百度翻译十年:语种全球首破200大关,质量提升30个百分点,每天翻译超千亿字符
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
十年,能让一个机器翻译系统发生怎样的变化?
2011年,TA还只会“中-英”翻译这一项技能。但TA却用十年时间,在翻译这条路上不断打磨自己。
现如今,TA的“打开方式”的是这样:
全球首个发布互联网神经翻译系统,10年内让翻译质量提升30个百分点(国际常用的评价指标BLEU),而通常提升1个百分点就是非常显著的了。
全球首次突破200种语言的互译,10年内让翻译语种数量增长100倍。
不再是只会文本翻译这一项技能,而是掌握了图片、视频、文档,甚至是同传这样的跨模态翻译。
也不再限于在输入框中输入文本来翻译,而是翻译APP、AI同传会议版、同传助手、小程序以及翻译开放平台等多种产品。
而且现在的它还变得格外忙碌,全世界每天找TA翻译的字符量超过千亿,相当于2000部大英百科全书,是10年前的10万倍。
甚至Gartner对它还做出了这样的评价:
是神经网络机器翻译标杆机构,也是国内唯一入围单位。
是全球AI翻译服务中的重要力量。
……
TA,就是百度翻译。

但如果现在你还认为它只是个搞翻译的,那可能就有点片面了。
因为现在的百度翻译,有点“变味”了。
10岁的百度翻译,长什么样?
如果说百度翻译的起点,是十年前那个只会中英翻译的网站。
那么现在的它,可谓是把翻译这事玩出了一种新高度。
首先在翻译语种这件事,也正如刚才提到的,百度翻译全世界范围内首个突破200种语言互译的系统。
而且不只是翻译语种数量多的问题,更是在翻译难度上有所体现。
例如它甚至在涉猎一些“冷门”的语言,以国粹文言文为例,输入一段《学弈》的文字:
弈秋,通国之善弈者也。使弈秋诲二人弈,其一人专心致志,惟弈秋之为听;一人虽听之,一心以为有鸿鹄将至,思援弓缴而射之。虽与之俱学,弗若之矣。为是其智弗若与?曰:非然也。
啪的一下,百度翻译瞬间就能把晦涩难懂的古文,用大白话的形式展现出来:

然而机器能做到这一点,也相当不容易,因为除去大语种,大部分语言的互译资源是稀缺的,无法供AI学习足够多的知识。
但百度翻译所满足的可不止于对文本翻译的“多”和“精”,它还花了十年时间在便捷性这块下足了功夫。
这不就在最近,百度翻译App更新迭代到了10.0版本,“花式翻译”也在这里得到了很好的体现。
不再是把文字输进去、翻出来这样单一的套路,而是把语音、图片、视频、文档等形式也融入了进来。
换言之,现在想要做翻译,不再是输入文本这种单一的形式了。
说一句话、拍一张照,甚至直接把完整的文档导进来,就可以完成翻译了。
不仅如此,甚至像同传这样高段位的翻译,百度翻译也是能够轻松hold住。
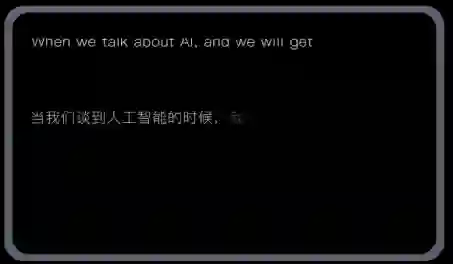
百度翻译更是在全球顶级机器翻译比赛WMT (Workshop on Machine Translation)中,拿下过中英翻译第一名的成绩。
不难看出,百度翻译花了十年时间,不只是在做横向的扩展,也是对各个产品在纵向上“自修功法”。Big Family目前已经枝繁叶茂。
那么百度翻译,是如何通过十年时间进阶到如此的呢?
百度翻译进化之路
我们不妨先来简单回顾一下机器翻译的发展。
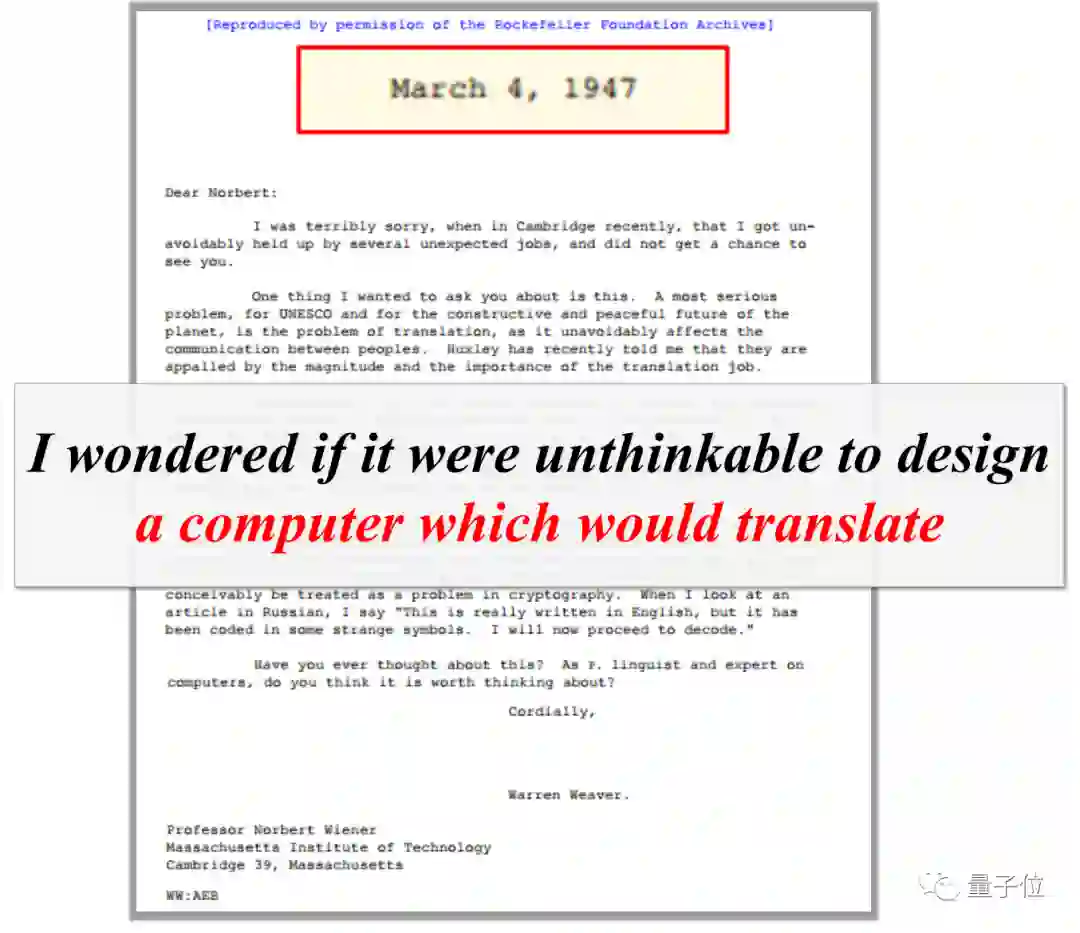
“机器翻译”这件事,早在1946年第一台计算机ENIAC诞生之后的一年,便由信息论先驱、美国科学家Warren Weaver提出:
而至此之后,机器翻译先是进入到了“基于规则方法”的时代。
这个方法本质上将专家的翻译知识采用规则形式写下来,然后采用软件的方式利用翻译规则来实现机器翻译过程。
但这种方法的缺点也是显而易见,那就是构建成本、维护成本过高,动辄还要将整个程序重写。
而到了上世纪80年代末90年代初,IBM提出了另一种机器翻译的方式——统计机器翻译,这便开启了机器翻译时代的第二个大门。
与基于规则的机器翻译不同,统计机器翻译不再需要从人工书写翻译规则,而是转换到了数据驱动的机器学习方法。
最大的优点在于机器可以按照人工定义的特征进行“自学”,而之前的基于规则方法,需要人类专家手把手的。
百度翻译上线之初,主要用的就是基于统计机器翻译的方法,同时研发了融合已有方法的多策略模型,以便应对互联网上复杂多样的翻译请求。
2010年百度翻译自建了研发团队,仅时隔一年,便上线了网页版。
但此时统计机器翻译已经诞生了20多年时间,其发展的瓶颈也是越发明显——在经历了基于短语的方法、基于句法的方法等一系列技术迭代之后,统计机器翻译逐渐遇到天花板,翻译质量难以进一步提升,尤其在长距离调序、译文流畅度方面。
即便摸石头过河,也要身先士卒
到了2013年,一篇名为《Recurrent Continuous Translation Models》的研究横空出世。
而伴随着研究人员们所提出的新方法,机器翻译也就步入到了神经机器翻译 (NMT)时代。
虽然这种神经网络的方法确实是一种理想的“替代品”,但非常现实的问题也摆在百度翻译团队的面前。
那就是“无从参考”,建模的方式完全是新的,没有经验可循。
再则以当时的技术水平,通过神经网络模型来做机器翻译还是一件非常“伤资源”的事。
翻译效果提升的代价,就是消耗大量的计算资源,往往翻译一个句子就得花个十几秒的时间。
时间拉到2015年,即便是在这种大背景的情况下,百度翻译团队依旧做了一个“敢为人先”的决定:
上线基于神经网络的机器翻译。

在技术方法上,百度翻译团队针对NMT所存在的缺点,将上一代统计机器翻译的特性融入了进来。
具体而言,就是将n-gram语言模型、短语表特征、长度特征等,融合到NMT模型中。
实验结果表明,这种“新旧结合”的方法,显著提升了NMT在中英互译方面翻译的性能。
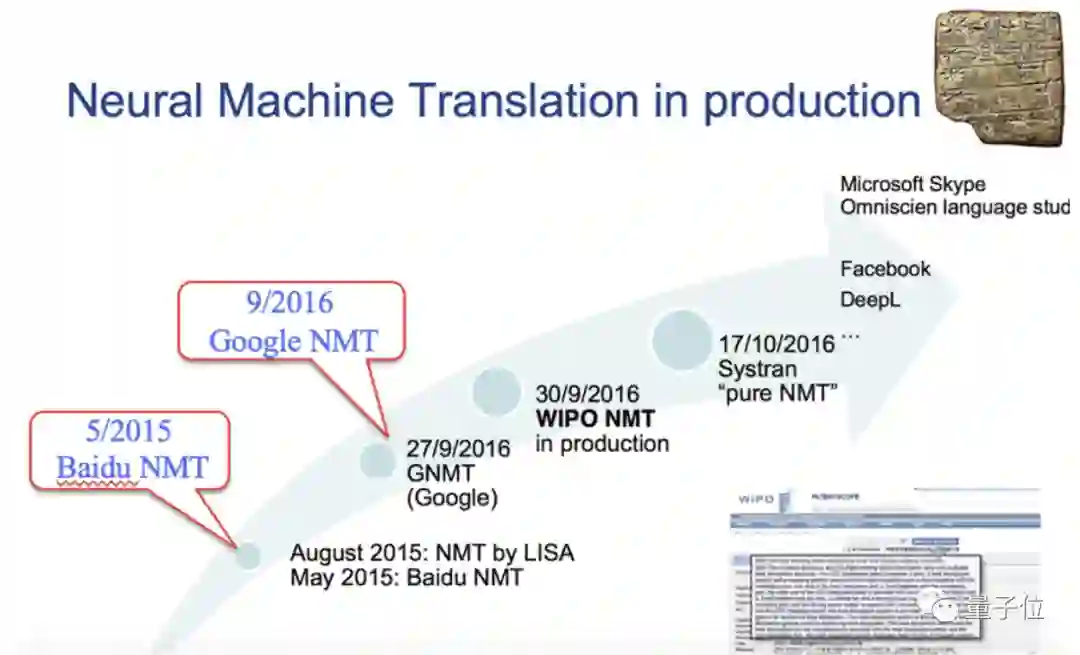
而从立项到发布全球首个互联网神经网络机器翻译系统,百度翻译仅仅花了不到半年的时间。
这个节奏要比谷歌翻译提早了整整16个月的时间。
然而百度翻译却并不满足于此。
△ Bruno Pouliquen,世界知识产权组织机器翻译负责人,MTSUMMIT-2017
还要做更多方向上的“领头羊”
为了能够进一步翻译出更多的语言,百度翻译还提出了《Multi-Task Learning for Multiple Language Translation》。

在这项研究中,百度翻译提出了共享编码器的多任务学习神经网络翻译模型,建立了基于神经网络的多语言翻译统一框架。
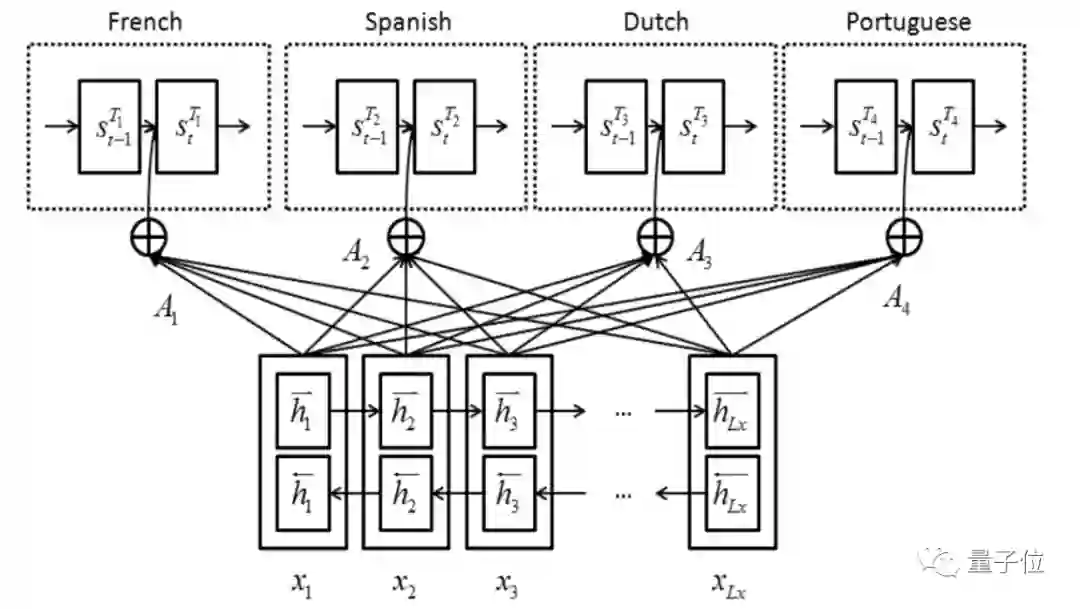
△ 基于共享编码器的翻译模型图
这也是百度翻译现在能够hold住203种语言互译的关键所在。
到了2017年,百度翻译又惊艳地亮出了AI同传功能。
具体而言,是提出了语义单元驱动的机器同声传译模型,解决了翻译质量和同传时延难以兼顾的难题。
与此同时,百度翻译团队还研发了高质量、低时延的机器同传系统,翻译准确率超过80%,平均时间延迟3秒。
也正是因为百度在机器翻译这件事上技术处于领先地位,翻译准确度又高。
所以许多国际性的会议、活动,都陆陆续续选择百度翻译作为技术支持。百度翻译的AI同传,更是挺进了服贸会、进博会这样的重要活动。
……
那么随之而来的一个问题便是:
百度为什么要如此发力翻译这件事?
翻译,不仅仅是工具那么简单
首先,需要明确且达成共识的一点是,机器翻译是人工智能终极目标之一,也是AI技术最具挑战的应用之一。
这也就是百度在机器翻译领域不断创新的原因所在。
但从另一个角度来看,百度翻译要做的事情,从来就不是翻译本身这么简单。
而从它十年的发展历程来看,现在的百度翻译已经“变味”了:
不仅仅是个工具,更是桥梁、窗口和世界文化的感受器。
这又该如何理解?
我们不妨从百度翻译带来了什么,来理解它的“变味”。
TA是用户身边的翻译助手
例如在交警执法的过程中,就曾遇到过外国(俄罗斯)友人的这种情况。
由于他们不会中文,沟通就成了老大难的问题。

最终,交警通过百度翻译的能力,成功地救助了外籍船员。
再如工作中,语言的障碍成为了信息获取与沟通交流的阻碍。

而用户通过使用百度翻译的软件,让跨语言交流这件事变得更加丝滑。
但这样的服务和体验,应当是所有人都该拥有的体验,哪怕是残障人士也应如此。
为此,百度翻译还帮助视力障碍的开发者开发盲人操作软件,免费帮助大量盲人用户获取翻译服务。
也正是这样一件又一件的真实故事,让百度翻译不再是只是翻译工具这么简单,更是赋予了诸如桥梁、窗口和感受器等这样的含义。
TA助力全球抗击疫情
但讲真,比起体验上的这层“变味”,百度翻译还逐渐发挥着更具深层宏大的使命和价值。
例如在抗疫这件事上,百度翻译也在发挥着它的热量。
法语的3M口罩说明书、英语的防护服说明书、俄语的三层口罩商检证书……这些抗疫物资等等,无不需要翻译的工作。
但众所周知,抗疫这件事不仅任务量重,更是在与时间赛跑。
百度翻译便扛起了抗疫期间翻译工作的重担,仅仅在2天时间内便搭建出了高效易用的定制化翻译工具,而且火速向志愿者团队免费开放。

△ 多语言防疫视频
TA服务国家需求,为跨语言交流铺路
而且百度翻译做的事,还是符合国家需求的那种。
国家在第二届“一带一路”国际合作峰会论坛中便提出:
共建“一带一路”,关键是互联互通。我们应该构建全球互联互通伙伴关系,实现共同发展繁荣。
而跨语言交流,就成为了实现这一目标的关键所在。
百度翻译便在十年时间里,在翻译语种增长100倍的情况下,沿着“一带一路”沿线国家,将跨语言翻译逐步铺展开来。
不难看出,这也是应了国家乃至全球发展的互联互通大趋势。
而放眼当下,百度翻译还在“变味”着,要将翻译这件事转变为一种生产力。
但毕竟翻译这件事可谓是任重而道远,即便是拿下诸多“全球首次”的百度翻译也还有很长的一段路要走。
至于在接下里的时间里,百度翻译又将在技术和价值上带来怎样的提升,我们拭目以待。
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



