微软亚洲研究院持续迭代BEiT,为通用基础模型的大一统发展奠定基础

(本文阅读时间:12分钟)
韦福如,本科、硕士和博士毕业于武汉大学计算机学院。博士期间,他在香港理工大学计算机系担任访问学者,自此开始从事自然语言处理(Natural Language Processing,NLP)领域的研究工作。
几年间,韦福如在 NLP 领域取得了多次突破,并在大规模预训练模型、自然语言处理,多模态人工智能等领域持续创新,曾入选2017年《麻省理工科技评论》“35岁以下科技创新35人”中国区榜单。

微软亚洲研究院首席研究员韦福如
目前,韦福如已在微软亚洲研究院工作12年,现任自然语言计算组首席研究员。他以 NLP 为主攻领域,这是人工智能的核心课题之一,是一门研究机器如何理解和生成自然语言的学科。该领域包括语言分析、信息抽取、信息检索、文本挖掘、机器阅读理解、智能问答、机器翻译、自动文摘,文本生成以及综合场景应用等研究课题。
近年来,随着自然语言处理的研究和技术广泛迁移到人工智能的其他领域,韦福如和团队还专注于跨任务、跨语言和跨模态基础模型、语音处理、文档智能和多模态人工智能等领域的研究。
从技术层面来看,最近几年 NLP 领域取得了非常出色的进展。大规模预训练模型正在引领人工智能领域进行一场前所未有的范式迁移:在海量的未标注数据上通过自监督预训练得到一个预训练模型(又称为基础模型),再通过微调或少样本/零样本学习使用少量标注,甚至不需要标注数据,即可把基础模型广泛应用到下游任务模型上。新的范式取得了优异的效果,并展现出了强大的泛化和通用能力。
“这几年有三个重要的关键词。第一个是大规模预训练模型,或称为基础模型,即在通过自监督学习完成预训练的同时,也实现了模型训练的范式迁移。第二个是多语言,也就是用一个模型可以支持多种语言的下游任务。第三个是多模态,即不同模态(例如文本、图像、语音等)的建模和学习逐渐趋于融合和统一。”韦福如表示。

计算机视觉(Computer Vision, CV)领域通常使用的是有监督预训练,也就是利用有标注的数据进行训练。但随着视觉模型的不断扩大,标注数据难以满足模型需求,当模型达到一定规模时,即使模型再扩大,也无法得到更好的结果,这就是所谓的数据饥饿(data hungry)。因此,科研人员开始使用无标注数据进行自监督学习,以此预训练大模型参数。
以往在 CV 领域,无标注数据的自监督学习常采用对比学习。但对比学习存在一个问题——对图像干扰操作过于依赖。当噪声太简单时,模型学习不到有用的知识;而对图像改变过大,甚至面目全非时,模型无法进行有效学习。所以对比学习很难把握这之间的平衡,且需要大批量训练,对显存和工程实现要求很高。
在此背景下,韦福如团队于2021年推出了生成式自监督的视觉预训练模型 BEiT,借助掩码图像建模(Masked Image Modeling,MIM)方法完成预训练任务。
国际表征学习(International Conference on Learning Representations,ICLR)大会评审委员会认为,BEiT 为视觉大模型预训练的研究开创了一个全新的方向,首次成功将掩码预训练应用在了 CV 领域非常具有创新性。实验结果表明,与之前的预训练方法相比,BEiT 可实现更为优越的效果。
基于 BEiT,2022年韦福如和团队进一步丰富了自监督学习的语义信息,发布了 BEiT-2,并随后将其升级为 BEiT-3。
2022年8月31日,相关论文以《把图像视为外语:适用于所有视觉和视觉-语言任务的BEiT预训练方法》(Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks)为题发布在预印本平台 arXiv [1]。

BEiT-3 论文
随着大模型的发展,语言、视觉等多模态领域的预训练模型已呈现出“大一统”趋势。模型在大规模、海量数据上预训练之后,能顺利迁移至各种下游任务中。因此,预训练一个能够处理多种模态的通用基础模型,也成为目前人工智能研究的一个关键课题。
BEiT-3 正是这样一种通用的多模态基础模型,在广泛的视觉和视觉-语言任务上,都实现了最好的迁移性能。
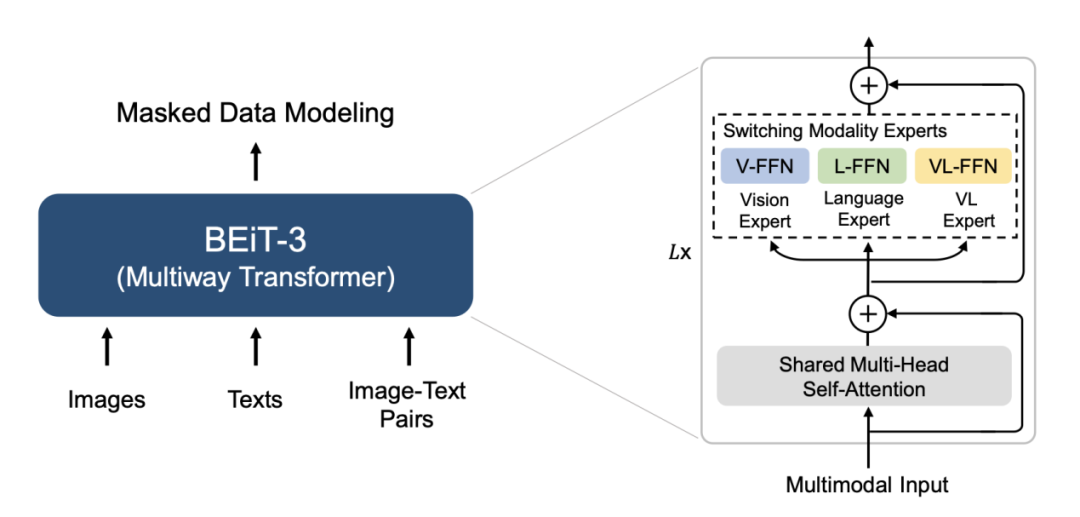
BEiT-3 预训练概述
在 BEiT-3 中,研究人员从骨干网络、预训练方法和模型规模化三个方面出发,推动了视觉-语言预训练任务的融合。
首先,研究人员使用 Multiway Transformer 作为骨干模型来编码不同的模态。每一个 Multiway Transformer 模块都由一个共享的自注意力模块和一组用于不同模态的前馈网络池(即模态专家)组成,从而可以同时编码多种模态。
此外,通过模块化的设计,统一架构可以用于不同的视觉及视觉-语言下游任务。其中,Multiway Transformer 每一层都包括一个视觉专家和一个语言专家。
最上面的三层有专门为融合编码器设计的视觉-语言专家。共享的自注意力模块可以对不同模态之间的对齐(即寻找对应关系)进行学习,并能深度融合多模态(如视觉-语言)信息。
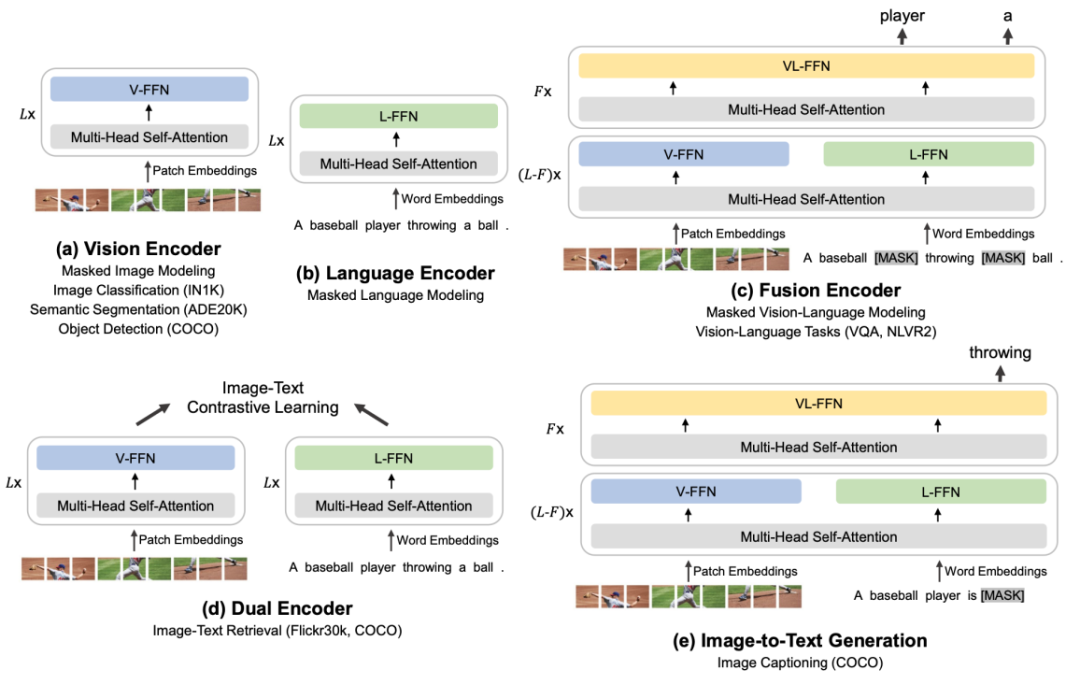
可以迁移到各种视觉和视觉-语言下游任务的 BEiT-3
统一的模型架构使 BEiT-3 能迁移到各种视觉和视觉-语言下游任务中。它不仅可以应用于图像分类、目标检测、实例分割等视觉任务的骨干网络,还可以在模型微调后成为高效的图像-文本检索的双编码器,以及多模态理解和生成任务的融合编码器等。
其次,在预训练 BEiT-3 的过程中,研究人员采用单模态和多模态数据的统一掩码数据建模(Masked Data Modeling)方法。这种方法能够随机屏蔽一定比例的文本或像素块,并训练模型去恢复被屏蔽的部分。统一的掩码-预测任务,不仅可以学习各模态的特征,还能学习它们之间的对齐。
其他视觉-语言模型一般采用图像-文本对比、图像-文本匹配等多种预训练任务,而 BEiT-3 只使用了一种预训练任务,这不仅有利于扩大模型规模,还有助于实现 GPU 内存等多方成本的降低。
最后,该团队从模型规模和数据规模两方面出发,将 BEiT-3 进行规模化,从而提高基础模型的泛化能力。
据悉,BEiT-3 由1408个隐藏神经元、6144个中间层神经元、16组注意力模块的40层 Multiway Transformer 骨干网络组成,模型共包含大约19亿个参数,其中视觉专家参数6.92亿,语言专家参数6.92亿,视觉-语言专家参数0.52亿,共享自注意力模块参数为3.17亿个。
据介绍,微软亚洲研究院在单模态和多模态数据上对 BEiT-3 进行了100万次迭代的预训练,每个批量的训练数据包含6144个样本,其中有2048张图像、2048个文本和2048个图像-文本对。相比使用对比学习方法训练的模型来说, BEiT-3 的批量规模要小得多。值得一提的是,这里面所有数据都是开源的。
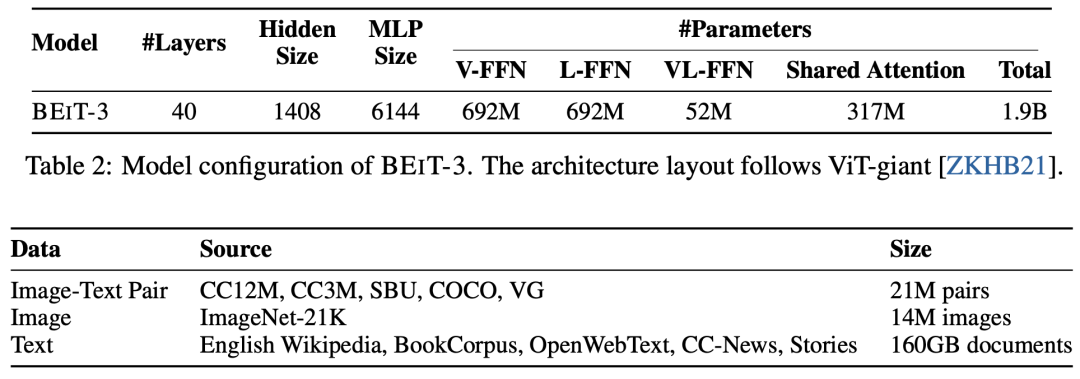
BEiT-3 模型参数分布及预训练数据
同时,在包含视觉问答、视觉推理、图像描述生成等在内的视觉-语言任务,以及包含目标检测与实例分割、语义分割、图像分类等在内的一共12个视觉-语言下游任务上,该团队评估了 BEiT-3 的泛化能力。结果表明,BEiT-3 在这些任务上都取得了 SOTA 的迁移性能。
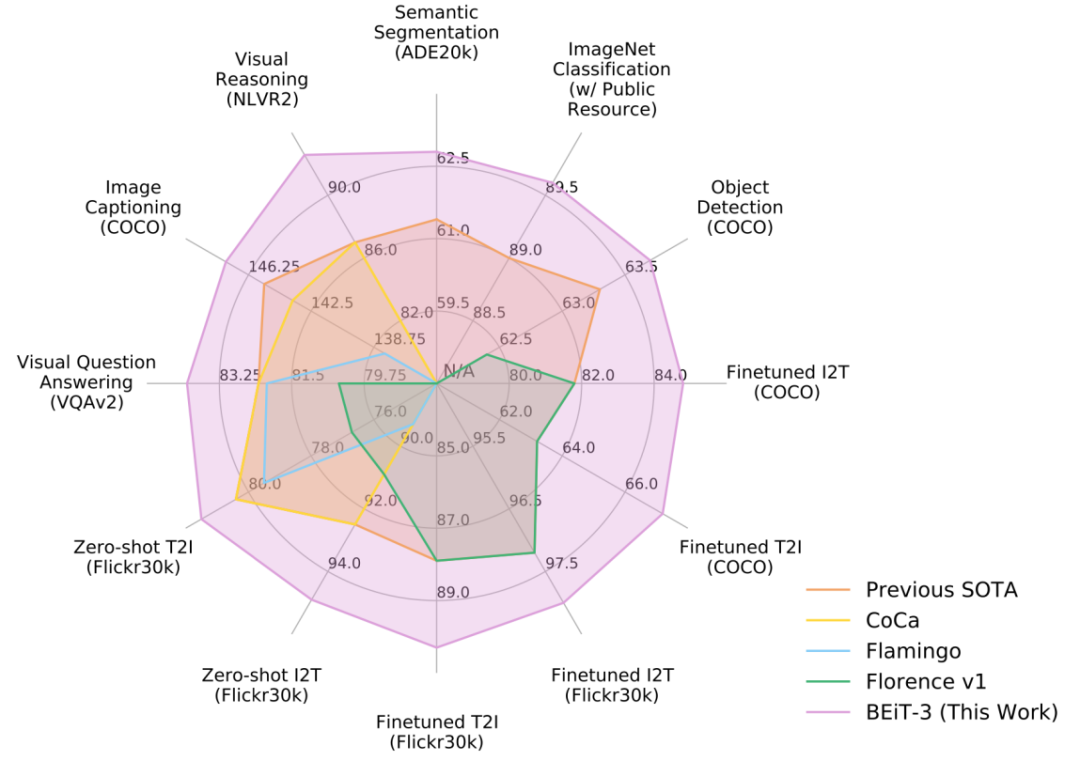
与其他特定模型或基础模型相比,BEiT-3 在广泛任务中实现了最佳性能
目前,在开发和训练大模型的过程中,仍然存在许多需要探讨和深思的问题。
例如,很多企业都会将数据收集类的工作外包处理,这个过程中不仅存在安全隐患,还会造成数据不均衡的问题。对此,韦福如表示,数据是模型的重要组成部分。没有好的数据,就不可能有好的模型。数据本身就是大模型研究的一部分,因此这部分的工作需要更加重视。
从某种程度上看,对数据部分的研究更需要汇集聪明才智。如何收集、整理以及使用数据,也是最值得投入和研究的课题之一。
又比如,研发大模型时不仅会消耗大量成本,甚至也会对气候造成一定影响。谈及这个问题,韦福如表示大模型的能效(efficiency)很重要,这也是接下来需要研究的重要部分之一。但另一方面,因为通用大模型的出现,相关领域的特定任务和模型将变得更加简单,这也有利于降低重复建设的成本。
在韦福如看来,未来大规模预训练模型向“大一统”方向发展,已经成为必然。这个“大一统”主要可从两个层面理解:
第一,从技术层面看,如何用相同的技术构建不同领域的基础模型?这包括构建通用骨干网络、生成式自监督学习为主的学习方式,以及持续扩大(scaling up)模型规模。
第二,从模型和应用层面看,如何构建一个能够处理不同语言和模态任务的基础模型?随着技术的统一,未来将会出现能够应用于各种领域的通用基础大模型。
韦福如认为:“只有模型标准化,才可能实现规模化,进而为大范围产业化提供基础和可能。‘大一统’中很重要的一点是,技术会变得越来越通用,只有通用才有可能更接近本质,也更利于不同领域的深度合作和相互促进。”
而对于 BEiT-3 来说,其核心思想就是把图像作为一种外语进行建模和学习,从而实现以统一的方式完成图像、文本和图像-文本的掩码“语言”建模,这也在自然语言处理领域被证实为最有效的扩大模型规模的技术方向和方案,这也将成为规模化基础模型一个颇有前景的方向。
未来,韦福如和团队将继续开展多模态预训练方面的工作,并将在其中加入包括音频、多语言在内的更多模态,在促进跨语言和跨模态转换的同时,推动跨任务、跨语言和跨模态的大规模预训练融合。
支持:王贝贝
参考资料:
1.W. Wang, H. Bao, L. Dong, J. Bjorck.et al. Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks. arXiv (2022).https://doi.org/10.48550/arXiv.2208.10442
H. Bao, L. Dong, S. Piao. F. Wei, BEiT:BERT Pre-Training of Image Transformers. arXiv (2021).https://doi.org/10.48550/arXiv.2106.08254
Z. Peng, L. Dong, H. Bao, Q. Ye, F. Wei, BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. arXiv (2022)https://doi.org/10.48550/arXiv.2208.06366
你也许还想看:







