迁移Prompt–解决Prompt Tuning三大问题!
文 | Harris
刘鹏飞博士将近代NLP的研究划归为四种范式 [1] 并把预训练语言模型加持下的Prompt Learning看作是近代自然语言处理技术发展的“第四范式”。当我们使用新范式的方法的时候,能够意识到它带来的优异性可能是以某种“人力”牺牲为代价的。而如何让这种人力代价降到最低,往往就是新范式里需要解决的核心问题 [2]。Prompt Learning刚兴起之时,prompts大多是人工设计的,为了减少人工,后来涌现出一系列用自动化方式获取prompts的研究工作。Soft prompts由于其易用性、易理解性和优异的性能在近一年来获得了广泛的关注。今年四月份,谷歌提出Prompt-tuning [3],其为每个任务分配一个可训练的soft prompt并保持预训练模型的参数不变,发现在使用较大的预训练模型时,Prompt-tuning可以媲美微调整个预训练模型(Model-tuning)的性能。虽然Prompt-tuning非常有效,其仍然面临如下三个问题:
-
在使用 较小的预训练模型时,Prompt-tuning的表现仍旧与Model-tuning的表现有明显的差距 -
在 Few-shot的场景下,Prompt-tuning的表现并不理想 -
相比于Model-tuning,Prompt-tuning的 收敛速度较慢,需要训练更多的步数
幸运的是,这些问题都可以通过更好地初始化soft prompts解决!一个直观的想法是可以通过预训练模型词汇表中的一些词来初始化,比如对于分类问题就可以用类别标签对应的词来初始化。但是类别标签词数目有限而且并没有很多任务相关的信息。
一个更好的方法是:用在源任务上训练的soft prompts来初始化目标任务的soft prompts!这个想法有点类似迁移学习的意思。迁移学习通俗来讲,就是运用已有的知识来学习新的知识。核心是找到已有知识和新知识之间的相似性。迁移prompts也类似,如果源任务与目标任务越相似,那么迁移的效果可能就越好。针对prompts的可迁移性问题,谷歌和清华的研究员们进行了初步的探索,笔者接下来为大家一一解读。想要快速浏览 takeaway 干货的读者,可以直接移步文末总结部分。
相关论文:
-
PPT: Pre-trained Prompt Tuning for Few-shot Learning https://arxiv.org/abs/2109.04332 -
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer https://arxiv.org/abs/2110.07904 -
On Transferability of Prompt Tuning for Natural Language Understanding https://arxiv.org/abs/2111.06719
PPT: Pre-trained Prompt Tuning for Few-shot Learning
清华研究人员发现在Few-shot的场景下,即便使用非常大的预训练模型,相比于Model-tuning,Prompt-tuning的表现仍要差得多。受预训练模型的启发,他们想对prompts也进行预训练!他们关注的是分类任务,并把分类任务分成了三类:单句分类任务、句对分类任务和多项选择分类任务。之后,他们针对每一类都设计了一个自监督预训练任务,然后用预训练任务的prompts去初始化下游任务的prompts。此外,他们还提供了一个unified的版本,将所有的分类任务都看作是多项选择分类任务。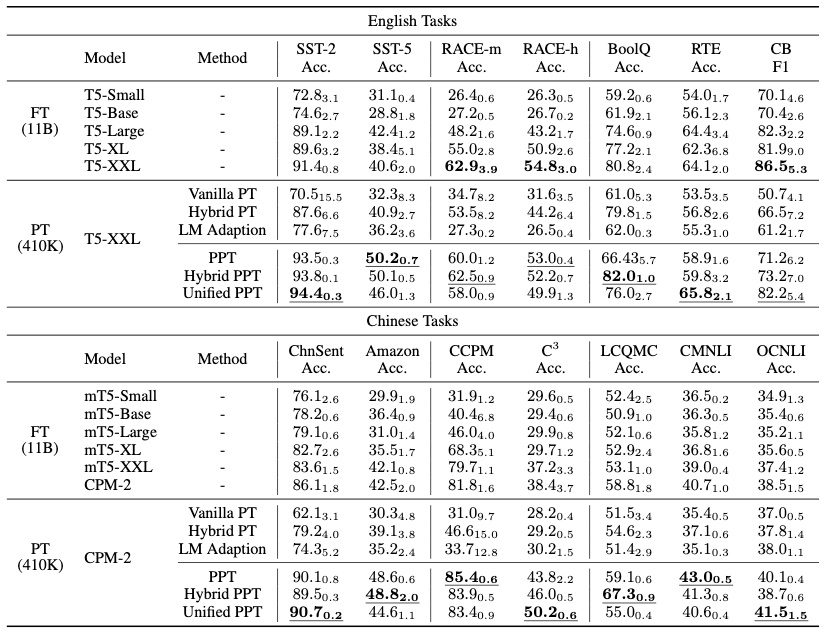
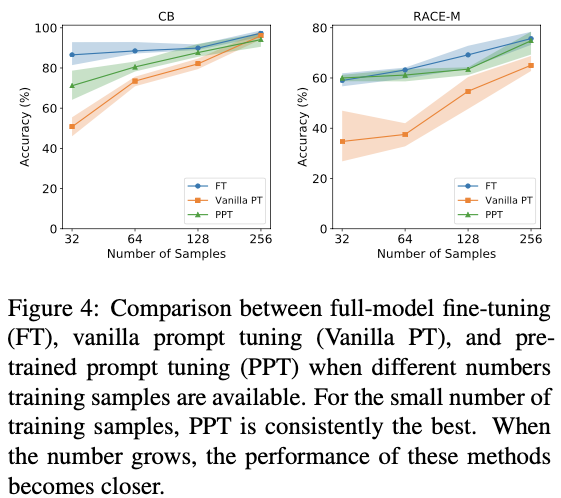
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
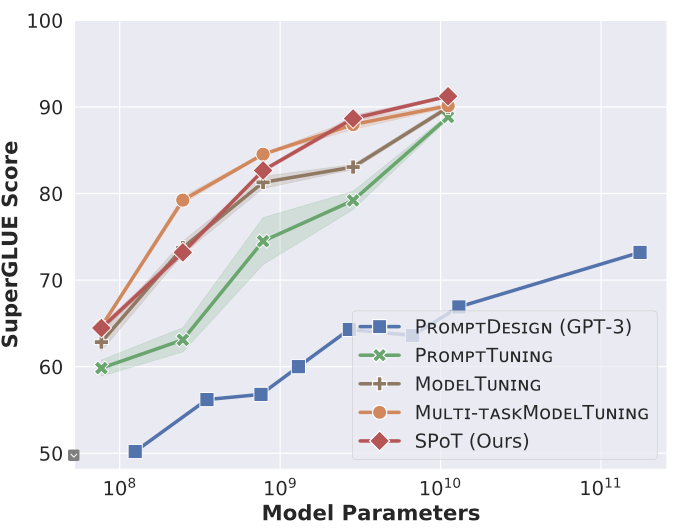
不同于PPT需要人工设计预训练任务,SPOT用一个或多个源任务训练的prompts来初始化目标任务的prompts。SPOT在预训练模型比较小时,仍可以达到与Model-tuning相近的性能,显著超越Prompt-tuning, 见下图
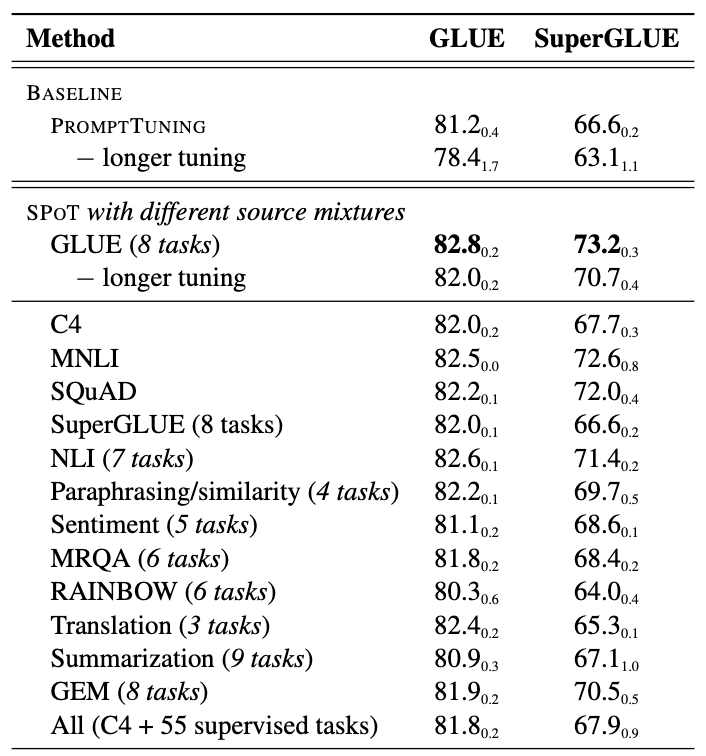
此外,SPOT关注的是full-data场景,研究人员发现即便当目标任务的数据充足时,选择合适的源任务训练的prompts仍能够对目标任务带来显著的增益。下图是用不同源任务的实验结果,多个任务是采用数据混合的方式进行训练,然后得到一个prompt。在GLUE的八个任务上训练的prompt在GLUE和SuperGLUE的多个下游任务上得到了最好的表现。值得关注的是使用单个任务如MNLI和SQUAD训练的prompt也带来了明显的提升。
为了探究源任务到目标任务的prompt可迁移性受什么因素影响,作者用16个源任务和10个目标任务构造了160个任务对。对于每一对任务,用源任务训练得到的prompt去初始化目标任务的prompt。他们发现任务之间的相似度是一个重要的影响因素。作者假设不同任务prompts之间的相似度可以反映任务之间的相似度。这样的话,给定一个目标任务就可以去检索相似的源任务,用这些源任务来帮助模型执行目标任务。有如下几种方式
-
Best of top-k: 依次使用top-k源任务的prompts去初始化目标任务的prompt,然后选择表现最好的那个 -
Top-k weighted average: 用top-k源任务的prompts的线性加权去初始化目标任务的prompt,权重就是各个任务与目标任务的prompts的相似度 -
Top-k multi-task mixture: 混合top-k源任务的数据进行训练得到一个prompt去初始化目标任务的prompt
几种不同策略的实验结果见下图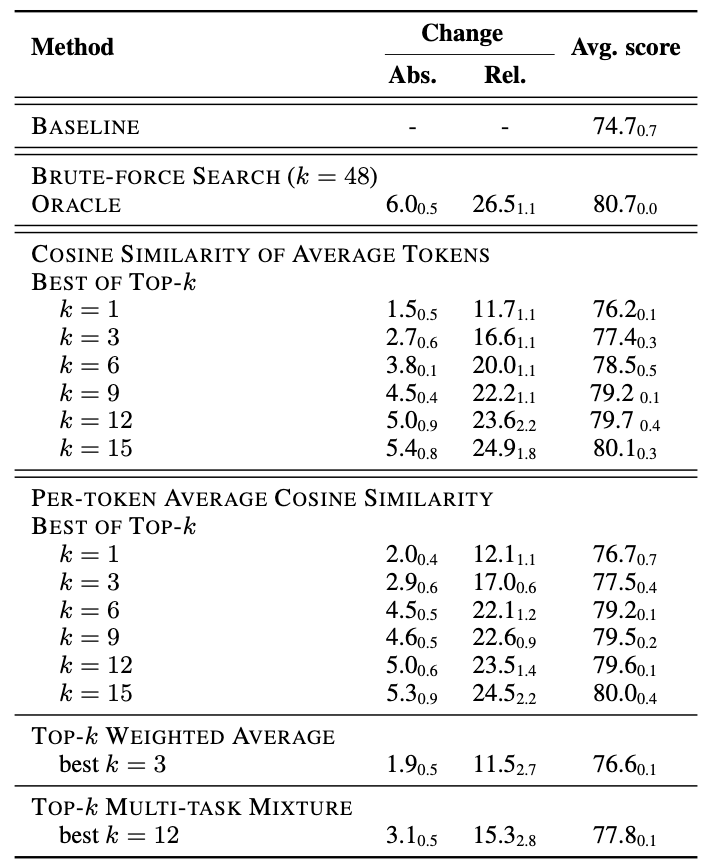
On Transferability of Prompt Tuning for Natural Language Understanding
相比于之前的两篇工作,这个工作定义了更多的衡量prompts之间的相似度的指标。作者还探究了prompts的zero-shot transfer的能力,即在源任务上训练的prompts直接用到目标任务上而不用目标任务的数据finetune,选择合适的源任务可以比使用随机prompts得到明显更好的表现,见下图
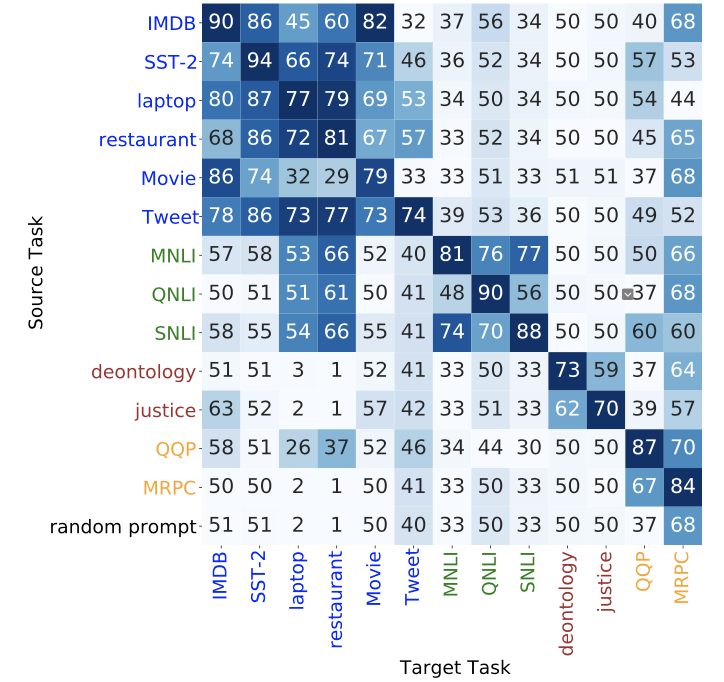
此外,使用合适的源任务,目标任务Propmt-tuning的收敛速度明显加快,见下图
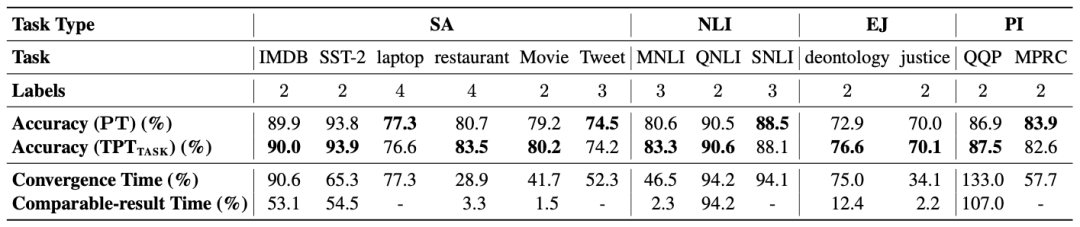
![]() 总结与展望
总结与展望![]()
 总结与展望
总结与展望基于之前三篇研究工作,我们可以得到如下结论:
-
好的初始化对Prompt-tuning十分重要,可以解决Prompt-tuning的三大问题。Prompt transfer是初始化目标任务prompts的一种非常有效的方式。 -
源任务与目标任务之间的相似度是迁移有效性的一个重要因素。可以利用任务的prompts之间的相似度来估计任务的相似度。值得注意的是,这些实验结果都只是显示了一种趋势, 更高的相似度并不能保证更好的迁移。 -
通过为多个源任务训练prompts可以得到一个prompts库,对于某个目标任务就可以检索一个或者是多个源任务的prompts去初始化目标任务的prompt。目标任务的prompt可以通过训练一定步数得到(不一定要等到收敛),检索可以通过prompts的相似度去进行排序,也可以通过源任务的prompts在目标任务上zero-shot transfer的表现去排序。如果使用多个源任务的prompts,有多种方式,例如逐个使用选最好或者是加权平均。更复杂的方式可能获得更好的性能。 -
PPT在目标任务训练数据较多时提升有限,而SPOT仍能有显著的提升。这可能是因为预训练任务与下游任务之间仍旧有显著的差距,更合适的源任务可能是更好的选择。
基于此,我们有如下展望:
-
如果可以将一个任务分解成多个子任务,那么 是否可以训练多个子任务的prompts然后用这些子任务的prompts去得到原任务的prompt?比如任务型对话系统有多个模块,并不是每个数据集都有所有模块的标注,通过这种方式就可以利用几乎所有现存的数据集,每个prompt只需要编码对应子任务的信息,然后将多个子任务的prompt组合起来就可以为原任务提供很好的初始化。 -
更进一步, 是否可以设计任务相关的prompts,综合考虑原任务与子任务的特点与联系,使得子任务上训练的prompt直接在原任务上复用? -
是否可以结合Prompt-tuning和Model-tuning在目标任务上得到更好的表现?结合第二点展望, 能否将此推广到多任务学习,多个任务之间设计相关的prompts然后一起训练?
笔者认为Prompt-tuning是一个十分有前景的技术,如何使其更加有效、适用更多场景还需要进一步探索。这就仰仗各位研究者(包括正在读文章的你)的努力啦~~
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. https://arxiv.org/abs/2107.13586
[2] https://mp.weixin.qq.com/s/2U6sk-LzYx4GtRitwEQnBw
[3] The Power of Scale for Parameter-Efficient Prompt Tuning. https://arxiv.org/abs/2104.08691
 后台回复关键词【
后台回复关键词【



