7 Papers & Radios | 国产数据库入选顶会VLDB 2022;一句话生成高清360度场景和光照
机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周重要论文包括被数据库顶会 VLDB 2022 接收的国产数据库 OceanBase 研究成果,以及基于零次学习文本驱动的 HDR 全景图合成框架 Text2Light 等。
目录:
-
Text2Light: Zero-Shot Text-Driven HDR Panorama Generation Frozen CLIP Models are Efficient Video Learners
Blind Robust VideoWatermarking Based on Adaptive Region Selection and Channel Reference
OceanBase: A 707 Million tpmC Distributed Relational Database System
LAVIS: A Library for Language-Vision Intelligence
scBERT as a Large-scale Pretrained Deep Language Model for Cell Type Annotation of Single-cell RNA-seq Data
Deep Learning the Functional Renormalization Group
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Text2Light: Zero-Shot Text-Driven HDR Panorama Generation
作者:Zhaoxi Chen 等
论文地址:https://arxiv.org/pdf/2209.09898.pdf
摘要:随着元宇宙的浪潮和虚拟现实技术的不断进步,对于 3D 逼真写实渲染的需求愈发凸显。除去建模精细度,环境光照也是影响渲染质量的重要因素。在所有图形学技术中,高动态范围全景贴图(HDRI)能够提供逼真的场景光照和沉浸式的环境纹理,是最通用且高效的方法。
本文中,研究者提出了一个基于零次学习文本驱动的 HDR 全景图合成框架,Text2Light,能够根据输入的场景描述合成分辨率超过 4K 的具有高动态范围的全景图。模型的输出可以直接在 Blender、UE、Maya 等现代图形学渲染管线中,作为场景纹理和光照使用。
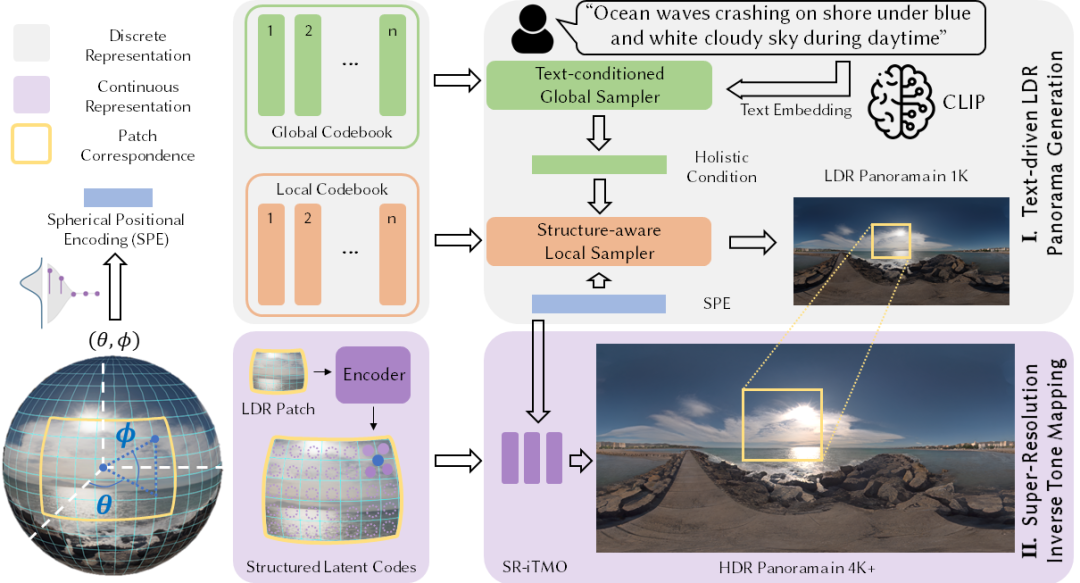
Text2Light 的工作流程。
推荐:SIGGRAPH Asia 2022 | 一句话生成高清 360 度场景及光照,可直接渲染数字资产。
论文 2:Frozen CLIP Models are Efficient Video Learners
作者:Ziyi Lin 等
论文地址:https://arxiv.org/pdf/2208.03550.pdf
摘要:视觉基础模型近两年取得了瞩目发展。从一方面而言,基于大规模互联网数据的预训练已经给模型预置了大量的语义概念,从而具有良好的泛化性能;但另一方面,为充分利用大规模数据集带来的模型尺寸增长,使得相关模型在迁移到下游任务时面临着低效率问题,尤其是对于需要处理多帧的视频理解模型。
基于上述两方面特点,来自香港中文大学、上海人工智能实验室等机构的研究者提出了高效的视频理解迁移学习框架 EVL,通过固定骨干基础模型的权重,节省了训练计算量和内存消耗;同时通过利用多层次、细粒度的中间特征,尽可能保持了传统端到端微调的灵活性。
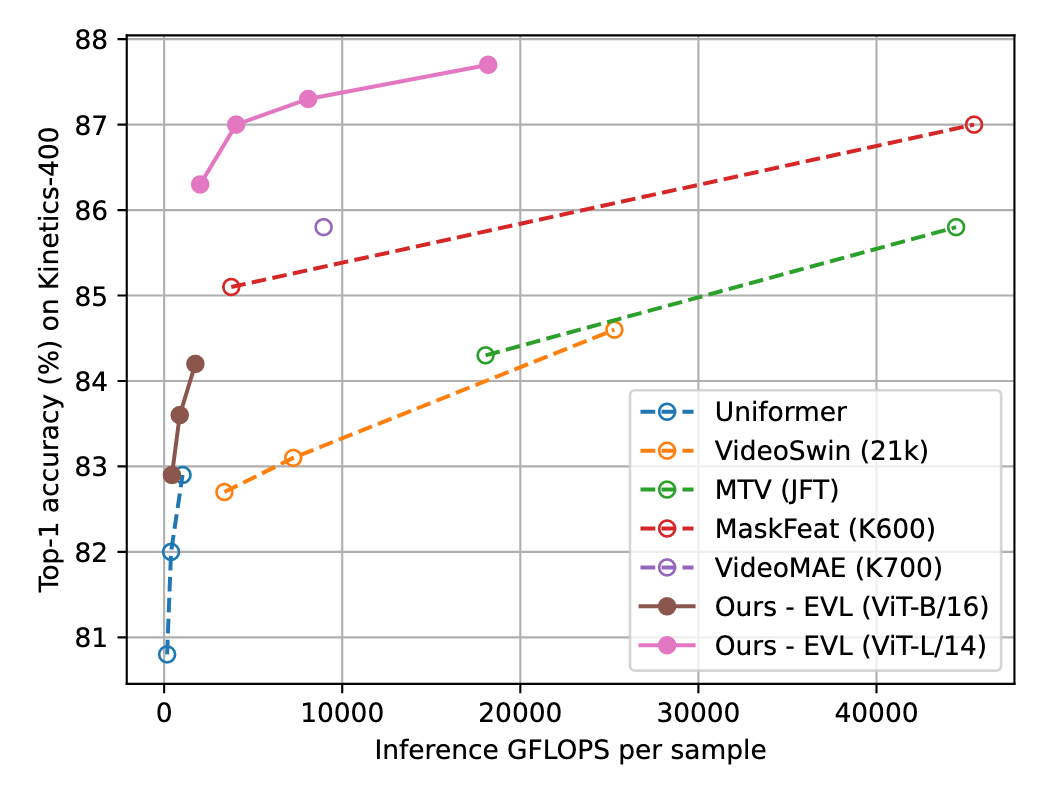
Kinetics-400 识别精度比较,横轴为推理计算量,纵轴为精度。
推荐:固定参数的模型有多大潜力?港中文、上海 AI Lab 等提出高效视频理解框架 EVL。
论文 3:Blind Robust VideoWatermarking Based on Adaptive Region Selection and Channel Reference
作者:Qinwei Chang 等
论文地址:https://arxiv.org/pdf/2209.13206.pdf
摘要:数字水印技术由于隐蔽性、安全性的天然优势,广泛应用于多媒体盗版侵权确认、泄密溯源、隐秘通信等场景。本文中,腾讯 AI 技术中心的研究者介绍了一种基于自适应区域选择和通道参考的视频盲水印算法,相关工作已被 ACM MM2022 接收。
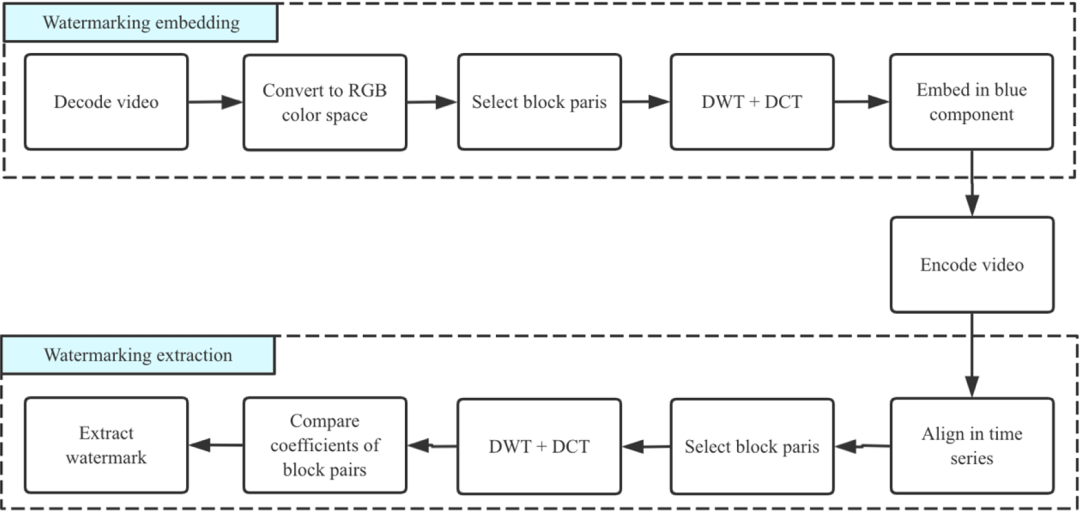
推荐:腾讯基于自适应区域选择和通道参考的视频盲水印,高效对抗各类攻击。
论文 4:OceanBase: A 707 Million tpmC Distributed Relational Database System
作者:Zhenkun Yang 等
论文地址:https://vldb.org/pvldb/vol15/p3385-xu.pdf
摘要:OceanBase 研究成果论文《OceanBase: A 707 Million tpmC Distributed Relational Database System》,被数据库国际顶会 VLDB 2022 接收。VLDB 与 SIGMOD、ICDE 并称为全球数据库三大学术顶会,收录研究机构以及工业界在数据库领域最前沿、最顶级的研究成果。
论文介绍了 OceanBase 的设计目标、设计标准、基础设施和关键组件,以及在 1500 多台服务器(分布于 3 个区域)的分布式集群中通过 TPC-C 基准测试并取得全球最高成绩背后的技术细节。
VLDB 评审专家也对 OceanBase 给予了高度评价:「作为创造 TPC-C 基准测试世界纪录的大规模分布式关系数据库系统,其架构和重要组件在论文中得到了非常全面的概述。OceanBase 设计并实现了一个分布式数据库,并在 OLTP 工作负载上实现了前所未有的性能和可扩展性。」
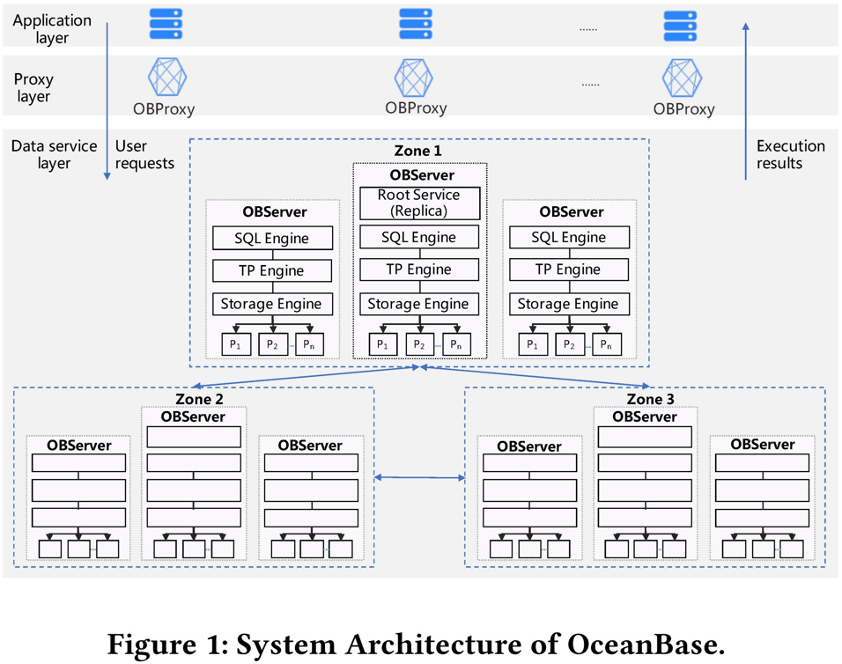
OceanBase 系统架构。
推荐:破世界纪录的国产数据库 OceanBase,如今入选了国际顶会 VLDB 2022。
论文 5:LAVIS: A Library for Language-Vision Intelligence
作者:Dongxu Li 等
论文地址:https://arxiv.org/pdf/2209.09019.pdf
摘要:为了使得更广泛的工程研究人员更好地利用视觉语言多模态模型能力,推动其在生产场景里的应用,以及减少重复开发的负担,Salesforce 亚洲研究院推出了开源框架 LAVIS (LAnguage-VISion 的简称)。
LAVIS 框架全方位支持 10+ 视觉语言任务,20+ 数据集,并提供 SOTA 模型性能和可复现预训练及微调实验配置。LAVIS 一大特点是统一和模块化的接口设计,极大降低训练、推理和开发的难度,致力于让研究和工程人员快速利用到近期多模态发展成果。
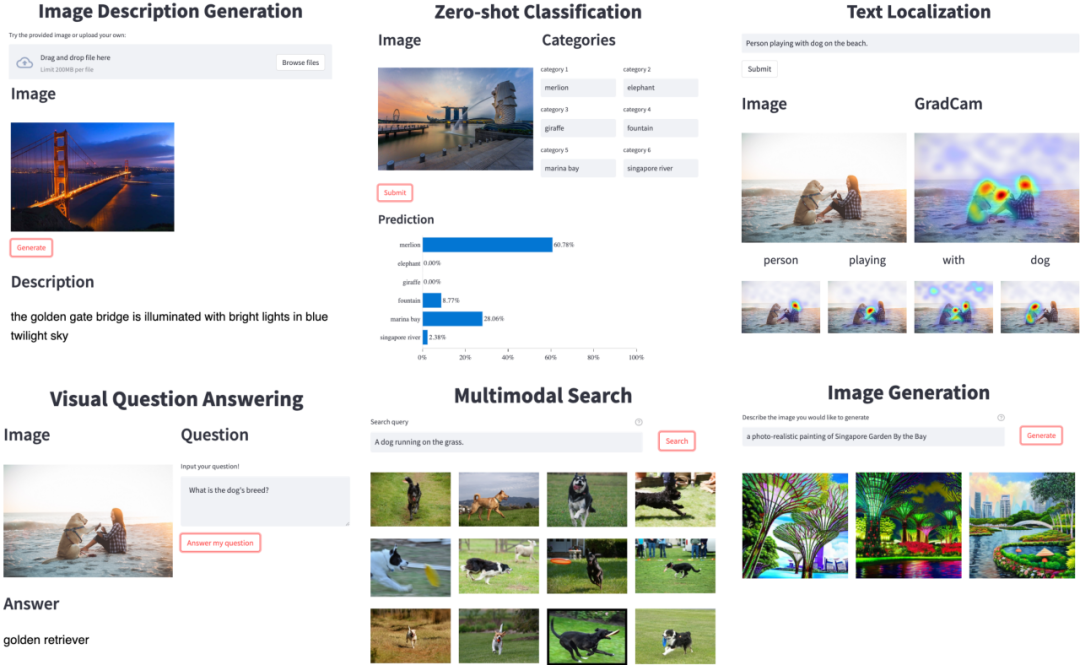
随 LAVIS 一起开源的 GUI demo,展示丰富的视觉语言应用场景。
推荐:全方位支持任务数据集模型,Salesforce 开源一站式视觉语言学习框架 LAVIS。
论文 6:scBERT as a Large-scale Pretrained Deep Language Model for Cell Type Annotation of Single-cell RNA-seq Data
作者:Fan Yang 等
论文地址:https://www.biorxiv.org/content/10.1101/2021.12.05.471261v3
摘要:AI 在科研领域再次展现了实力。最近,研究人员首次将 BERT 预训练和微调的范式引入单细胞转录组数据分析中。腾讯在人工智能、生命科学跨学科应用领域的最新研究成果《基于大规模预训练语言模型的单细胞转录组细胞类型注释算法》,登上了国际顶级学术期刊《Nature》子刊《Nature Machine Intelligence》。
腾讯在论文中创新性地提出关于单细胞注释的「scBERT」算法模型,受到评审高度认可。专家表示,该成果对于单细胞转录组测序数据分析领域未来研究具有深远意义。
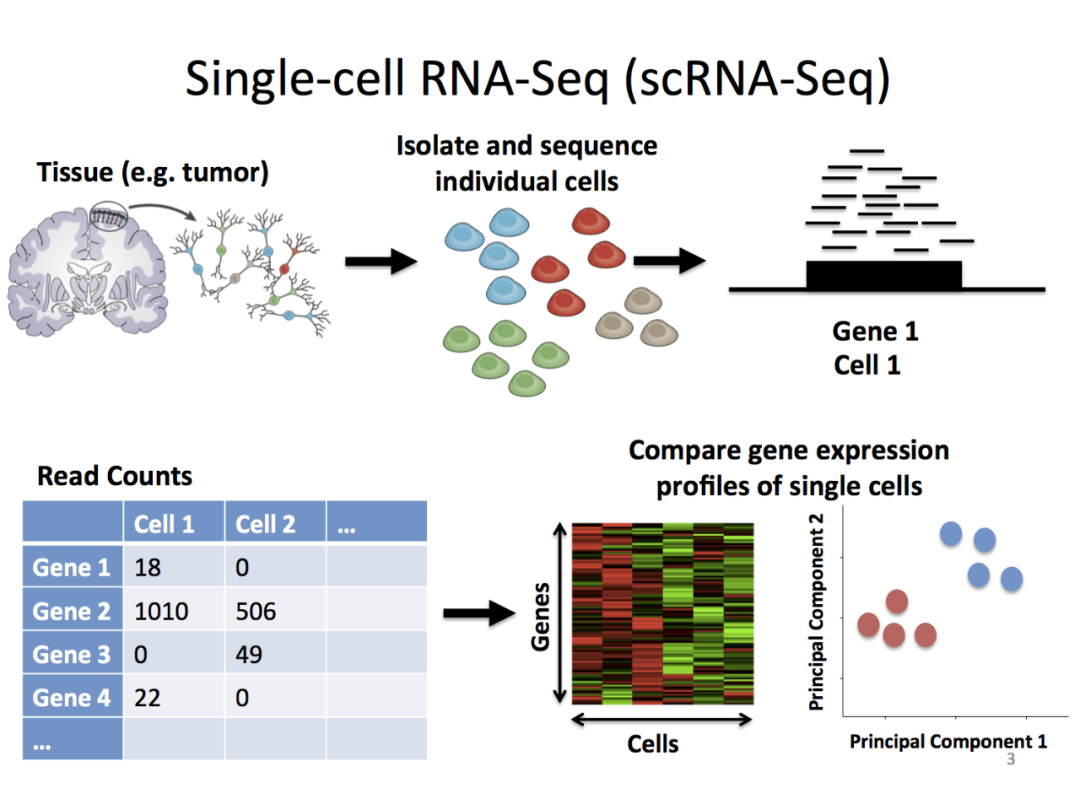
推荐:腾讯研究成果登 Nature 子刊:scBERT 攻克单细胞测序数据分析痛点。
论文 7:Deep Learning the Functional Renormalization Group
作者:Domenico Di Sante 等
论文地址:https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.129.136402
摘要:相互作用的电子在不同能量和温度下表现出多样的独特现象,假如我们对其周围环境进行改变,它们又会出现新的集体行为,例如自旋、配对波动等,然而处理电子之间的这些现象还存在很多困难。很多研究者使用重整化群(Renormalization Group, RG)来解决。在高维数据背景下,机器学习 (ML) 技术和数据驱动方法的出现在量子物理中引发了研究者巨大的兴趣,到目前为止,ML 思想已被用于电子系统的相互作用。
本文中,来自博洛尼亚大学等机构的物理学家利用人工智能,将一个迄今为止需要 10 万个方程的量子问题,压缩为一个只需 4 个方程的小任务,而所有这些都在不牺牲准确率的情况下完成,这项研究于近日发表在《物理评论快报》上。

Domenico Di Sante
推荐:10 万个方程才能解决的量子问题被 AI 压缩成只需 4 个,不牺牲准确率。
1. A simple but strong baseline for online continual learning: Repeated Augmented Rehearsal. (from Bernhard Pfahringer, Eibe Frank, Albert Bifet)
2. Exploring Low Rank Training of Deep Neural Networks. (from Jimmy Ba, Aidan N. Gomez)
3. Exploring the Relationship between Architecture and Adversarially Robust Generalization. (from Dacheng Tao)
4. Understanding Collapse in Non-Contrastive Learning. (from Alexei A. Efros)
5. Analyzing Diffusion as Serial Reproduction. (from Thomas L. Griffiths)
6. Liquid Structural State-Space Models. (from Daniela Rus)
7. Contrastive Unsupervised Learning of World Model with Invariant Causal Features. (from Roberto Cipolla)
8. Phy-Taylor: Physics-Model-Based Deep Neural Networks. (from Tarek Abdelzaher)
9. FedVeca: Federated Vectorized Averaging on Non-IID Data with Adaptive Bi-directional Global Objective. (from Jie Wu)
10. Improving alignment of dialogue agents via targeted human judgements. (from Demis Hassabis)



