近期必读的六篇计算机视觉顶会ECCV 2020【目标检测】相关论文
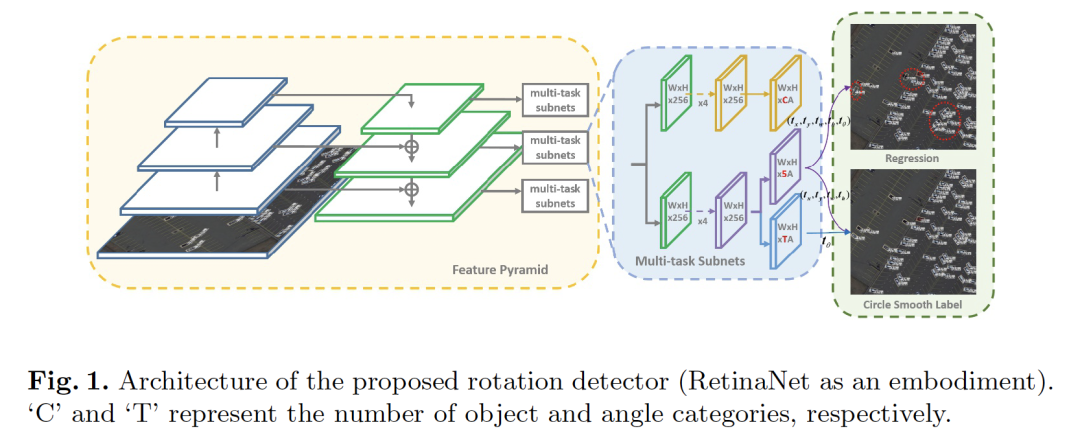
1. Arbitrary-Oriented Object Detection with Circular Smooth Label
作者:Xue Yang, Junchi Yan
摘要:近年来,面向任意方向的目标检测(Arbitrary-oriented object detection)由于其在航空图像、场景文字、人脸等领域的重要作用,在视觉领域引起了越来越多的关注。本文指出,由于角度周期性或角度的顺序问题,现有的基于回归的旋转检测器存在边界不连续的问题。通过仔细的研究,我们发现根本原因是理想的预测超出了定义的范围。我们设计了一种新的旋转检测基线,通过将角度预测从回归问题转化为精度损失很小的分类任务来解决边界问题,从而与以往使用粗粒度进行旋转检测的工作不同,我们设计了一个高精度的角度分类。我们还提出了一种环形平滑标签(CSL)技术来处理角度的周期性,并提高了对相邻角度的容错性。在此基础上,我们进一步介绍了CSL中的四种窗函数,并探讨了不同窗半径大小对检测性能的影响。在DOTA、HRSC2016这两个大规模航空图像公共数据集以及场景文字数据集ICDAR2015和MLT上的大量实验和可视化分析表明了该方法的有效性。
网址:
https://arxiv.org/abs/2003.05597
代码链接:
https://github.com/Thinklab-SJTU/CSL_RetinaNet_Tensorflow
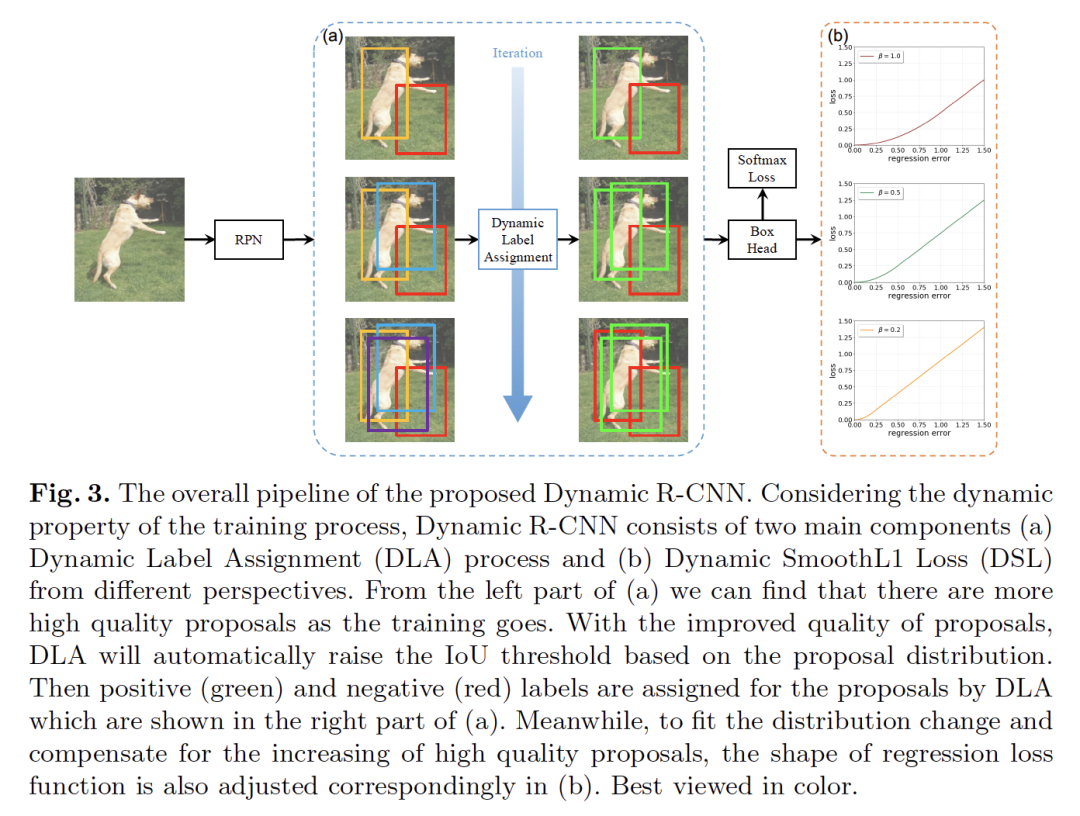
2. Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
作者:Hongkai Zhang, Hong Chang, Bingpeng Ma, Naiyan Wang, Xilin Chen
摘要:虽然two-stage目标检测器近年来不断提升了最先进的性能,但训练过程本身还有很多提升的空间。在这项工作中,我们首先指出了固定网络设置和动态训练过程之间的不一致问题,这对性能有很大的影响。例如,固定标签分配策略和回归损失函数不能适应候选区域(Proposal)的分布变化,不利于训练高质量的检测器。因此,我们提出了动态R-CNN算法,在训练过程中根据候选的统计信息自动调整标签分配标准(IOU阈值)和回归损失函数的形状(SmoothL1损失的参数)。这种动态设计更好地利用了训练样本,并推动检测器拟合更多的高质量样本。具体地说,我们的方法在MS Coco数据集上比ResNet-50-FPN基线在AP上提升了1.9%在AP_{90}上提升了5.5%,并且没有额外的开销。
网址:
https://arxiv.org/abs/2004.06002
代码链接:
https://github.com/hkzhang95/DynamicRCNN
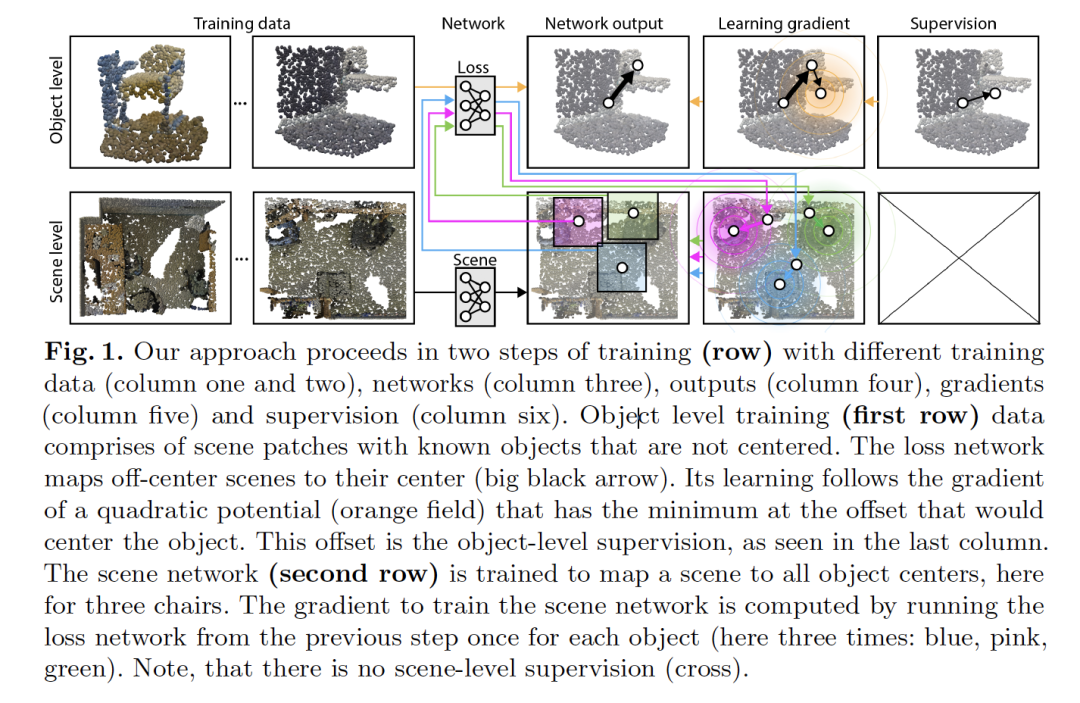
3. Finding Your (3D) Center: 3D Object Detection Using a Learned Loss
作者:David Griffiths, Jan Boehm, Tobias Ritschel
摘要:对于2D图像,海量语义标注很容易实现,但对于3D场景,实现起来要困难得多。像ShapeNet这样的3D存储库中的目标是有标签的,但遗憾的是,这些目标只是孤立的,并没有上下文。3D场景可以通过 city-level 的距离扫描仪获取,但很少带有语义标签。为了解决这一差异,我们引入了一种新的优化程序,它允许使用原始3D扫描进行3D检测训练,同时在只使用5%的目标标签的情况下仍然可以获得相当的性能。我们的优化使用两个网络。场景网络将整个3D场景映射到一组3D目标中心。由于我们假设场景不是由中心标记的,所以没有经典的损失(如:chamfer)可以用来训练它。取而代之的是,我们使用另一个网络来模拟损失。该损失网络在一个小的带标签的子集上进行训练,并且在存在干扰的情况下将非居中的3D目标映射到其自身的中心。该函数非常类似监督损失具有的梯度,因此可以作为损失来替代。我们的评估文档分别在较低级别的监督下达到具有竞争力的准确性,在可比的监督下具有高质量。
网址:
https://arxiv.org/abs/2004.02693
代码链接:
https://github.com/dgriffiths3/finding-your-center
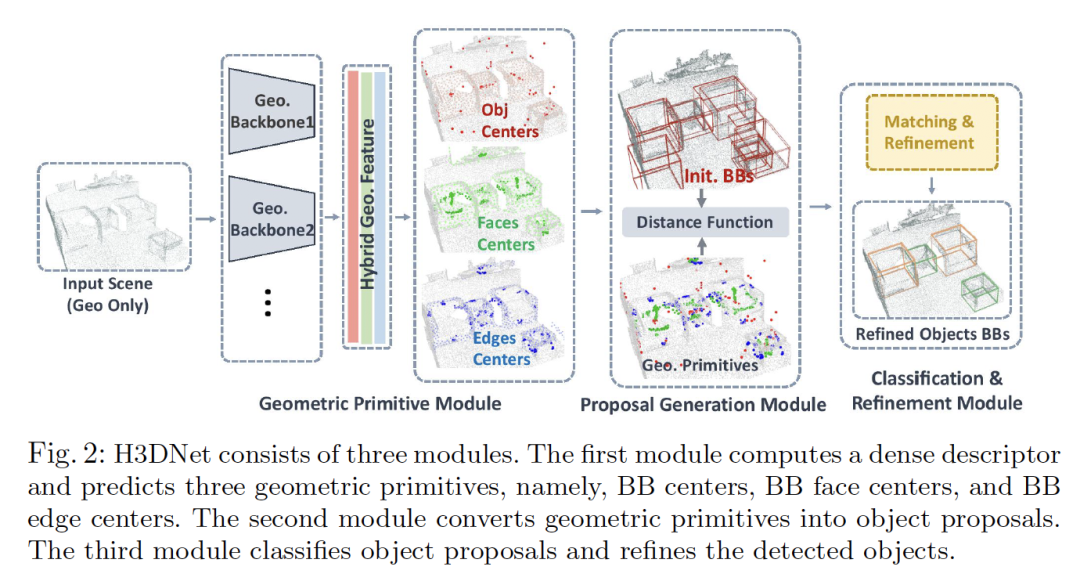
4. H3DNet: 3D Object Detection Using Hybrid Geometric Primitives
作者:Zaiwei Zhang, Bo Sun, Haitao Yang, Qixing Huang
摘要:我们引入了H3DNet,它以一个三维点云作为输入,输出一组面向目标的边界框(BB)集合及其语义标签。H3DNet的关键思想是预测一组混合的几何图元(geometric primitives),即BB中心、BB面中心和BB边中心。通过定义目标与几何图元之间的距离函数,我们展示了如何将预测的几何图元转换为目标候选。此距离函数可实现对目标候选的连续优化,其局部最小值可提供高保真目标候选。然后,H3DNet利用匹配和优化模块将目标候选分类为检测到的目标,并微调检测到的目标的几何参数。与使用单一类型的几何图元相比,混合几何图元集不仅为目标检测提供了更准确的信号,而且它还在所得到的3D布局上提供了过完整的约束集。因此,H3DNet可以容忍预测的几何图元中的异常值。我们的模型在两个具有真实3D扫描的大型数据集ScanNet和SUN RGB-D上实现了最新的3D检测结果。
网址:
https://arxiv.org/abs/2006.05682
代码链接:
https://github.com/zaiweizhang/H3DNet
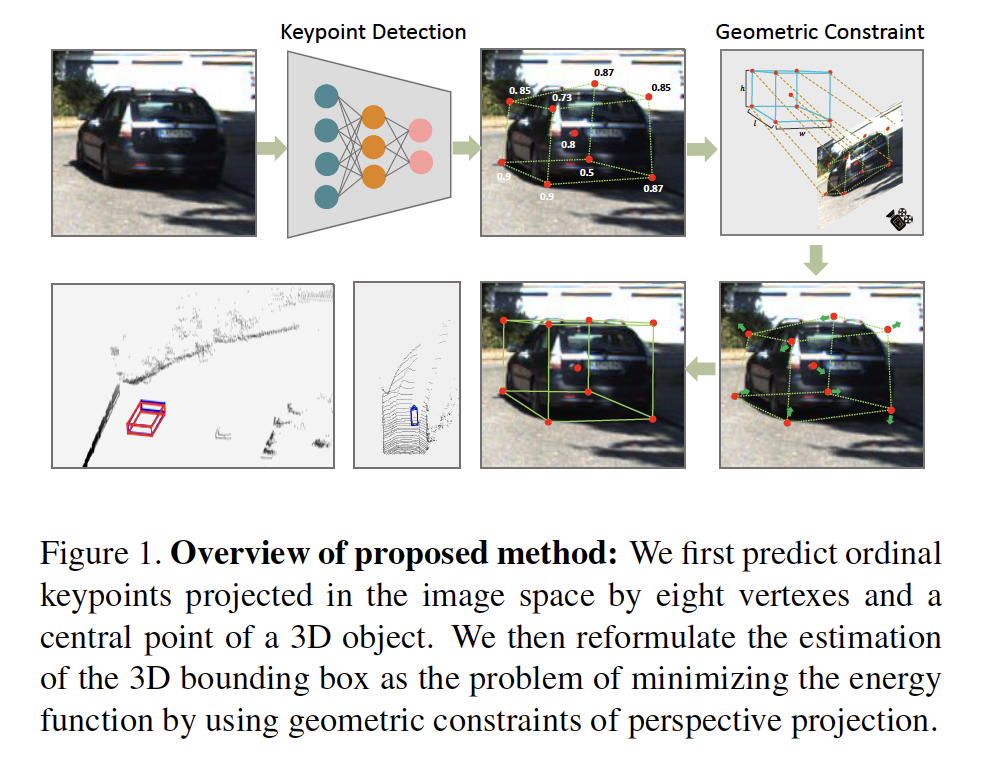
5. RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
作者:Peixuan Li, Huaici Zhao, Pengfei Liu, Feidao Cao
摘要:在这项工作中,我们提出了一种高效、准确的单目3D检测框架。大多数成功的3D检测器都将3D bounding box 到2D bounding box的投影约束作为一个重要组成部分。2D 框的四个边仅提供四个约束,并且随着2D检测器的小误差,检测性能会急剧恶化。与这些方法不同的是,我们的方法预测图像空间中3D bounding box 的九个透视关键点,然后利用3D和2D透视的几何关系来恢复3D空间中的维度、位置和方向。这种方法即使在关键点的估计非常嘈杂的情况下,也可以稳定地预测目标的属性,这使我们能够以较小的架构获得较快的检测速度。我们的方法的训练仅使用目标的3D属性,而无需外部网络或监督数据。我们的方法是第一个单目图像3D检测的实时系统,同时在KITTI基准上实现了最先进的性能。
网址:
https://arxiv.org/abs/2001.03343
代码链接:
https://github.com/Banconxuan/RTM3D
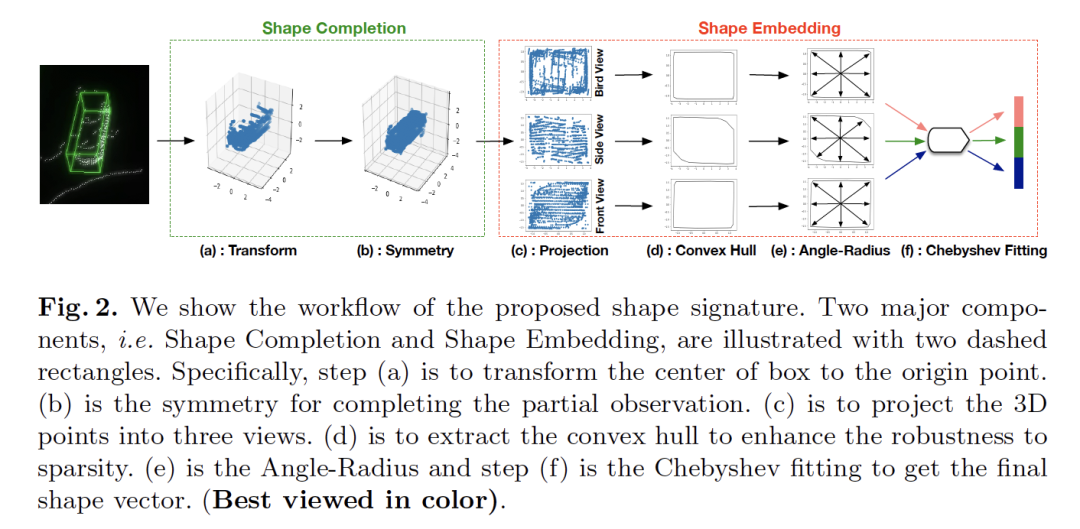
6. SSN: Shape Signature Networks for Multi-class Object Detection from Point Clouds
作者:Xinge Zhu, Yuexin Ma, Tai Wang, Yan Xu, Jianping Shi, Dahua Lin
摘要:多类别3D目标检测的目标是对点云中的多类别目标进行定位和分类。由于点云的非结构化、稀疏性和噪声等特性,一些有利于多类别区分的特征没有得到充分利用,例如形状信息。本文提出了一种新的3D形状特征来探索点云中的形状信息。通过引入对称、凸包(convex hull)和切比雪夫拟合等操作,我们所提出的形状特征不仅紧凑有效,而且对噪声具有较强的鲁棒性,可以作为一个软约束来提高特征的多类别区分能力。基于提出的形状特征,我们开发了用于3D目标检测的形状特征网络(SSN),该网络由金字塔特征编码部分,形状感知分组头(shape-aware grouping heads)和显式形状编码目标组成。实验表明,该方法在两个大规模数据集上的性能明显优于现有方法。此外,我们的形状特征可以作为一个即插即用的组件,消融实验表明它的有效性和良好的可扩展性。
网址:
https://arxiv.org/abs/2004.02774
代码链接:
https://github.com/xinge008/SSN
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ECCV2020OD” 就可以获取《6篇顶会ECCV 2020【目标检测(Object Detection)】相关论文》的pdf下载链接~





