更多的细节。
欢迎留言区评论交流~
*延伸阅读
过往Net,皆为调参?一篇BagNet论文引发学界震动
解析深度学习:3 个经典的卷积神经网络案例分析
1300篇!CVPR2019接收结果公布,你中了吗?(附部分论文链接)
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~




