微软T-ULRv6:引领基础模型向多语言“大一统”迈进

(本文阅读时间:9分钟)
近日,微软通用语言表示模型再创新佳绩。最新的 T-ULRv6 在谷歌 XTREME 和 GLUE 排行榜上摘得双榜冠军,证明了单个多语言模型可以同时在英语和多语言理解任务上达到 SOTA 性能。这也是多语言理解模型首次在两个排行榜上同时夺魁,力压专用于英语或专用于多语言任务的模型,从而有助于消除“多语言诅咒”。
微软亚洲研究院自然语言计算组首席研究员韦福如表示,“T-ULRv6 是我们推进大规模预训练语言模型以及 AI 模型‘大一统(The Big Convergence)’研究的重要里程碑。我们第一次发现通过规模化预训练语言模型,可以让多语言基础模型在高资源(rich-resource)语言(例如英文)上,取得与专门为这些语言设计和训练的单语言预训练模型在对应语言的下游任务上一样好的效果。之前的研究曾表明多语言预训练模型在低资源(low-resource)语言的下游任务上有很大的性能提升并具有支持跨语言迁移的能力。这也说明未来我们可以专注于规模化多语言基础模型,并结合我们所推进的多模态基础模型大一统方面的研究(如 BEiT-3),为接下来推进多语言、多模态模型的统一提供经验与参考。”
基于“XY-LENT”的 T-ULRv6 XXL 模型是微软图灵团队和微软亚洲研究院通力合作的成果,其平均分比 XTREME 排行榜目前位居第二的模型高出0.5分,在 GLUE 排行榜上也占据首位。
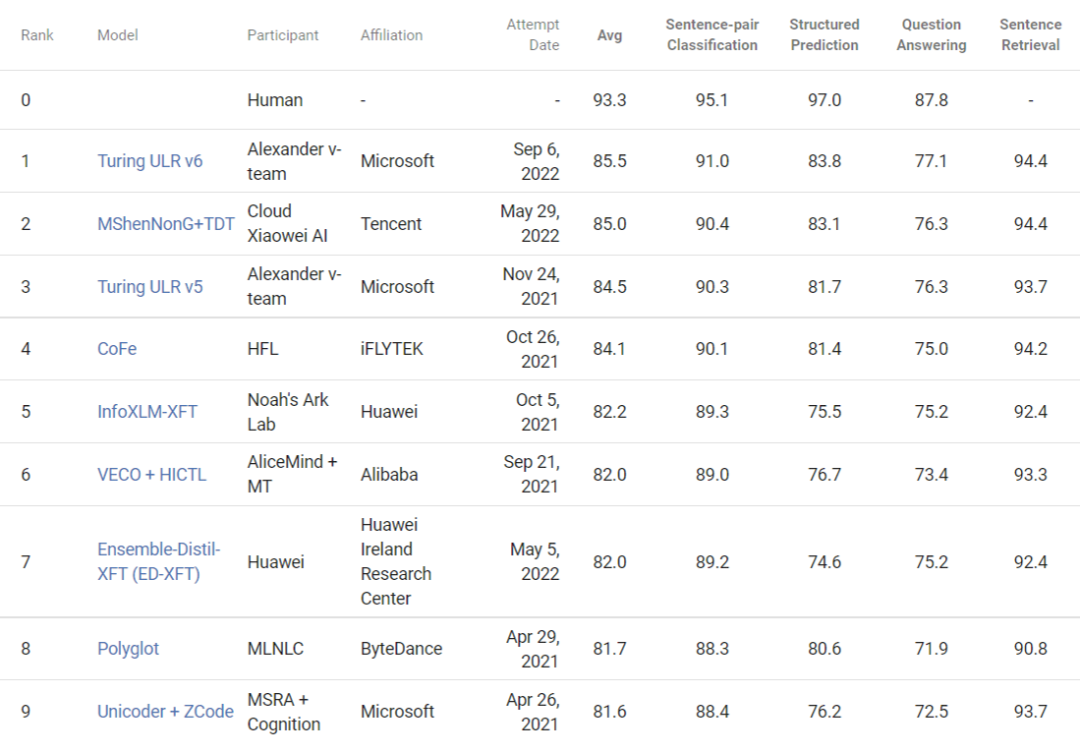
图1:T-ULRv6 XXL 位居 XTREME 排行榜首位
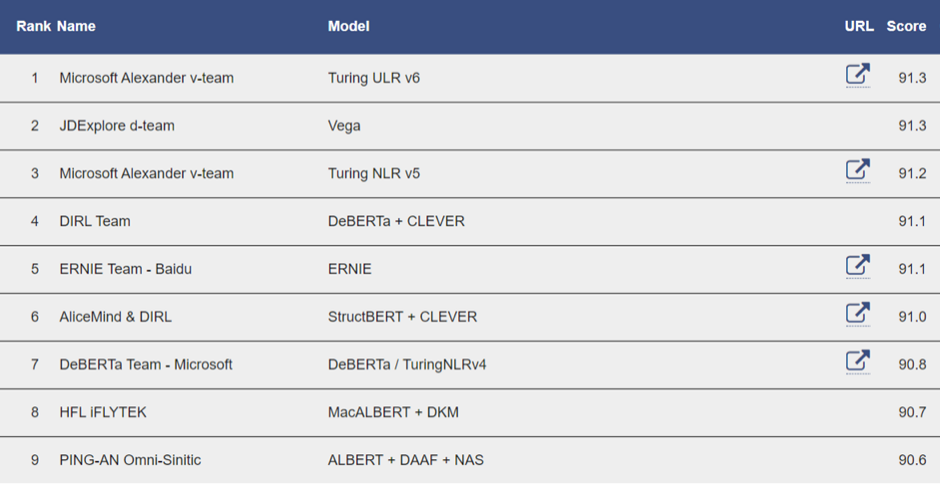
图2:T-ULRv6 XXL 位居 GLUE 排行榜首位
T-ULRv6 能够取得如此优异的成绩,是因为它在 XY-LENT 研究的基础之上,利用了不同语言之间的多向 (X-Y) 平行文本对 (bitexts) ,并整合了 T-ULRv5 的关键创新,其中包括 XLM-E 架构、MRTD 和 TRTD 的新型预训练任务、改进的训练数据和词汇,以及高级微调技术 xTune。此外,为了能够扩展到 XXL 大小的模型,微软还借助了 ZeRO 的内存优化优势。

T-ULRv6 的关键改进在于摒弃了以英语为中心的 (EN-X) 平行文本对,直接利用不同语言之间的多向 (X-Y) 平行文本对(如法语-德语、印地语-乌尔都语,或斯瓦希里语-阿拉伯语)。尽管在多语言机器翻译中利用这种平行文本对数据属于常规操作,但这是由问题的性质所决定的,研究员们的此次尝试表明,利用平行文本对数据进行多语言编码器训练会带来意想不到的性能提升。虽然 EN-X 平行文本对有助于学习跨语言对齐和共享表示,然而这种方式在语言和领域的覆盖范围及多样性上会受到制约。另一方面,X-Y 平行文本对可以为学习多语言表示提供更丰富、更均衡的信息,从而可以更好地推广到更广泛的语言和任务中。
为了有效地利用 X-Y 平行文本对,研究员们采用了一种新颖的采样策略,以确保数据在多语言之间有效分布,同时保持语言边际分布一致。反过来说,这也确保了模型仍然能够维持强大的英语性能。
在编码器中有一个值得注意的特性,就是参数效率。XY-LENT XXL 明显优于 XLM-R XXL 和 mT5 XXL,同时规模较后两者分别缩小了约2倍和3倍。即使在 Base、Large 和 XL 三个类别中,与同类的其他模型相比,XY-LENT 也是最先进的,并且展现出了跨类别的竞争优势。强大的性能和较少的参数,在产品开发场景中非常实用。
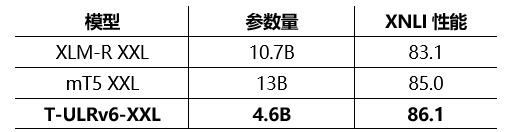
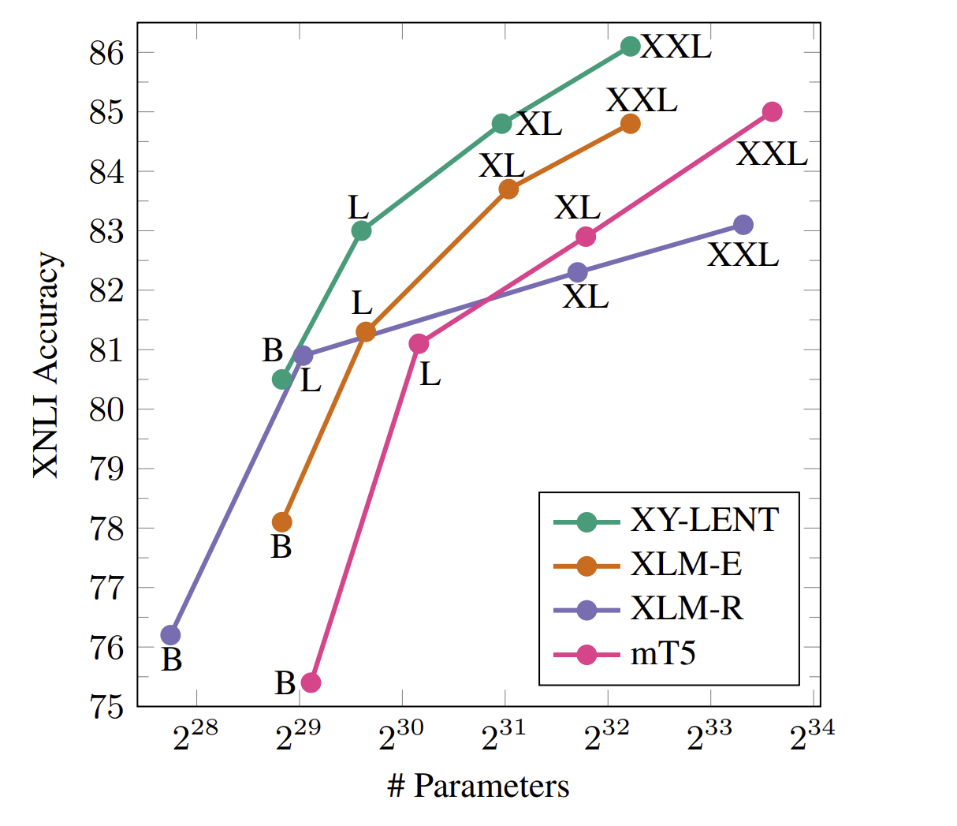
图3:T-ULRv6 (XY-LENT) 在模型规模范围内具有 SOTA 水平,同时具有参数效率
在 T-ULRv6 中,微软亚洲研究院自然语言计算组的研究员们与微软图灵团队紧密合作,为预训练模型的研究和开发以及下游任务的微调算法,提供了关键技术。基于 XLM-E 工作中提出的多语言预训练方法,研究员们成功实现了130倍的收敛提速,为 T-ULRv6 提供了方法框架。此外,针对多语言预训练特有的语种竞争问题,研究员们还提出了 VoCap 准则,以此动态决定多语言词表的分配额度,从而更好地对多语言输入进行表征。基于多语言的一致性准则,微软亚洲研究院的研究员们提出的多语言微调框架 xTune,也更好地实现了跨语言迁移性能。
T-ULRv6 XXL 的另一个显著优势,是它在不牺牲质量或效率的前提下,凭借单一模型即可在英语和多语言任务上同时实现 SOTA 性能。这意味着用户不用再根据自然语言处理任务来选择使用哪个预训练模型,因为 T-ULRv6 XXL 可以很好地处理这两种情况。这就简化了模型选择和部署的过程,也降低了维护多个模型所需的计算和存储成本。
为了实现这一点,T-ULRv6 利用其扩展能力和非英语平行文本对 (non-English bitexts) 优势消除了“多语言诅咒”,即在权衡英语和多语言性能时,常常给多语言模型造成困扰。T-ULRv6 不仅在涵盖一系列英语自然语言理解任务的 GLUE 基准测试中优于专门的英语模型,在覆盖40种不同类型语言和9种跨语言任务的 XTREME 基准测试中也优于专门的多语言模型。此外,T-ULRv6 模型规模也要小得多,这保证了其参数效率和可扩展性。
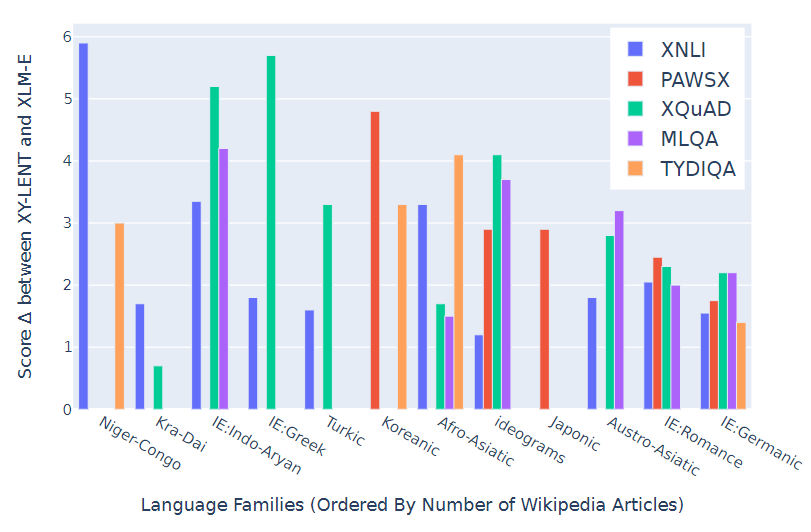
图4:T-ULRv6 (XY-LENT) 在多语言任务中展现出了强大的性能
目前,T-ULRv6 已应用于微软必应 (Bing) 中,为必应的国际化提供支持,使用户能够使用不同语言在不同地区搜索信息。T-ULRv6 还将会把最先进的多语言功能赋能微软其他产品,通过其跨国别和跨语言的能力,助力微软践行“予力全球每一人、每一组织,成就不凡”的使命,为更多用户提供帮助。
微软一直认为 AI 技术要在学术界开放共享,进而促进合作与创新。因此,微软启动了“微软图灵学术计划” (MS-TAP,Microsoft Turing Academic Program),允许科研人员提交研究方案,从而获得 T-ULRv6 和其他图灵模型的详细资料。微软邀请所有人共同探索多语言理解和生成的潜力,一起应对挑战,同时也欢迎大家提供宝贵的反馈和见解。未来,微软还将开源 Base 和 Large 模型,进一步推动该领域的研究工作。
多语言技术不仅是一个技术挑战,更是一项社会责任。微软一直致力于通过消除限制 AI 易用性和包容性的障碍,例如缺乏训练数据、语言建模成本过高以及多语言系统过于复杂等问题,实现 AI 的普及化。T-ULRv6 让 AI 向着这一目标迈出了重要一步,它为跨语言系统开发提供了一个更为高效和可扩展的框架,仅使用一个模型就能同时处理英语和多语言任务。微软很高兴有机会进一步提高技术水平,开发新的多语言能力,让世界各地的更多人和组织从中受益。希望这些工作能够推动社会进步,让 AI 更具包容性,并惠及所有人。
相关链接:
XY-LENT 论文链接:
Beyond English-Centric Bitexts for Better Multilingual Language Representation Learning
https://arxiv.org/pdf/2210.14867.pdf
XLM-E 论文链接:
XLM-E: Cross-lingual Language Model Pre-training via ELECTRA
https://arxiv.org/abs/2106.16138
xTune 论文链接:
Consistency Regularization for Cross-Lingual Fine-Tuning
https://arxiv.org/pdf/2106.08226.pdf
ZeRO 论文链接:
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
https://arxiv.org/pdf/1910.02054.pdf
VoCap 论文链接:
Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training
https://arxiv.org/pdf/2109.07306.pdf
微软图灵学术计划网页:
https://www.microsoft.com/en-us/research/collaboration/microsoft-turing-academic-program/
你也许还想看:







