7 Papers & Radios | NeurIPS'22获奖论文;英伟达一句话生成3D模型
机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周主要论文包括 NeurIPS 2022 获奖论文;英伟达提出的一句话生成 3D 模型等研究。
目录
Is Out-of-Distribution Detection Learnable?
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Elucidating the Design Space of Diffusion-Based Generative Models
One Venue, Two Conferences: The Separation of Chinese and American Citation Networks
Human-level play in the game of Diplomacy by combining language models with strategic reasoning
Magic3D: High-Resolution Text-to-3D Content Creation
Sleep prevents catastrophic forgetting in spiking neural networks by forming a joint synaptic weight representation
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Is Out-of-Distribution Detection Learnable?
作者:Zhen Fang、Yixuan Li、Jie Lu、 Jiahua Dong、Bo Han、Feng Liu
论文地址:https://openreview.net/forum?id=sde_7ZzGXOE
摘要:这项工作提供了分布外 (OOD) 检测的理论研究,重点关注此类模型可学习的条件。该工作使用 PAC(probably approximately correct)学习理论表明 OOD 检测模型仅在数据分布空间和预测模型空间的某些条件下是 PAC 可学习的。该研究还提供了 3 个具体的不可能定理,可以用来确定 OOD 检测在实际环境中的可行性,为现有的 OOD 检测方法提供了理论基础。这项工作还提出了新的理论问题,例如关于 near-OOD 检测的可学习性。该研究将在 OOD 检测这个重要的研究领域产生广泛的理论和实践影响。
推荐:NeurIPS 2022 Main Track 杰出论文。
论文 2:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
作者:Chitwan Saharia、William Chan、Saurabh Saxena 等
论文地址:https://openreview.net/forum?id=08Yk-n5l2Al
摘要:基于扩散过程的高质量图像生成模型已在机器学习领域产生巨大的影响。该研究代表了此类模型的 SOTA 水平之一,并创新性地展示了独立训练的大型语言模型与大规模图像解码器的有效结合。这种实用的解耦很可能成为大规模文本到图像模型的主导范例。该研究的成果令人印象深刻。
推荐:NeurIPS 2022 Main Track 杰出论文。
论文 3:Elucidating the Design Space of Diffusion-Based Generative Models
作者:Tero Karras、Miika Aittala、Timo Aila、Samuli Laine
论文地址:https://openreview.net/forum?id=k7FuTOWMOc7
摘要:这篇论文通过调查思考,将先前的研究组织成一个连贯的共同框架,以促成新的建模改进,这是该研究的研究方法。该研究的重点是包含某种形式扩散过程的图像生成模型,尽管训练此类模型存在困难,但这种模型最近变得非常流行。这篇论文对基于扩散过程的模型的理解和实现做出了重要贡献。
推荐:NeurIPS 2022 Main Track 杰出论文。
论文 4:One Venue, Two Conferences: The Separation of Chinese and American Citation Networks
作者:Bingchen Zhao 、 Yuling Gu 等
论文地址:https://arxiv.org/pdf/2211.12424.pdf
摘要:本文中,来自爱丁堡大学以及艾伦人工智能研究所等机构的研究人员,对中国研究人员和美国研究人员之间的差异进行了探索。研究中他们采用了 NeurIPS 引用数据,以此来分析美国和中国机构对学术研究的影响。结果发现中国机构对美国和欧洲的论文引用很少(under-cite),而美国和欧洲机构对中国的论文引用也很少。
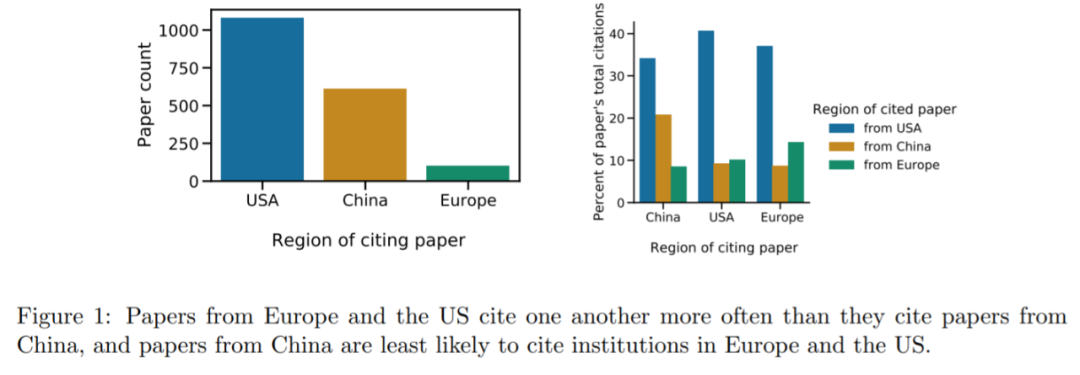
根据图表显示,我们可以看出美国和中国的论文在多大程度上没有引用对方的文章。从中国对美国论文的引用量来看,虽然美国论文占了数据集的 60%(总共 1792 篇,图 1 左显示美国大约 1100 篇),但它们被中国论文引用的数量只占 34%(图 1 右)。
美国对中国论文的引用差距则更显著:虽然中国论文占数据集的 34%,但它们只占美国引用数的 9%。
作为对比,我们来看看美国对欧洲论文的引用,对比很明显:尽管在此次实验中,NeurIPS 论文数据集中的中国论文数量是欧洲论文的 6 倍,但美国机构引用中国论文的频率低于欧洲论文。
该研究还观察到每个地区自引的频率都高于被其他地区引用的频率:中国为 21%, 美国为 41%,欧洲为 14%。美国和欧洲的研究界有着相似的引用行为,对中国论文的引用很少,而中国机构引用美国和欧洲论文的频率低于其他地区。
推荐:研究发现,中国和美国相互引用较少。
论文 5:Human-level play in the game of Diplomacy by combining language models with strategic reasoning
作者:COLIN FLAHERTY 、DANIEL FRIED 等
论文地址:https://www.science.org/doi/10.1126/science.ade9097
摘要:Meta 构建的智能体 CICERO,成为首个在 Diplomacy 中达到人类水平的 AI。CICERO 通过在在线版本 webDiplomacy.net 上证明了这一点,其中 CICERO 的平均得分是人类玩家的两倍多,并且在玩过不止一场游戏的参与者中排名前 10%。
CICERO 的核心是一个可控的对话模型和一个战略推理引擎。在游戏的每一点,CICERO 都会查看 game board 及其对话历史,并对其他玩家可能采取的行动进行建模。然后制定计划来控制语言模型,将它的计划告知其他玩家,并为与他们协调良好的其他玩家提出合理的行动建议。
为了构建一个可控对话模型,Meta 从一个具有 27 亿参数的类 BART 语言模型开始,并在来自互联网的文本上进行了预训练,还在 webDiplomacy.net 上对 40000 多个人类游戏进行了微调。
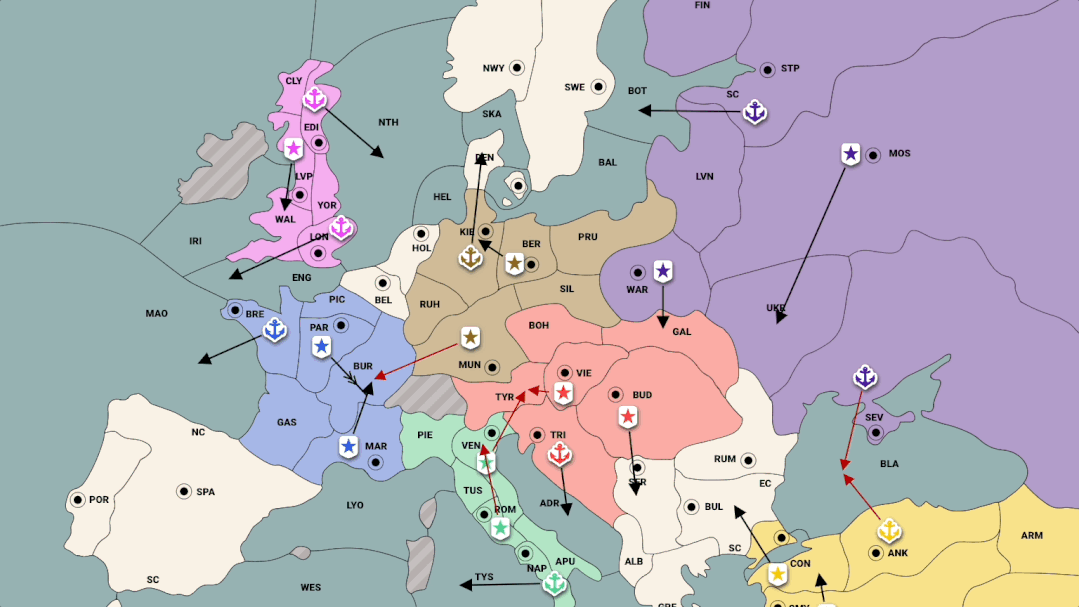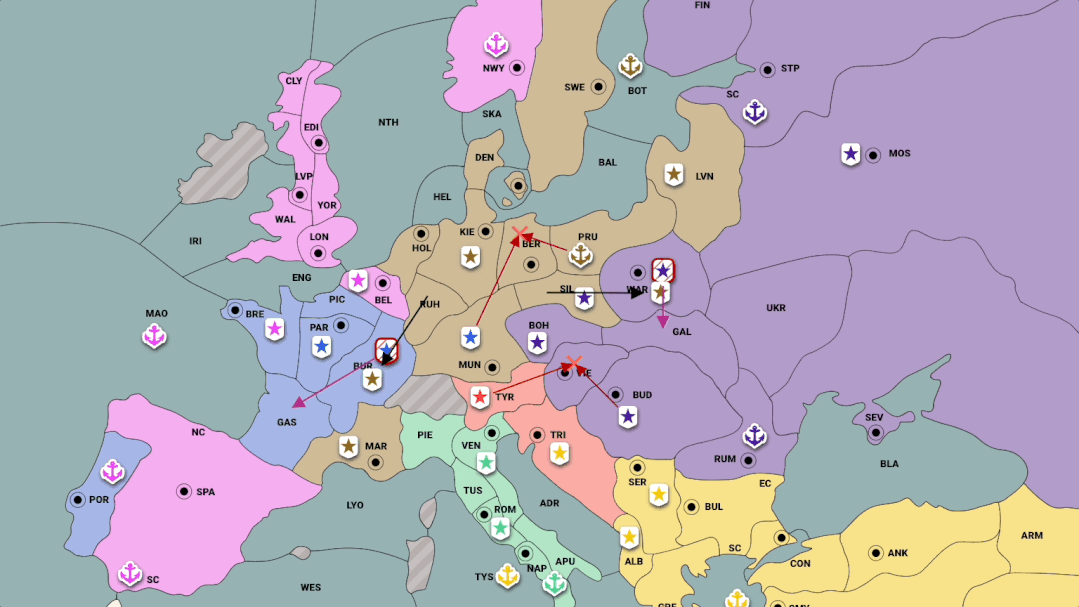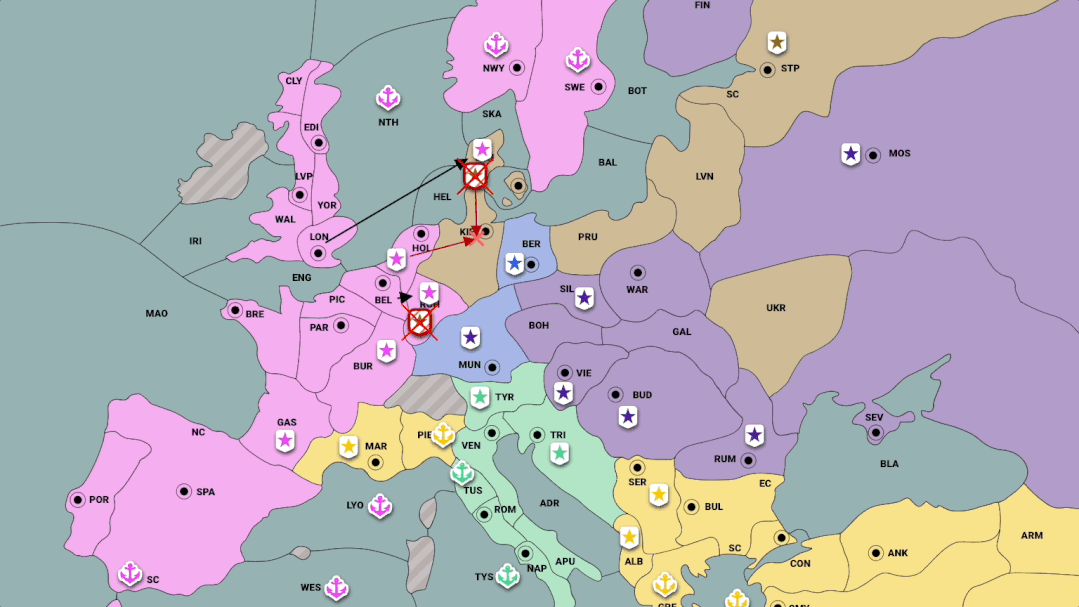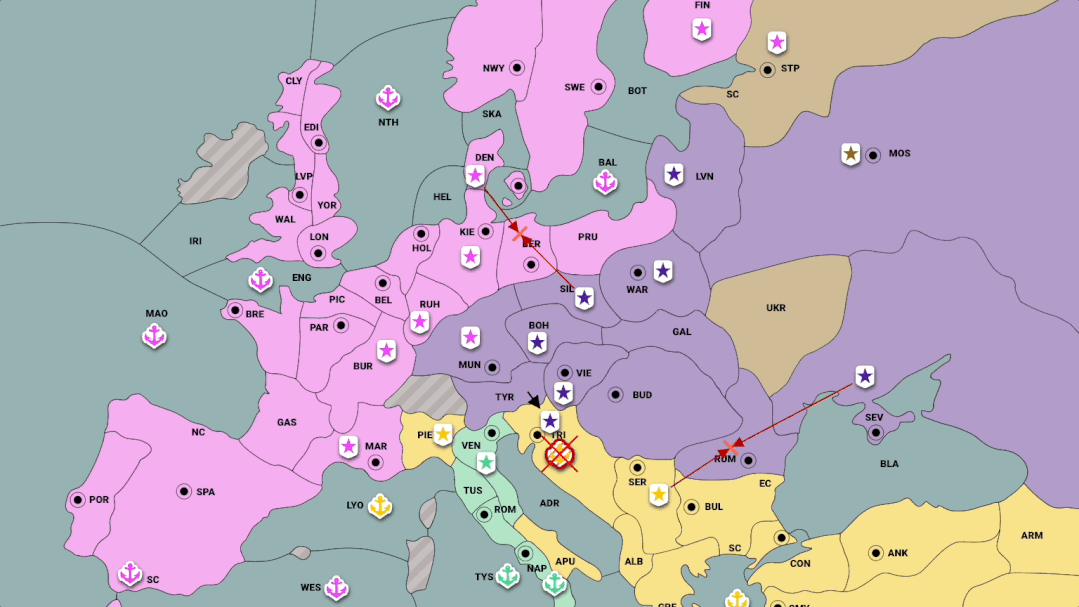
推荐:争取盟友、洞察人心,最新的 Meta 智能体是个谈判高手。
论文 6:Magic3D: High-Resolution Text-to-3D Content Creation
作者:Chen-Hsuan Lin、Jun Gao、Luming Tang 等
论文地址:https://arxiv.org/abs/2211.10440
摘要:英伟达提出 Magic3D ,可以在 40 分钟内创建高质量的 3D 网格模型,比 DreamFusion 快 2 倍(后者平均需要 1.5 小时),同时还实现了更高的分辨率。统计表明相比 DreamFusion,61.7% 的人更喜欢英伟达的新方法。
Magic3D 是一种从粗到精的优化方法,其中使用不同分辨率下的多个扩散先验来优化 3D 表征,从而生成视图一致的几何形状以及高分辨率细节。Magic3D 使用监督方法合成 8 倍高分辨率的 3D 内容,速度也比 DreamFusion 快 2 倍。
Magic3D 的整个工作流程分为两个阶段:在第一阶段,该研究优化了类似于 DreamFusion 的粗略神经场表征,以实现具有基于哈希网格(hash grid)的内存和计算的高效场景表征。
在第二阶段该方法切换到优化网格表征。这个步骤很关键,它允许该方法在高达 512 × 512 的分辨率下利用扩散先验。由于 3D 网格适用于快速图形渲染,可以实时渲染高分辨率图像,因此该研究利用基于光栅化的高效微分渲染器和相机特写来恢复几何纹理中的高频细节。
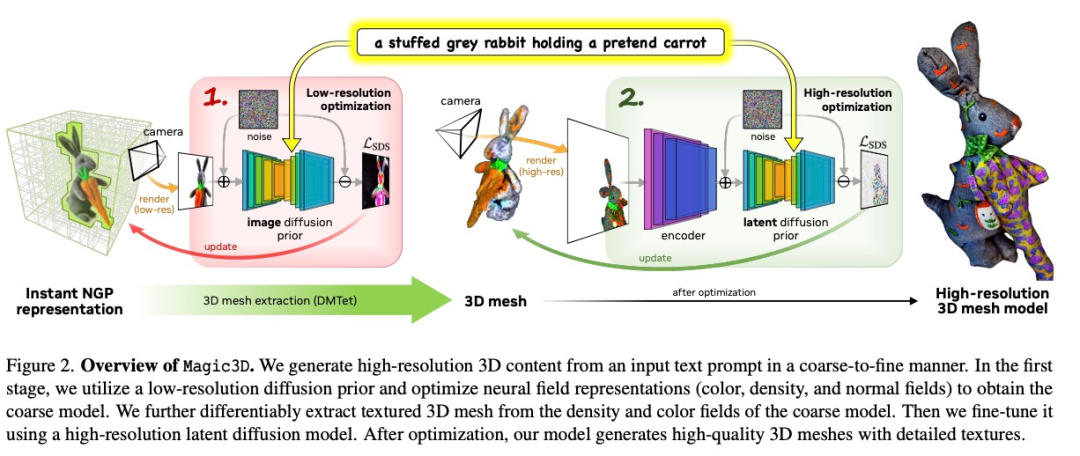
一只坐在睡莲上的蓝色箭毒蛙:

推荐:一句话生成 3D 模型。
论文 7:Sleep prevents catastrophic forgetting in spiking neural networks by forming a joint synaptic weight representation
作者:Ryan Golden、Jean Erik Delanois 等
论文地址:https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1010628
摘要:在一项新研究中,研究人员分析了神经网络灾难性遗忘背后的机制以及睡眠对于预防问题的效果。研究人员没有使用传统的神经网络,而是使用了一种更接近人类大脑的「脉冲神经网络」。
在人工神经网络中,神经元的输出随着输入的变化而不断变化。相比之下,在脉冲神经网络(SNN)中,一个神经元只有在给定数量的输入信号后,才会产生输出信号,这一过程是对真正生物神经元行为的真实再现。由于脉冲神经网络很少发射脉冲,因此它们比典型的人工神经网络传输的数据更少,原则上也需要更少的电力和通信带宽。
正如预期的那样,脉冲神经网络具有这样一个特点:在初始学习过程中会出现灾难性遗忘,然而,在之后的几轮学习后,经过一段时间间隔,参与学习第一个任务的神经元集合被重新激活。这更接近神经科学家目前认为的睡眠过程。
简单来说就是:SNN 使得之前学习过的记忆痕迹能够在离线处理睡眠期间自动重新激活,并在不受干扰的情况下修改突触权重。
图 1A 显示了一个前馈脉冲神经网络,用于模拟信号从输入到输出。位于输入层 (I) 和隐藏层 (H) 之间的神经元接受无监督学习 (使用非奖励 STDP),H 层和输出 (O) 层之间的神经元则接受强化学习 (使用奖励 STDP 实现)。
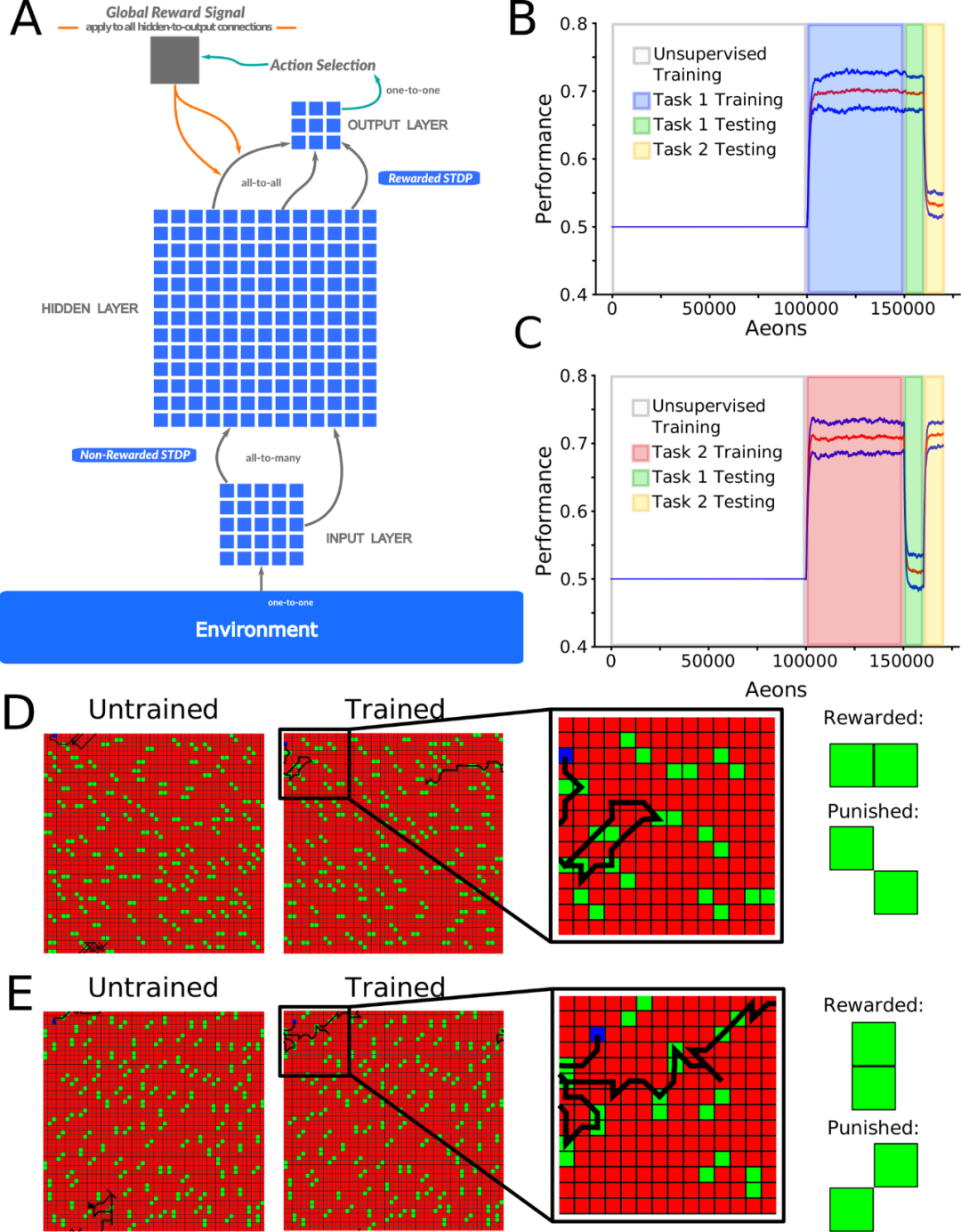
推荐:研究者发现想要避免神经网络的「灾难性遗忘」,它们需要像人一样睡眠。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



