【浙江大学ICLR2022】可微分提示—一种更加高效的预训练少样本微调方法
转载“知乎Riroaki”
论文题目:Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
本文作者:张宁豫(浙江大学)、李泺秋(浙江大学)、陈想(浙江大学)、邓淑敏(浙江大学)、毕祯(浙江大学)、谭传奇(阿里巴巴)、黄非(阿里巴巴)、陈华钧(浙江大学)
接收期刊:ICLR2022
论文链接:https://arxiv.org/abs/2108.13161
代码:github.com/zjunlp/DART
一、从预训练微调到提示学习
在下游任务上微调大型预训练语言模型已成为 NLP 中事实上的学习范式。然而,传统方法微调预训练模型的所有参数,随着模型大小和任务数量的增长,这变得令人望而却步。最近的工作提出了多种参数高效的迁移学习方法,这些方法只需微调少量(额外)参数即可获得强大的性能。
这一类工作被称为提示学习(Prompt-based Learning),受到GPT-3[1]在少样本甚至零样本学习任务上的学习方式启发,采用任务相关的自然语言提示,通过标签映射将分类任务转换为填空任务。由PET[2,3]、LM-BFF[4]发展而来的提示学习方法,在语言理解任务上表现出优越的性能,在少样本场景上由于轻量化的微调过程而尤其高效。后续工作也在这一时期如雨后春笋般涌现,如清华大学提出的可自动学习模版的P-tuning[5]和预训练提示方法PPT[6],斯坦福大学提出的可学习前缀式提示学习方法Prefix-tuning[7],Huggingface提出的T0[8]多任务学习模型等等,本文工作也属于其中之一。
二、动机
提示学习通过引入任务相关的模版和标签映射,将一般的分类任务转换为和语言模型预训练过程中遮盖文本建模(Masked-Language Modeling)目标一致的形式,因而如何选取合适模版和标签映射就成为其核心。从PET的手工构建模版,到AutoPrompt和LM-BFF等工作基于梯度或者生成模型选取离散模版词,再到P-tuning引入外部架构并从任务中学习连续化模版词,可以看出提示学习的工作经历了从离散到连续、从手工到自动的演进过程,类似于人工智能领域从特征工程到深度学习的范式变化。有鉴于离散化模版词的非最优性,本文提出的DART(DifferentiAble pRompT)方法采用了一种简单的构造方式,可以在任务中同时学习连续化的模版和标签映射。
三、可微分提示学习方法:DART
具体而言,本文提出的方法使用一类特殊的非语义词元作为模版和标签映射词,并在训练过程对这些词元的表示进行优化:

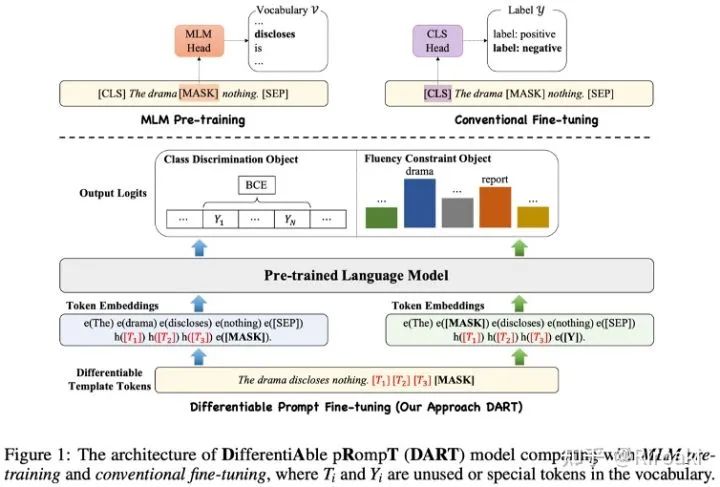
在训练过程中,首先对分类目标进行训练: 


DART和先前主要的提示学习工作简要对比异同如下:

四、实验分析
本文列出了DART模型在15个NLP数据集上的表现,包括情感分析、自然语言推理、释义、句子相似度、关系抽取和事件抽取的多种任务,其中涵盖主流的句子分类数据集如SST-2、MR、CR、Subj、TREC、MNLI、QNLI、MRPC和QQP等,以及多种关系/事件抽取数据集如SemEval 2010、TACRED-Revisit、Wiki80、Chemprot、ACE2005等,并与现有工作进行了对比。以下表格列出了主要的实验结果,具体的实验结果和分析可以参见论文。
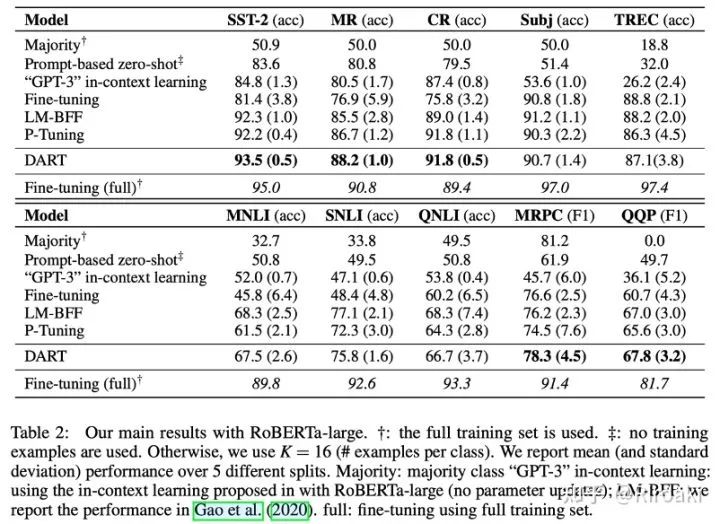
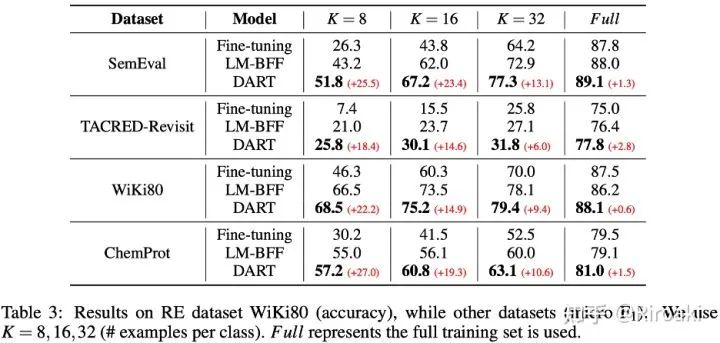
五、小结与展望
本文介绍了DART,一种简单而有效的微调方法,可改进快速学习预训练的语言模型。与传统的微调方法相比,DART可以在少样本场景中产生一定的提升,并对其他语言模型是可拓展的,并且可以扩展到其他任务。本文的实验结果将有助于社区在少样本学习领域和终身学习领域的发展。
参考文献
[1] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[2] Schick T, Schütze H. It's not just size that matters: Small language models are also few-shot learners[J]. arXiv preprint arXiv:2009.07118, 2020.
[3] Schick T, Schütze H. Exploiting cloze questions for few shot text classification and natural language inference[J]. arXiv preprint arXiv:2001.07676, 2020.
[4] Gao T, Fisch A, Chen D. Making pre-trained language models better few-shot learners[J]. arXiv preprint arXiv:2012.15723, 2020.
[5] Liu X, Zheng Y, Du Z, et al. GPT understands, too[J]. arXiv preprint arXiv:2103.10385, 2021.
[6] Gu Y, Han X, Liu Z, et al. Ppt: Pre-trained prompt tuning for few-shot learning[J]. arXiv preprint arXiv:2109.04332, 2021.
[7] Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
[8] Sanh V, Webson A, Raffel C, et al. Multitask prompted training enables zero-shot task generalization[J]. arXiv preprint arXiv:2110.08207, 2021.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DART” 就可以获取《【浙江大学ICLR2022】可微分提示—一种更加高效的预训练少样本微调方法》专知下载链接





