FAIR何恺明等人提出组归一化:替代批归一化,不受批量大小限制
选自arXiv
作者:吴育昕、何恺明
机器之心编译
自 Facebook 在 2017 年 6 月发布 1 小时训练 ImageNet 论文以来,很多研究者都在关注如何使用并行训练来提高深度学习的训练速度,其研究所使用的批尺寸也呈指数级上升。近日,FAIR 研究工程师吴育昕、研究科学家何恺明提出了组归一化(Group Normalization)方法,试图以小批尺寸实现快速神经网络训练,这种方法对于硬件的需求大大降低,并在实验中超过了传统的批归一化方法。
批归一化(Batch Norm/BN)是深度学习中非常有效的一个技术,极大地推进了计算机视觉以及之外领域的前沿。BN 通过计算一个(迷你)批量中的均值与方差来进行特征归一化。众多实践证明,它利于优化且使得深度网络易于收敛。批统计的随机不确定性也作为一个有利于泛化的正则化项。BN 已经成为了许多顶级计算机视觉算法的基础。
尽管取得了很大的成果,BN 也会因为归一不同批尺寸的独特行为而有缺点。特别是,BN 需要用到足够大的批大小(例如,每个工作站采用 32 的批量大小)。一个小批量会导致估算批统计不准确,减小 BN 的批大小会极大地增加模型错误率(图 1)。结果导致,如今许多模型都使用较大的批训练,它们非常耗费内存。反过来,训练模型时对 BN 效力的极度依赖性阻碍了人们用有限内存探索更高容量的模型。
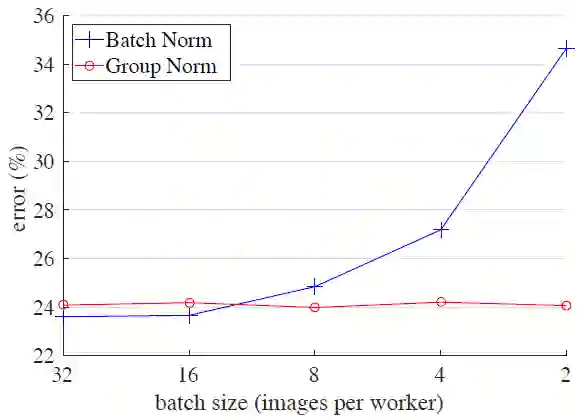
图 1:ImageNet 分类误差 vs. 批大小。这是在 ImageNet 训练集上用 8 个工作站(GPU)训练、在验证集上进行评估的 ResNet-50 模型。
计算机视觉任务(包括检测、分割、视频识别和其他基于此的高级系统)对批大小的限制更加严格。例如,Fast/er 和 Mask R-CNN 框架 [12, 46, 18] 使用的批大小为 1 或 2 张图像,为了更高的分辨率,其中 BN 通过变换为线性层而被「固定」[20];在 3D 卷积视频分类中 [59, 6],时空特征的出现导致时间长度和批大小之间的权衡。BN 的使用通常要求这些系统在模型设计和批大小之间作出妥协。
本文提出了组归一化(Group Normalization,GN)作为批归一化(BN)的替代。作者发现很多经典的特征例如 SIFT[38] 和 HOG[9] 是分组的特征并涉及分组的归一化。例如,一个 HOG 向量是多个空间单元的输出,其中每个单元由一个归一化的方向直方图表征。类似地作者提出了 GN 作为层将通道分组并在每个组中将特征归一化(见图 2)。GN 并没有利用批量的维度,它的计算是独立于批量大小的。
GN 在大范围的批量大小下都能表现得很稳定(见图 1)。当批量大小为 2 个样本时,在 ImageNet 训练的 ResNet-50 上,相比于 BN 的对应变体,GN 获得的误差率要小 10%。在常规的批量大小设置下,GN 获得的性能和 BN 相当(相差约 0.5%),并超越了其它的归一化变体 [3,60,50]。此外,虽然批量大小可能被改变,而 GN 的设置则可以从预训练阶段迁移到微调阶段。在 COCO 目标检测和分割任务的 Mask R-CNN 上,以及在 Kinetics 视频分类任务的 3D 卷积网络上,相比于 BN 的对应变体,GN 都能获得提升或者超越的结果。GN 在 ImageNet、COCO 和 Kinetics 上的有效性表明 GN 是 BN 的有力竞争者,而 BN 在过去一直在这些任务上作为主导的方法。
目前已有的优化方法包括层归一化(LN)[3] 和实例归一化(IN)[60](如图 2 所示),它们也避免了在批量维度上的归一化。这些方法对于训练序列模型(RNN/LSTM)或生成模型(GAN)很有效。本文的实验研究表明,LN 和 IN 在视觉识别上的成功率都是很有限的,而 GN 则能获得更好的结果。相反地,GN 也许还能替代 LN 和 IN,在序列或生成模型上得到应用。这已经超越了本文的内容,但这些方向都是值得探索的。
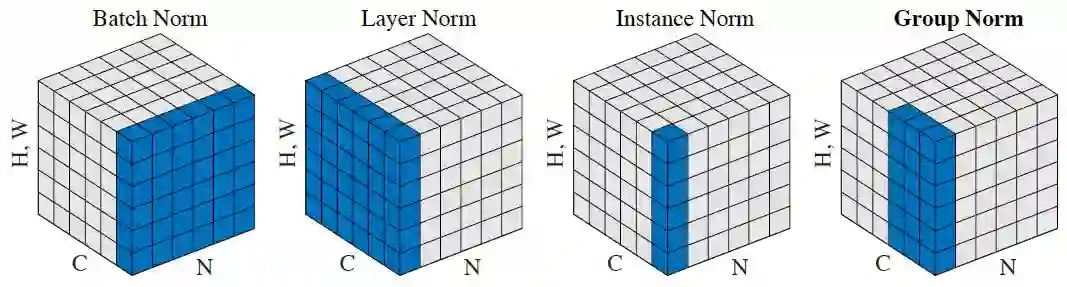
图 2:归一化方法。每个子图展示了一个特征图张量,N 是批坐标轴,C 是通道轴,(H,W)是空间轴。通过计算蓝色像素值的和,这些像素被同样的平均值与方差归一化的。
组归一化
视觉表征的各个通道其实并不完全独立。SIFT [38]、HOG [9] 和 GIST [40] 的经典特征都设计为按分组来表征,其中每一组通道由一些直方图(histogram)构成。这些特征通常通过在每个直方图或每个方向上执行分组归一化而得到处理。VLAD [29] 和 Fisher Vectors (FV) [43] 等高级特征同样也是分组的特征,其中每一组特征可以认为是关于集群(cluster)计算的子向量。
类似的,我们没必要将深度神经网络视为非结构化的向量。例如,对于网络的第一个卷积层 conv1,期望卷积核和其水平翻转在自然图像上呈现相似的卷积核反馈分布是合理的。如果 conv1 正好近似学习到这一对卷积核,或将水平翻转与其它转换设计到架构中 [11, 8],那么我们可以将这些卷积核的对应通道一同归一化。
神经网络的较高层级会有更加抽象的特征,它们的行为也变得不那么直观。然而,除了方向(SIFT [38]、HOG [9] 或 [11, 8])外,还有很多可以导致分组的因素,例如频率、形状、照明和纹理等。此外,它们的系数可以相互独立。实际上,神经科学中广泛接受的计算模型是在所有细胞反馈中执行归一化 [21, 51, 54, 5],「具有各种感受野中心(覆盖视觉范围)和各种时空频率调谐」(p183, [21]);这不仅发生在初级视觉皮层,同样可以发生在「整个视觉系统」[5]。受到这些研究工作地启发,我们为深度神经网络提出了一般分组归一化方法。
实现
GN 可以通过 PyTorch [41] 和 TensorFlow [1] 中的几行代码轻松实现,二者均支持自动微分。图 3 是基于 TensorFlow 的代码。实际上,我们仅需要指定均值和方差的计算方式,恰当的坐标轴由归一化方法定义。

图 3:基于 TensorFlow 的组归一化 Python 代码。
实验结果
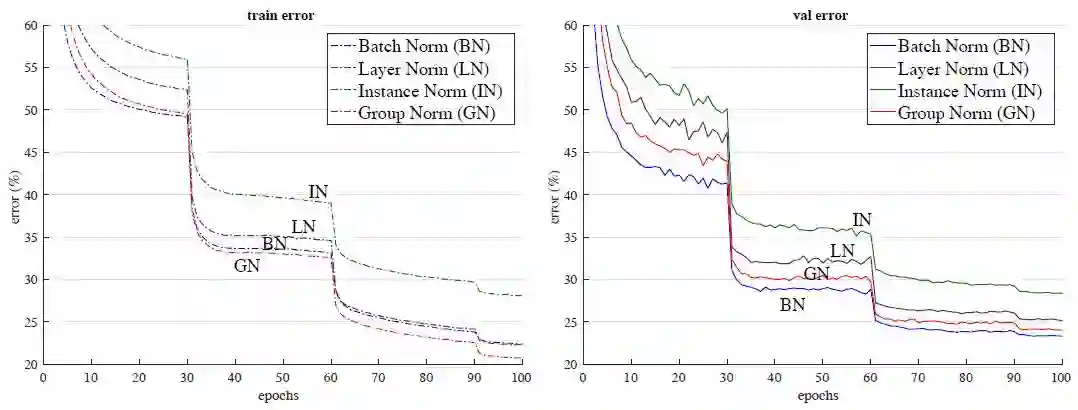
图 4:批量大小为 32 张图像/GPU 时的误差曲线对比。图中展示了 ImageNet 训练误差(左)和验证误差(右)vs. 训练 epoch 数量。模型是 ResNet-50。
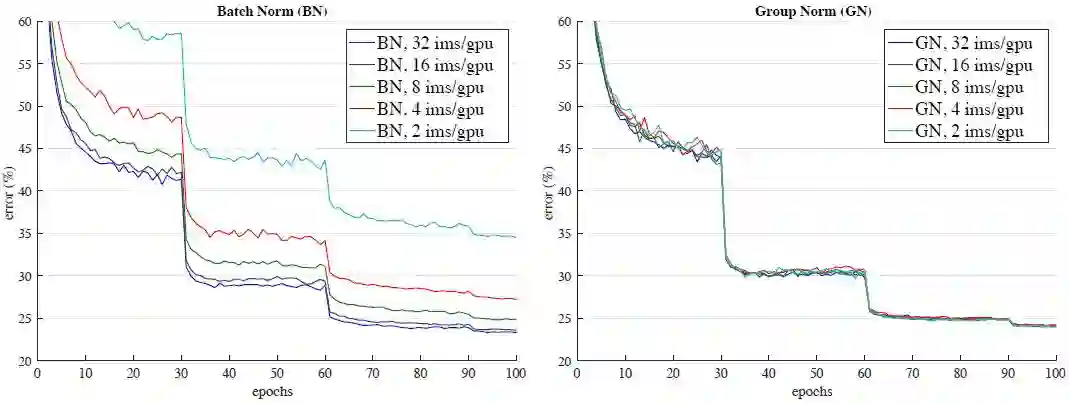
图 5:对批量大小的敏感度:BN(左)和 GN(右)在 ResNet-50 上的验证误差率,训练是以 32、16、8、4 和 2 张图像/GPU 的吞吐量进行的。
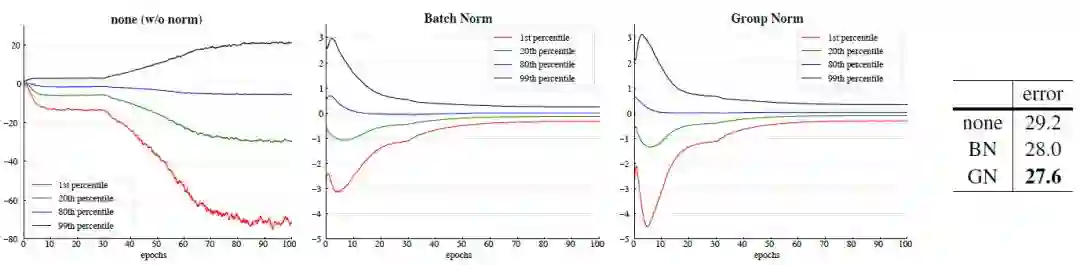
图 6:VGG-16 上 conv5 3 输出(在归一化和 ReLU 之前)的演进特征分布,以 {1, 20, 80, 99} 百分比位置的返回值进行结果展示。右侧表格显示了 ImageNet 验证误差(%)。模型是以 32 张图片/GPU 的吞吐量进行训练的。

表 4:在 COCO 数据集上的目标检测和分割结果,使用 Mask R-CNN(ResNet-50 C4)。BN*表示 BN 被冻结。
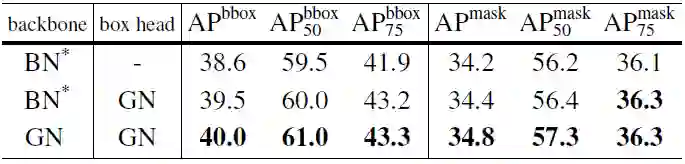
表 5:在 COCO 数据集上的目标检测和分割结果,使用 Mask R-CNN(ResNet-50 FPN 以及 4conv1fc 边框)。BN*表示 BN 被冻结。
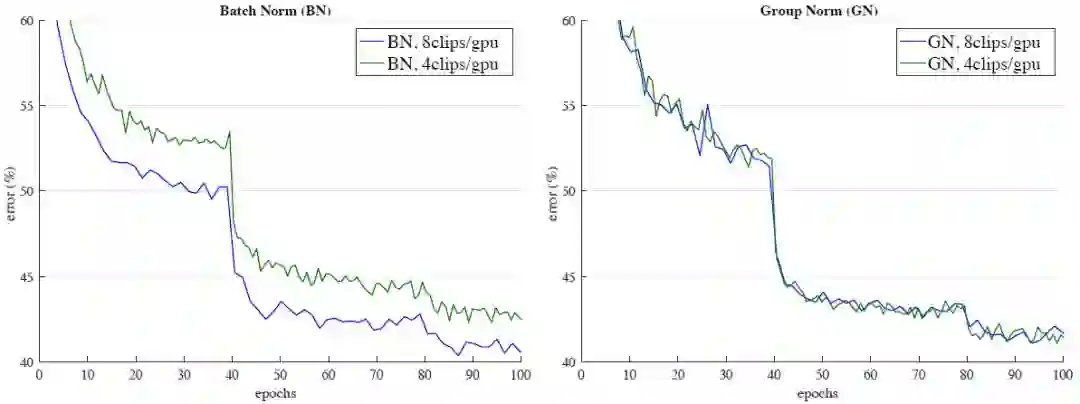
图 7:Kinetics 中,输入长度为 32 帧的误差曲线。FAIR 的研究人员展示了 ResNet-50 I3D 分别应用 BN(左侧)和 GN(右侧)的验证误差率,批量大小为 8 和 4 clips/GPU。实验监控的验证误差率是通过和训练集相同的数据增强得到的 1-clip 误差率。
论文:Group Normalization

论文链接:https://arxiv.org/abs/1803.08494
批归一化(BN)是深度学习发展史中的一项里程碑技术,使得大量神经网络得以训练。但是,批量维度上的归一化也衍生出一些问题——当批量统计估算不准确导致批量越来越小时,BN 的误差快速增大,从而限制了 BN 用于更大模型的训练,也妨碍了将特征迁移至检测、分割、视频等计算机视觉任务之中,因为它们受限于内存消耗,只能使用小批量。在本论文中,我们提出了作为批归一化(BN)简单替代的组归一化(GN)。GN 把通道分为组,并计算每一组之内的均值和方差,以进行归一化。GN 的计算与批量大小无关,其精度也在各种批量大小下保持稳定。在 ImageNet 上训练的 ResNet-50 上,当批量大小为 2 时,GN 的误差比 BN 低 10.6%。当使用经典的批量大小时,GN 与 BN 相当,但优于其他归一化变体。此外,GN 可以自然地从预训练阶段迁移到微调阶段。在 COCO 的目标检测和分割任务以及 Kinetics 的视频分类任务中,GN 的性能优于或与 BN 变体相当,这表明 GN 可以在一系列不同任务中有效替代强大的 BN;在现代的深度学习库中,GN 通过若干行代码即可轻松实现。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


