7 Papers & Radios | 谷歌推出DreamBooth扩散模型;张益唐零点猜想论文出炉
机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周论文包括:谷歌提出 DreamBooth 扩散模型,只需 3-5 个样本和一句提示,AI 就能生成高质量图像;AI 自动生成 prompt 媲美人类等研究。
目录:
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Discrete mean estimates and the Landau-Siegel zero
LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
InfiniteNature-Zero Learning Perpetual View Generation of Natural Scenes from Single Images
Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning
NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
作者:Nataniel Ruiz 、 Yuanzhen Li 、 Varun Jampani 等
论文地址:https://arxiv.org/pdf/2208.12242.pdf
摘要:来自谷歌和波士顿大学的研究者提出了一种「个性化」的文本到图像扩散模型 DreamBooth,能够适应用户特定的图像生成需求。
该研究的目标是扩展模型的语言 - 视觉字典,使其将新词汇与用户想要生成的特定主题绑定。一旦新字典嵌入到模型中,它就可以使用这些词来合成特定主题的新颖逼真的图像,同时在不同的场景中进行情境化,保留关键识别特征,效果如下图 1 所示。

具体来说,该研究将给定主题的图像植入模型的输出域,以便可以使用唯一标识符对其进行合成。为此,该研究提出了一种用稀有 token 标识符表示给定主题的方法,并微调了一个预训练的、基于扩散的文本到图像框架,该框架分两步运行;从文本生成低分辨率图像,然后应用超分辨率(SR)扩散模型。
本文方法将一个主题(例如,一只特定的狗)和相应类名(例如,狗类别)的一些图像(通常 3 - 5 张图)作为输入,并返回一个经过微调 / 个性化的文本到图像模型,该模型编码了一个引用主题的唯一标识符。然后,在推理时,可以在不同的句子中植入唯一标识符来合成不同语境中的主题。
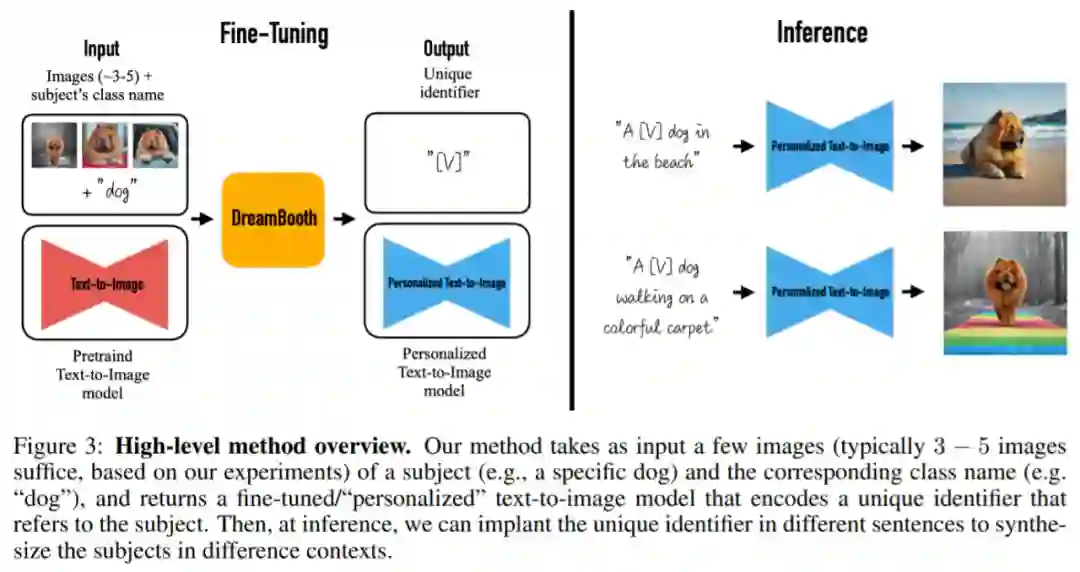
推荐:只需 3 个样本一句话,AI 就能定制照片级图像,谷歌在玩一种很新的扩散模型
论文 2:Discrete mean estimates and the Landau-Siegel zero
作者:张益唐
论文地址:https://arxiv.org/abs/2211.02515
摘要:数学家张益唐研究朗道 - 西格尔(Landau-Siegel)零点猜想论文已放出。本文主要贡献如下:首先是 L 函数在 1 点处的下界估计:
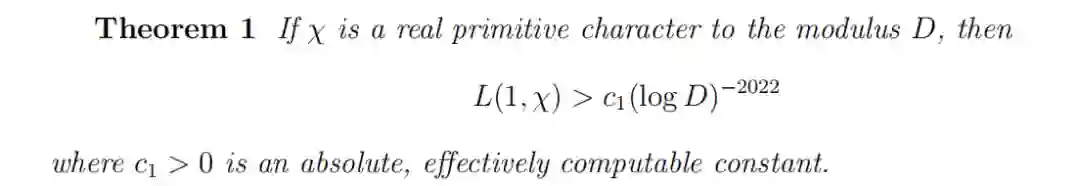
相应的有关于实轴上非零区域的直接推论:
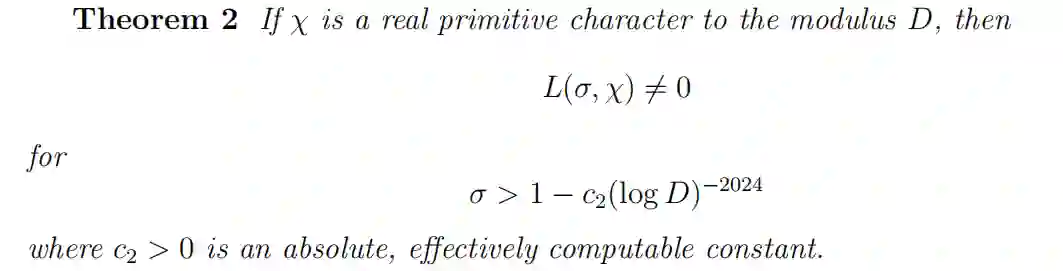
推荐:111 页,张益唐关于朗道 - 西格尔零点猜想的论文公布。
论文 3:LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
作者:Yongchao Zhou 、 Andrei Ioan Muresanu 等
论文地址:https://arxiv.org/pdf/2211.01910.pdf
摘要:来自多伦多大学、滑铁卢大学等机构的研究者提出了一种使用 LLM(大型语言模型)自动生成和选择指令的新算法。他们将此问题描述为自然语言程序合成,并建议将其作为黑盒优化问题来处理,LLM 可以用来生成以及搜索可行的候选解决方案。
研究者从三个方面入手。首先,使用 LLM 作为推理模型,根据输入 - 输出对形式的一小组演示生成指令候选。接下来,通过 LLM 下的每条指令计算一个分数来指导搜索过程。最后,他们提出一种迭代蒙特卡洛搜索方法,LLM 通过提出语义相似指令变体来改进最佳候选指令。
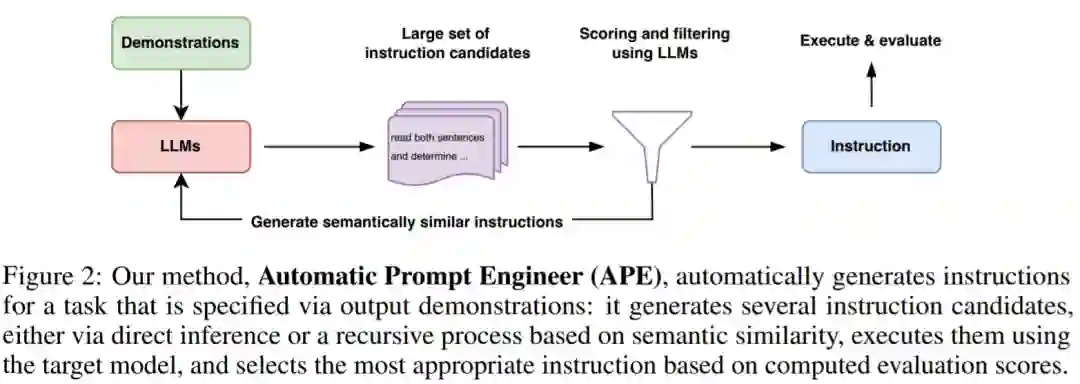
直观地说,本文提出的算法要求 LLM 根据演示生成一组指令候选,然后要求算法评估哪些指令更有希望,并将该算法命名为 APE(Automatic Prompt Engineer)。
APE 在建议(proposal)和评分这两个关键组件中都使用 LLM。如图 2 和算法 1 所示,APE 首先提出几个候选提示,然后根据选定的评分函数对候选集合进行筛选 / 精炼,最终选择得分最高的指令。
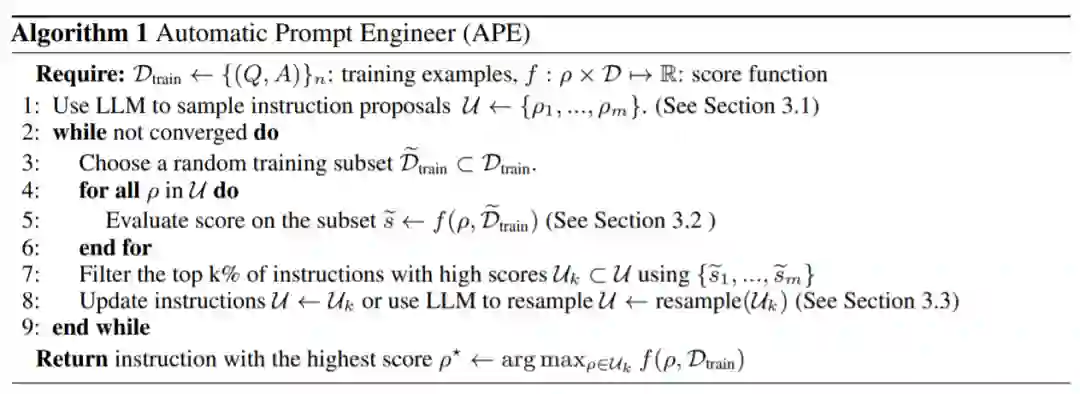
推荐:AI 自动生成 prompt 媲美人类。
论文 4:InfiniteNature-Zero Learning Perpetual View Generation of Natural Scenes from Single Images
作者:Zhengqi Li、 Qianqian Wang 等
论文地址:https://infinite-nature-zero.github.io/
摘要:为了构建沉浸式的虚拟现实体现,近几年人们开始思考计算机如何合成细节丰富的三维视觉体验。来自谷歌的研究团队近日做了一项名为「Infinite Nature」的研究工作,该研究表明计算机可以通过观看自然视频和照片来学习生成丰富的 3D 视觉体验。新模型 InfiniteNature-Zero 甚至可以仅在静态照片上训练,以单张图像作为「种子」,生成高分辨率、高质量的景观视频,这是前所未有的突破性能力。
谷歌将主要研究问题称为「永久型视图生成(perpetual view generation)」,即给定场景的单个输入视图,按照给定的相机路径,合成照片级真实的输出视图集。这一任务非常具有挑战性,因为系统必须为输入图像上的大型地标(例如山脉)的另一侧生成新内容,并以高逼真度和高分辨率渲染新内容。
下图是使用 InfiniteNature-Zero 生成的飞行效果示例:仅输入单个自然场景图像,模型运行时就能生成「飞入」该场景的新内容,体验非常真实。

推荐:仅用一张自然景观图片就能生成该场景的高质量 3D 「航拍」视频。
论文 5:Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning
作者:Dongze Lian、Daquan Zhou 等
论文地址:https://arxiv.org/abs/2210.08823
摘要:近期,由新加坡国立大学和字节跳动联合发表的论文入选 NeurIPS 2022。该论文提出了一个全新的、针对大模型训练的参数高效微调方法 SSF(Scaling & Shifting Your Features),可简洁、高效、零开销实现参数微调。
通过在 26 个分类数据集和 3 个鲁棒性数据集上评估 SSF 方法,结果显示:与其他参数高效的微调方法相比,SSF 获得了最先进的性能。
与完全微调相比,SSF 方法在 FGVC 和 VTAB-1k 上获得了 2.46%(90.72% {vs. 88.54%)和 11.48%(73.10% vs. 65.57%)的 Top-1 精度性能改进,但只需要大约 0.3M 的可训参数。此外,SSF 在推理阶段不需要额外的参数,可以即插即用,很容易扩展到各种模型系列(CNN、Transformer 以及 MLP 网络)。
SSF 的总体框架:
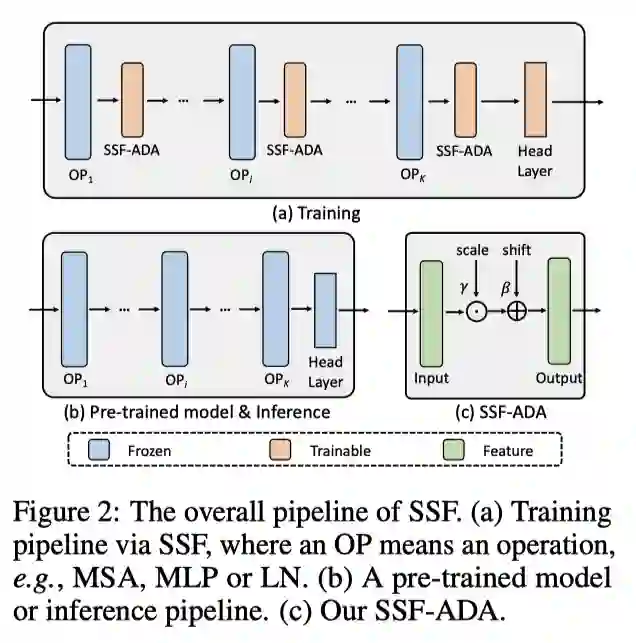
推荐:全新大模型参数高效微调方法 SSF:仅需训练 0.3M 的参数,效果卓越。
论文 6:NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
作者:Kaiwen Jiang、 Shu-Yu Chen 等
论文地址:http://geometrylearning.com/NeRFFaceEditing/
摘要:想要个性化设计高真实感的三维立体人脸,却发现自己并不熟悉专业的设计软件?三维人脸编辑方法 NeRFFaceEditing 提供了新的解决方案,即使不会三维建模,也能自由编辑高真实感的立体人脸,建模元宇宙中的个性化数字肖像!
NeRFFaceEditing 由中科院计算所和香港城市大学的研究人员合作完成,相关技术论文在计算机图形学顶级会议 ACM SIGGRAPH Asia 2022 上发表。
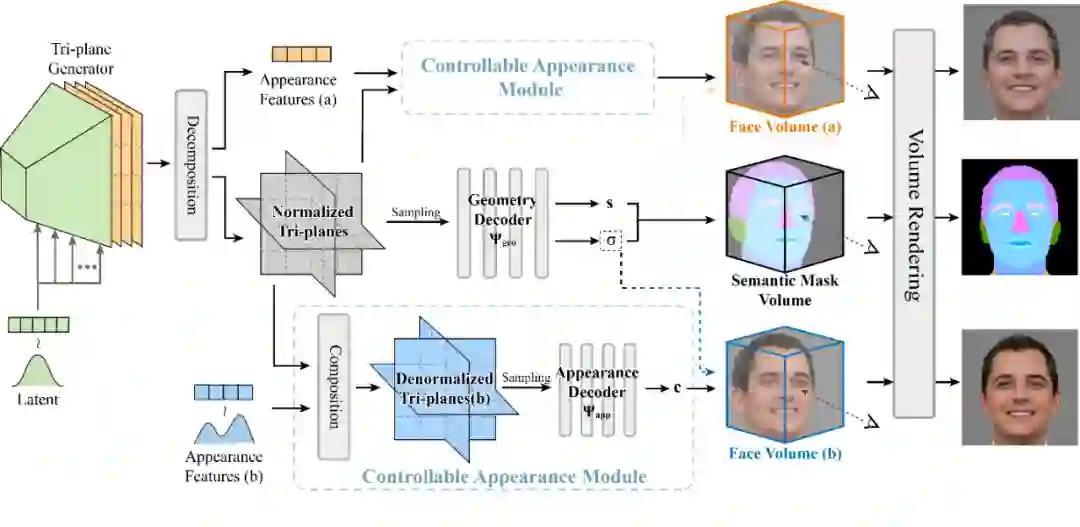
NeRFFaceEditing 将二维的语义掩码作为三维几何编辑的桥梁,用户在一个视角下进行的语义编辑可以传播到整个三维人脸的几何,并保持材质不变。进一步,给定表示参考风格的图像,用户可以轻松的更改整个三维人脸的材质风格,并保持几何不变。
基于该方法的三维人脸编辑系统,即使用户不熟悉专业的三维设计,也可以轻松进行个性化的人脸设计,自定义人脸形状和外观。
NeRFFaceEditing 的网络架构:
材质相似约束训练策略:
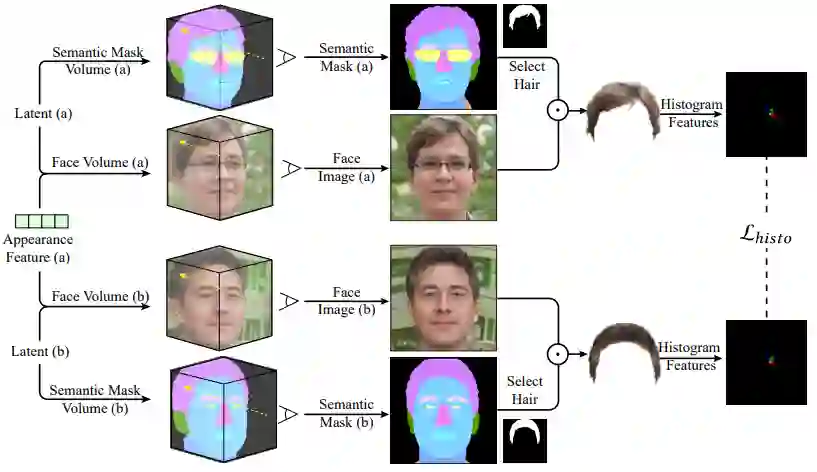
推荐:人脸神经辐射场的掩码编辑方法 NeRFFaceEditing,不会三维建模也能编辑立体人脸。
论文 7:RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
作者:Shitao Xiao、Zheng Liu 等
论文地址:https://arxiv.org/abs/2205.12035
摘要:近期,华为泊松实验室联合北京邮电大学、华为昇思 MindSpore 团队提出 “基于掩码自编码器的检索预训练语言模型 RetroMAE”,大幅刷新稠密检索领域的多项重要基准。而其预训练任务的简洁性与有效性,也为下一步技术的发展开辟了全新的思路。该工作已录用于自然语言处理领域顶级学术会议 EMNLP 2022。基于昇思开源学习框架的模型与源代码已向社区开放。
基于掩码自编码器的预训练流程示例:
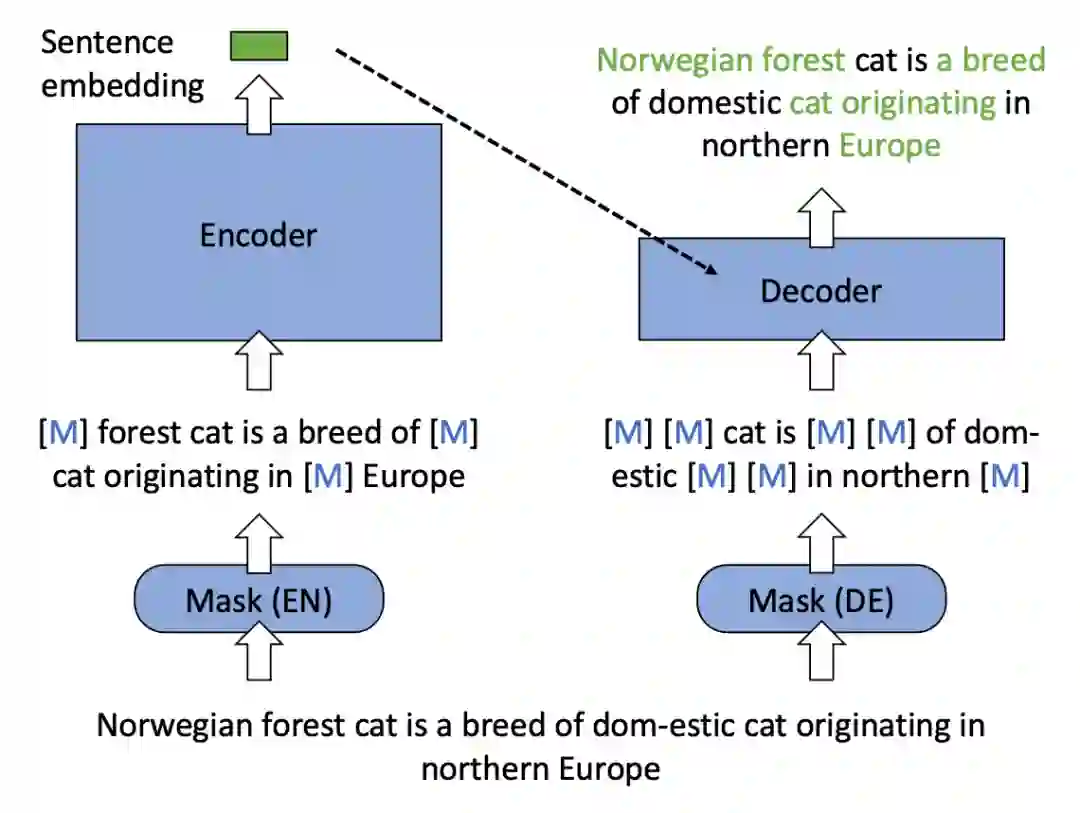
基础架构:掩码自编码器。RetroMAE 采用了经典的掩码自编码器这一架构来预训练模型的语义表征能力。首先,输入文本经掩码操作后由编码器(Encoder)映射为隐空间中的语义向量;而后,解码器(Decoder)借助语义向量将另一段独立掩码的输入文本还原为原始的输入文本。
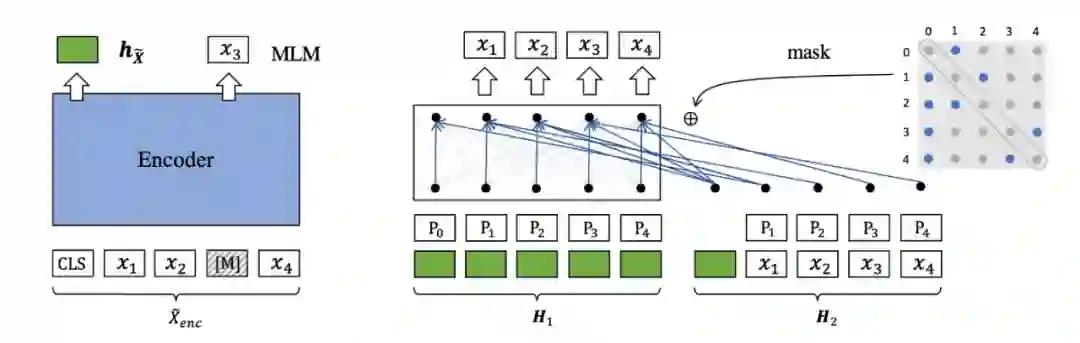
解码增强。双流注意力机制(H1:query stream,H2:content stream),随机生成注意力掩码矩阵(蓝色点:可见位置,灰色点:掩码位置)
推荐:稠密检索新突破:华为提出掩码自编码预训练模型,大幅刷新多项基准。
本周 10 篇 NLP 精选论文是:
1. Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning. (from Tarek Abdelzaher, Jiawei Han)
2. Estimating Soft Labels for Out-of-Domain Intent Detection. (from Jian Sun)
3. Nano: Nested Human-in-the-Loop Reward Learning for Few-shot Language Model Control. (from Ruslan Salakhutdinov, Louis-Philippe Morency)
4. Preserving Semantics in Textual Adversarial Attacks. (from Tomas Mikolov)
5. Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the [MASK] Token. (from Hermann Ney)
6. EvEntS ReaLM: Event Reasoning of Entity States via Language Models. (from Eduard Hovy)
7. Efficient Zero-shot Event Extraction with Context-Definition Alignment. (from Hongming Zhang)
8. Aligning Recommendation and Conversation via Dual Imitation. (from Minlie Huang)
9. DiaASQ: A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis. (from Tat-Seng Chua)
10. Novel Chapter Abstractive Summarization using Spinal Tree Aware Sub-Sentential Content Selection. (from Kathleen McKeown)
本周 10 篇 CV 精选论文是:
1. $BT^2$: Backward-compatible Training with Basis Transformation. (from Antonio Torralba)
2. NoiSER: Noise is All You Need for Enhancing Low-Light Images Without Task-Related Data. (from Yi Yang, Shuicheng Yan)
3. Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts. (from Bernt Schiele)
4. Rethinking the transfer learning for FCN based polyp segmentation in colonoscopy. (from Lei Zhang)
5. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. (from Xiaogang Wang, Yu Qiao)
6. Zero-shot Video Moment Retrieval With Off-the-Shelf Models. (from Raymond J. Mooney)
7. Soft Augmentation for Image Classification. (from Yang Liu, James Hays, Deva Ramanan)
8. Masked Vision-Language Transformers for Scene Text Recognition. (from Jie Wu)
9. Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories. (from Andrea Vedaldi)
10. A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal. (from Wei Liu)
本周 10 篇 ML 精选论文是:
1. FED-CD: Federated Causal Discovery from Interventional and Observational Data. (from Bernhard Schölkopf)
2. A Theoretical Study on Solving Continual Learning. (from Bing Liu)
3. GOOD-D: On Unsupervised Graph Out-Of-Distribution Detection. (from Huan Liu)
4. Distributional Shift Adaptation using Domain-Specific Features. (from Huan Liu)
5. Cherry Hypothesis: Identifying the Cherry on the Cake for Dynamic Networks. (from Dacheng Tao)
6. Regression as Classification: Influence of Task Formulation on Neural Network Features. (from Francis Bach, Jean-Philippe Vert)
7. On Optimizing the Communication of Model Parallelism. (from Eric P. Xing)
8. Stabilizing Machine Learning Prediction of Dynamics: Noise and Noise-inspired Regularization. (from Michelle Girvan)
9. ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning. (from Peter Stone)
10. Extragradient with Positive Momentum is Optimal for Games with Cross-Shaped Jacobian Spectrum. (from Fabian Pedregosa)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com




