

论文题目:Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions
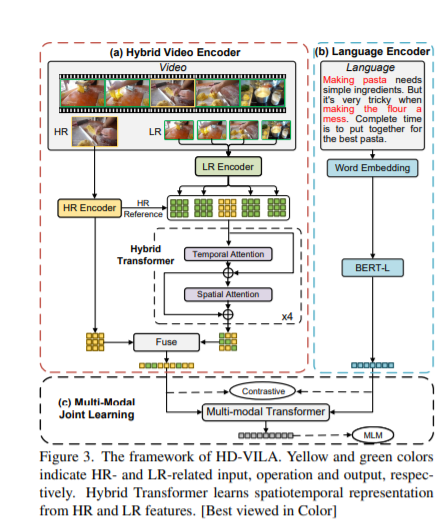
作者:薛宏伟*,杭天恺*,曾艳红*,孙宇冲*,刘蓓,杨欢,傅建龙,郭百宁 论文概述:我们研究了视频和语言(VL)的联合预训练,以实现跨模态学习并使大量的下游VL任务受益。现有的研究要么是提取低质量的视频特征,要么是学习有限的文本嵌入,而忽略了高分辨率的视频和多样化的语义可以显著增强跨模态学习。在本文中,我们提出了一个新颖的高分辨率和多样化的视频-文本预训练模型(HD-VILA),用于许多视觉任务。我们收集了一个具有两个特性的大型数据集:(1)高分辨率,包括371.5K小时的720p视频,以及(2)多样化,涵盖15个流行的YouTube类别。为了实现VL预训练,我们通过一个混合Transformer和一个多模态Transformer来共同优化HD-VILA模型,前者学习丰富的时空特征,后者进行视频特征与多样化文本的交互。我们的预训练模型在10个VL理解任务和2个文本到视觉的生成任务中取得了最先进的结果。例如,我们在zero-shot MSR-VTT文本到视频检索任务中超越了SOTA模型,相对增加了38.5%R@1,在高分辨率数据集LSMDC中增加了53.6%。学习到的VL嵌入在文本到视觉编辑和超分辨率任务中也能有效地产生视觉效果好、语义上的相关结果。
https://www.zhuanzhi.ai/paper/4687f398dbfa67383a70e3a0cc496620
成为VIP会员查看完整内容
相关内容

专知会员服务
27+阅读 · 2022年3月3日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
15+阅读 · 2020年5月13日
Arxiv
17+阅读 · 2018年3月20日


相关VIP内容
专知会员服务
27+阅读 · 2022年3月3日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月15日
Arxiv
15+阅读 · 2020年5月13日
Arxiv
17+阅读 · 2018年3月20日