在CVPR上,OPPO的一系列「业界首次」
作者:泽南
下个爆款应用,可能就来自于这些研究。
用 AI 重建真实环境的 3D 数字模型,是虚拟现实、游戏环境渲染等任务的重要环节。通常人们必须依赖红外传感器、ToF 等特殊设备才能获得精确的图像,处理数据也需要消耗巨大的算力时间,因此,它经常会成为构建应用的瓶颈。
最近,有人展示了全新的技术:只需要一个平板电脑的算力,我们就可以用普通摄像头实时描绘一个房间的复杂实景,同时 AI 算法可以自动标记所有物体并将其正确分类。
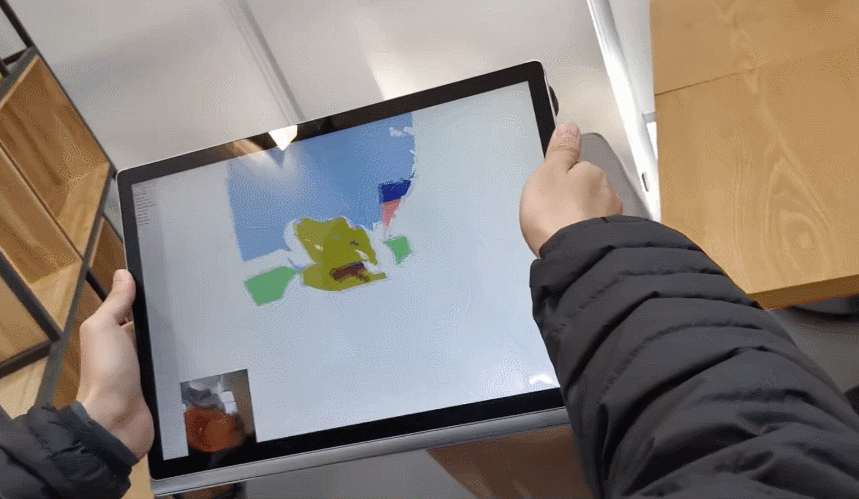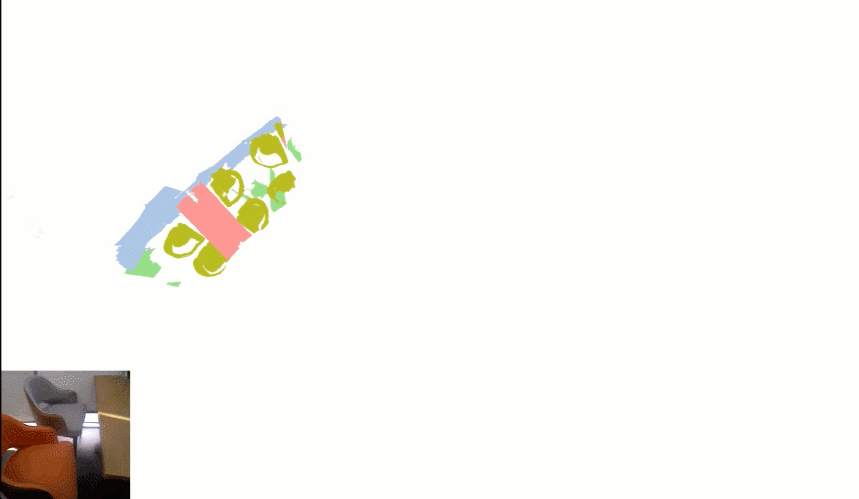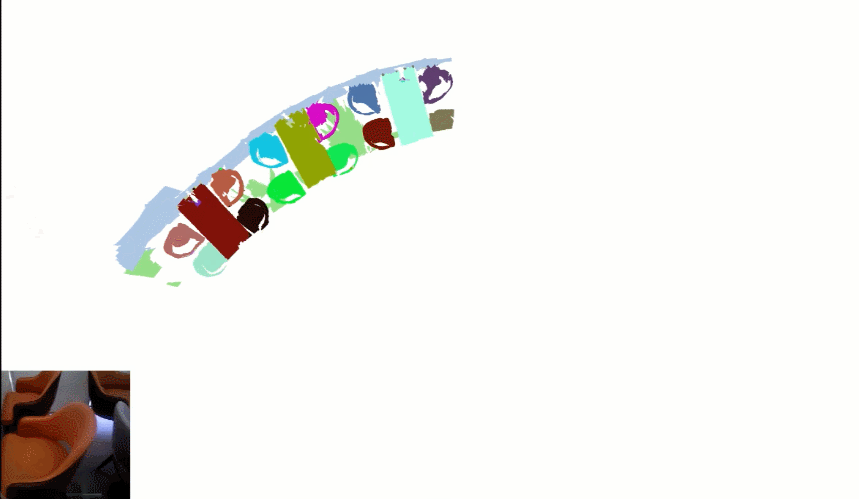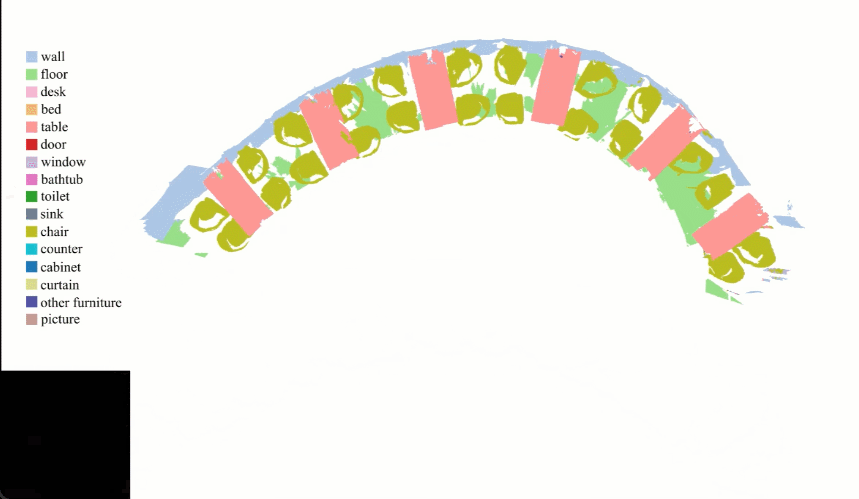
更进一步,如果扫描的视角转了完整的 360 度,算法就可以自动重建出房间的模型:

这项技术出自 OPPO 研究院联合清华大学提出的 INS-Conv (INcremental Sparse Convolution),其算法可以更快更准确地实现在线 3D 点云语义及实例分割推断,有效降低了环境识别对于终端算力的要求。
INS-Conv 的论文在刚刚结束的人工智能顶会 CVPR 2022 上入选了口头演讲(Oral)环节。
一块平板,实时构建 3D 模型
图像分割是 AI 领域的重要技术,许多计算机视觉任务,如机器人、AR/VR 应用中,人们都需要对图像进行智能分割,以充分理解周围环境,实例分割旨在让 AI 识别出 3D 场景中的物体,对于每个像素点都需要进行语义预测。
最近一段时间,专注于离线 3D 分割的方法在精度方面实现了很多进步,这些方法已有较高准确性,但识别的速度可能需要几秒钟一帧——其骨干网络通常需要全局几何作为输入,无法满足实时应用的需求。

图像语义分割是像素级预测的一种形式,目标图像中的每个像素都会被算法进行分类。
对于实时在线的 3D 分割任务,人们常见的解决方案则是 2D-to-3D 方法,这意味着需要对 RGBD 图像(色彩加深度)执行 2D 卷积,然后将 2D 预测投影到 3D 空间,用概率模型与之前的结果发生融合。这些方法仅能利用二维信息,分割精度较低。
此外,大多数在线 3D 分割方法只区分物体种类,不区分不同物体。如何在实现在线推理和 3D 重建的同时实现高度准确的 3D 语义实例分割仍然是一个悬而未决的问题。
在 INS-Conv 研究中,研究人员提出的增量稀疏卷积网络可以实现实时且准确的 3D 语义和实例分割。

INS-Conv 的语义分割管道。核心是 INS-Conv 骨干网络,用于对一系列逐渐变化的输入几何的残差进行增量特征提取。之后,聚类阶段和融合阶段生成时间一致的语义和实例分割结果。
新方法会为每个时间步的重建场景形成一个递增的 3D 几何序列,通过对连续帧的残差进行增量推理,这种方式节省了大量冗余计算。更具体地说,在神经网络层设计中,新方法为稀疏卷积操作定义了全新的残差传播规则,用 INS-Conv 层替换标准稀疏卷积网络层,就能以最小的精度损失实现高效的增量推理。
基于 INS-Conv 的实时 3D 语义和实例分割系统,研究人员在每个时间步上通过主干网络提取 3D 特征后使用聚类生成对更新点的实例预测,然后将其融合到之前的结果中,使用实例融合得到最终的实例分割结果阶段,最终实现了业内最优的分割精度。
在实践中,研究人员提出的在线联合 3D 语义和实例分割算法在 GPU 上可达到 15 FPS,在 CPU 上也达到了每秒 10 帧的推理速度。多个数据集上的实验表明,新方法准确性大大超过了此前人们提出的在线方法,且与最先进的离线方法水平相当。
从便携式设备上本地运行的 Demo 效果来看,INS-Conv 在准确性和效率方面的领先性能使其特别适用于 AR/VR 或机器人应用,为自动驾驶、虚拟现实等前沿技术的落地提供了高效率、低成本的新方法。
或许不久以后,无人驾驶车辆和机器人就可以摆脱雷达只用摄像头,人们的手机上还会出现可以给自己房间建模的 APP。
把 AI 审美水平提高一个台阶
3D 建模技术可以让很多技术变得更加便利,OPPO 研究员还在思考脑洞更大的事:在 CVPR 上,OPPO 的一篇论文介绍了如何用深度学习来捕捉不同人的审美偏好。
随着 AI 图像识别能力的逐渐成熟,让 AI 具备审美能力成了人们追逐的新目标之一。从数据视角来看,AI 审美能力往往与训练所使用的数据和标注者的审美偏好关联较大,但人的审美往往是各不相同的。使用基于大数据的美学评价来为不同用户服务,可能会引发人们对于「审美歧视」的讨论,或带来不尽如人意的用户体验。
在论文《Personalized Image Aesthetics Assessment with Rich Attributes》中,OPPO 研究院联合西安电子科技大学李雷达教授,开创性地提出了带条件的 PIAA 算法,首次从「用户主观偏好与图像美学相互作用,如何产生个性化品味」的角度出发,提出了个性化美学评价新方法。

一般地,图像美学评估算法可分为两类:通用和个性化图像美学评估(GIAA 和 PIAA)。对于 GIAA,图像通常由多位标注员进行注释;在建模时,通常使用平均意见分数 (MOS) 或美学注释分数分布作为美学的「基本事实」。然而,GIAA 反映的是审美的「平均意见」,忽略了审美品味的高度主观性。为了缓解这个问题,人们提出了 PIAA 方法,可以捕捉不同人的独特审美偏好。
不同的审美习惯往往与不同的用户画像和审美经验相关。在提出的方法中,研究人员在建模审美偏好时,额外引入了三种条件信息,包括个人性格、美学经验以及摄影经验。实验结果显示:利用被试的属性信息进行 PIAA 建模,可以提高模型性能。
除上述提出的算法外,在参考已有美学评价主流数据集的基础上,来自 OPPO 和西电的研究员们进行了迄今为止最全面的个性化图像美学评价主观实验,构建了一个具有丰富注释的个性化美学评价数据库 “PARA“并将其开源。数据集包含 31220 张图像,每张图平均由 25 个人类受试者进行注释,标注了 4 个面向人的主观属性(内容偏好、分享意愿等)和 9 个面向图像的客观属性(图像美学、情感等)。
研究员对数据集进行了基准模型研究。包括有条件和无条件的 PIAA 两种建模方法,训练方式如下图所示:
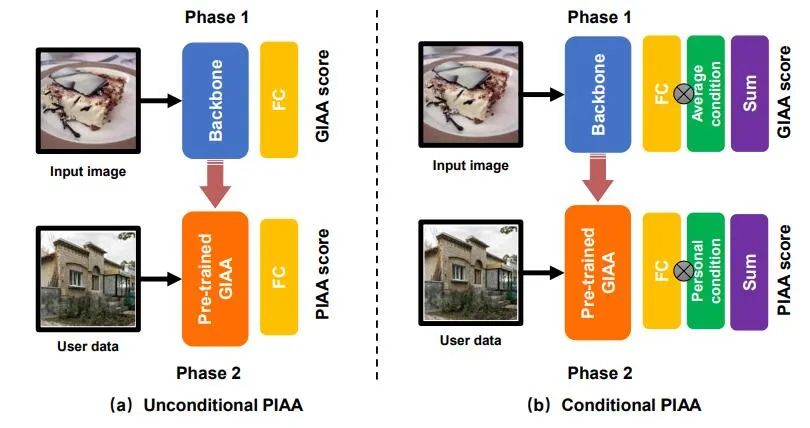
相比通用美学评价模型(GIAA),本文中的个性化美学评价算法使用个人数据进行了微调,旨在学习个性化审美偏好。相比无条件的 PIAA 模型,条件 PIAA 建模时分别添加了三种条件信息,包括个体性格、美学经验和摄影经验。
在实验方面,研究员们参考 Few-shot Learning 及相关个性化美学评价工作基准设置方法,进行了三组基准实验测试:
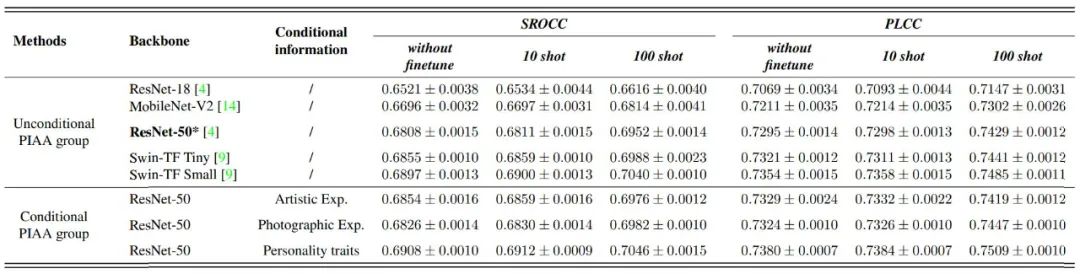
实验结果显示,通过对个性化数据进行微调,更多的个性化训练数据可以进一步提高微调的性能;同时,引入用户画像作为个性化美学评估的条件信息,可以帮助模型进一步挖掘不同人的审美偏好。
OPPO 研究者表示,在未来,希望个性化美学评价算法能够更好地适配用户的审美习惯,为用户在相册、相机、互联网内容推荐等场景中打造更加个性化的,良好的产品使用体验。
在多个 AI 研究方向取得突破
作为计算机视觉世界三大顶会之一,CVPR 每年都会吸引大量研究机构和高校专家、学者参会。随着人工智能的火热,近年来 CVPR 的论文投稿量正在不断增加。据官方消息,本届大会获得了 8100 余篇论文投稿,其中 2067 篇论文被接收,接收率约为 25%,其中 Oral 的数量为 342 篇。
纵观整个科研圈,CVPR 的地位也在变得越来越重要。根据谷歌学术公布的 2021 年最新学术期刊和会议影响力排名,CVPR 位居第四,仅次于 Nature、新英格兰医学杂志和 Science,是影响力最高的 AI 研究会议。每年在 CVPR 上的重要研究,都会成为近期人工智能领域技术发展和落地的新方向。
今年的 CVPR 2022 上,OPPO 研究院共有 7 篇论文获得收录,内容受到人们的关注。除了上述研究之外,其最新研究还覆盖多视图动作检测、人体姿态估计、三维人体重建、知识蒸馏等领域。
在三维人体重建领域中,OPPO 研究院通过改进 NeRF 创新的动态角色建模方法,在业界首次实现了自动为宽松着装人体创建数字分身的工作。该建模方法仅通过分析摄像头所拍摄的 RGB 视频,就可以 1:1 精准还原人物动态细节,甚至包括衣服细小 logo 或纹理细节。
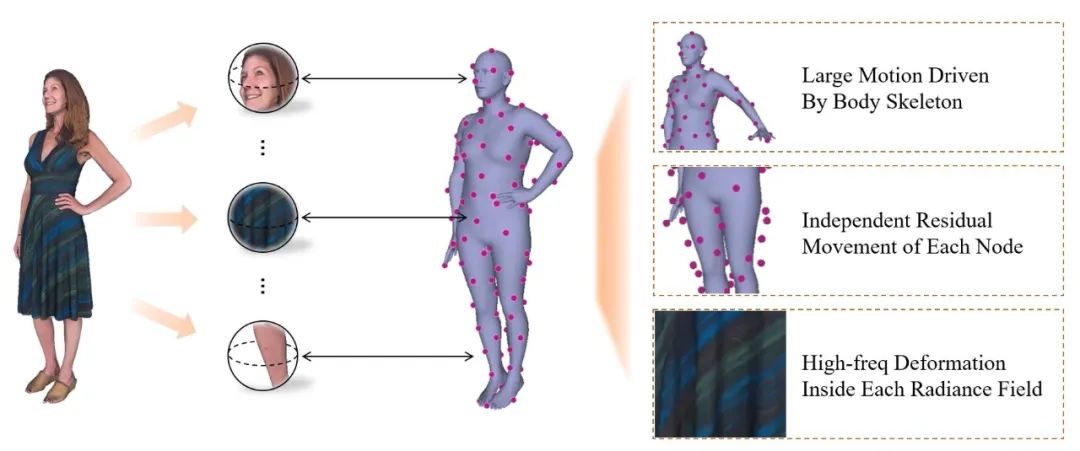
这项研究可有效降低三维人体重建的门槛,为在线虚拟试装购物、AI 健身和 VR/AR 应用的真正落地提供技术基础。
在《CRIS: CLIP-Driven Referring Image Segmentation》中,研究人员提出了端到端图像分割框架 CRIS,借助视觉语言解码和对比学习来实现文本到像素的对齐,在三个基准数据集的实验中显著优于此前的 SOTA 研究。
论文《Single-Stage is Enough: Multi-Person Absolute 3D Pose Estimation》则将单阶段方案扩展到了 3D 人体姿态估计任务中。解决了当前多人三维姿态估计过程中存在的计算问题。
知识蒸馏作为一种强大的正则化策略,广泛应用于模型压缩、知识迁移和模型增强领域。在《 Self-Distillation from the Last Mini-Batch for Consistency Regularization 》中,研究人员提出了一种简单高效的自蒸馏框架,其易于实现且计算复杂度低,在多个基准数据集上超过了业界最先进的自蒸馏方法。
OPPO 的 CVPR 研究还涉及自动驾驶领域:在论文《MV-TAL: Mulit-view Temporal Action Localization in Naturalistic Driving》中,OPPO 提出了一种基于 Swin Transformer 的灰度视频的多视图时间动作定位系统,实现了高效的驾驶动作识别。
从这些论文的方向看,OPPO 在人工智能的多个不同方向上都已有了深度且有领先性的研究。除此之外,在 CVPR WAD Argoverse2 比赛的运动预测任务中 OPPO 还提出一种关注地图 boundary 信息的运动预测网络,取得了第一的优异成绩,该项研究能够为自动驾驶提供更多的安全舒适保障。
2020 年初,OPPO 研究院正式成立智能感知与交互研究部。在当年的 CVPR 上,OPPO 获得了大会学术竞赛的两项第一,两项第三。去年,OPPO 在六大赛道中十二赛项中取得了一项第一、七项第二、四项第三的成绩,再次展示了强劲的 AI 创新实力。
今年,OPPO 在 CVPR 2022 上实现了单届七篇主会论文入选,挑战赛三项第一、一项第二、四项第三的好成绩。OPPO 投入前沿科技研发的力度正在加大,其提出的新技术面向应用,已不断投入实践。
投入技术研发创造众多「业内首次」的同时,OPPO 产品中的黑科技也越来越多,绿厂自研芯片马里亚纳 X,是全球首个为影像而生的专用 NPU 芯片,其面向 OPPO 自研 AI 算法,实现了最高效的计算加速和功耗优化。目前已实现在 Find X5、Reno8 系列产品上的落地,提升产品差异化与竞争力。
在 AR 领域,OPPO 提出了全时空间计算 AR 应用 CybeReal,利用空间计算、融合定位实现了多类硬件设备在物理环境中的厘米级定位。
而去年底 OPPO 发布的智能眼镜 Air Glass 更是新技术的集大成者,其 AR 辅助现实功能可以实现「演讲题词、通知提醒、骑行导航、实时翻译」等一系列功能。其中涉及的技术,包括语音识别、自然语言理解和计算机视觉,人工智能几大方向一个不少。

随着技术的不断进化,我们或许很快就会看到更多新近登上 AI 顶会的论文,变成 OPPO 智能设备中的新能力。
参考内容:
https://arxiv.org/abs/2203.16754
https://arxiv.org/abs/2111.15174
https://arxiv.org/abs/2203.16172
https://arxiv.org/abs/2203.14478
https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_INS-Conv_Incremental_Sparse_Convolution_for_Online_3D_Segmentation_CVPR_2022_paper.pdf
https://openaccess.thecvf.com/content/CVPR2022W/AICity/papers/Li_MV-TAL_Mulit-View_Temporal_Action_Localization_in_Naturalistic_Driving_CVPRW_2022_paper.pdf
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

