多模态人工智能大模型“紫东太初”诞生记

不论在现实世界还是神话故事中,
如果任何动物、植物、大石头什么的,
突然能开口跟你说人话,
你一定觉得
这东西成精了、通灵了、闹鬼了,
甚至吓得拔腿就跑。
恭喜你!
你发现了人和其他动物的一大根本区别:

随着社会生活文化演变,
会说话的人类自然而然形成了多种语言,
给这些语言起一个专业的小名词,
就叫:“自然语言”。
比如汉语啦、英语啦、日语什么的,
都是自然语言的一种。

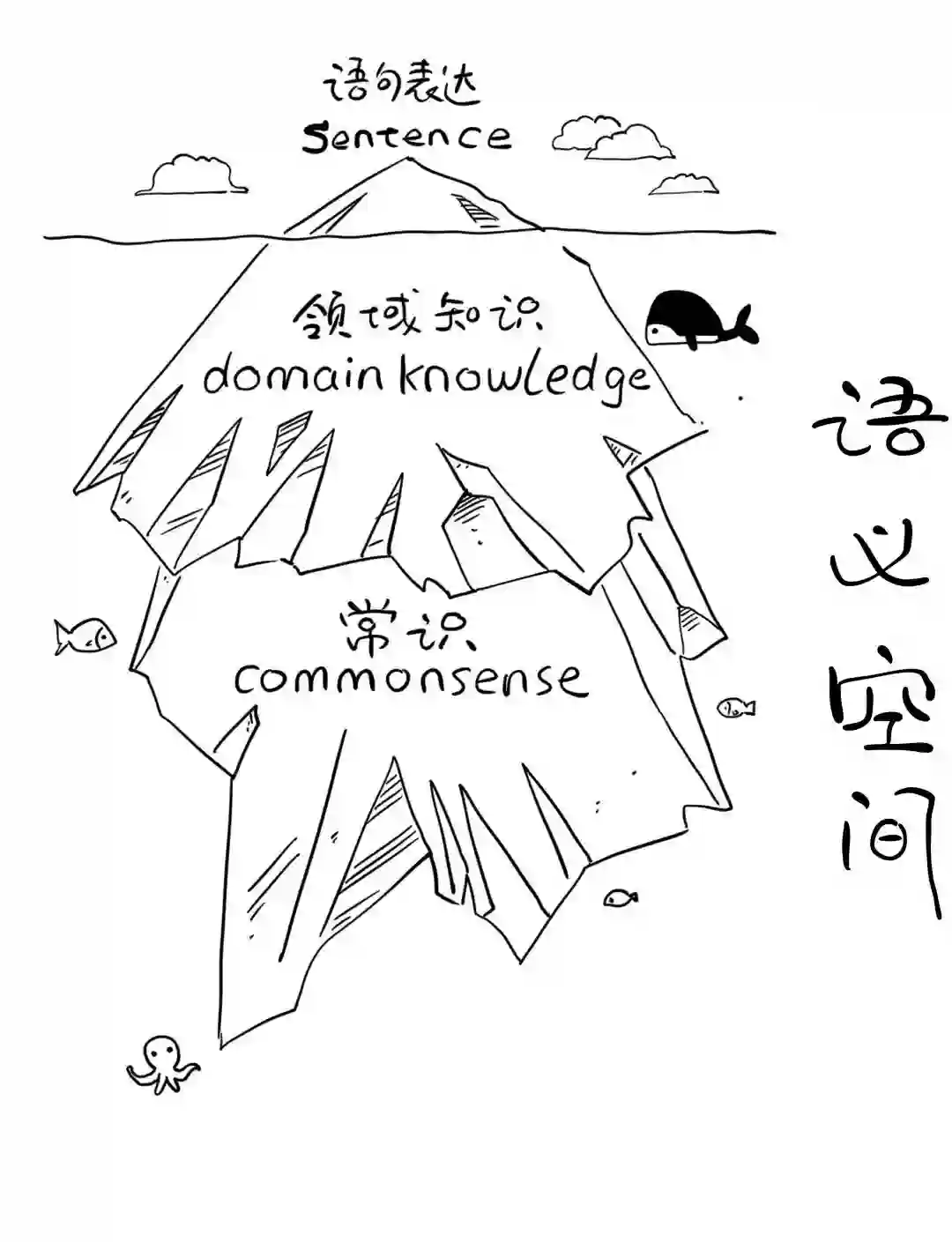
“自然语言”是人类有智慧的表现,
but只是冰山浮出水面的一角。
实际上,想要掌握这种语言,
需要环境、常识、背景知识等多种信息,
我们把这些合起来,统称为“语义空间”。
这就像冰山庞大的水下部分,
容易被忽略,却没它不行。
比如,你想想
自己怎么就自然而然学会说人话了呢?
现在流行的AI就面临
怎么能学会“说人话”的问题。
比如,
说“胖乐吃了一大碗”。
三岁小朋友都听得懂,
这是说胖乐吃了一大碗饭。
但是AI智商不够用的话,
就可能理解成:
胖乐吃掉了一只大瓷碗……

所以AI必须有足够的背景知识,
才能听得懂人话,才能理解自然语言。
这就是AI的“认知冰山”问题。
掌握了冰山庞大的水下部分,
才是人工智能正确学会“说人话”的关键。
也有科学家把“认知冰山”叫做人工智能的
“暗物质”~

更要命的是,我们习以为常的说话聊天,
还包含了语气、语调、断句什么的。
这对于一个智商欠费的AI来说,
是个超级大麻烦。比如:


除了语气、语调、情绪之外,
还有更复杂的图像视频。
人看图很厉害的,有时候要表达一件事,
往往是说话半小时,看图1分钟。
视觉,这对人工智能更是巨大挑战。
我们如何才能同时有效把声音、视觉和文字
这些信息都整合起来呢?
如何让AI像人一样交流、探索?

当很多AI朋友还在吭哧吭哧学“说人话”的时候,
我们的超新星——AI“小初”同学
闪亮登场啦!

小初出身学术豪门,
是由中国科学院自动化研究所的
小姐姐小哥哥们一手创造,
大名叫 “紫东太初”跨模态预训练模型。
这名字就自带主角光环,
是真正的实力派。

AI小初这套大模型包含
图像、文本、语音三个单模态预训模型,
是通过跨模态的关联和生成构成的多模态大模型
在多项下游任务中都有超越业界最好的性能,
构建了全自主人工智能技术体系。
如果AI圈也有武林,
那小初笑傲人工智能江湖,
妥妥的~
AI圈里,
其他的AI同学进行“思考”的时候,
往往只考虑两个“模态”,
比如图像+文本,或者语音+文本。
这种“思考”是有局限的,
因为忽略了周围环境的“语音”信息,
而且在理解和生成输出信息方面逊色。
而中科院自动化所的研究者们
首次将语音信息引入人工智能,
并通过统一语义空间网络表达
生成三模态模型——
图像、语音和文本,三位一体~!
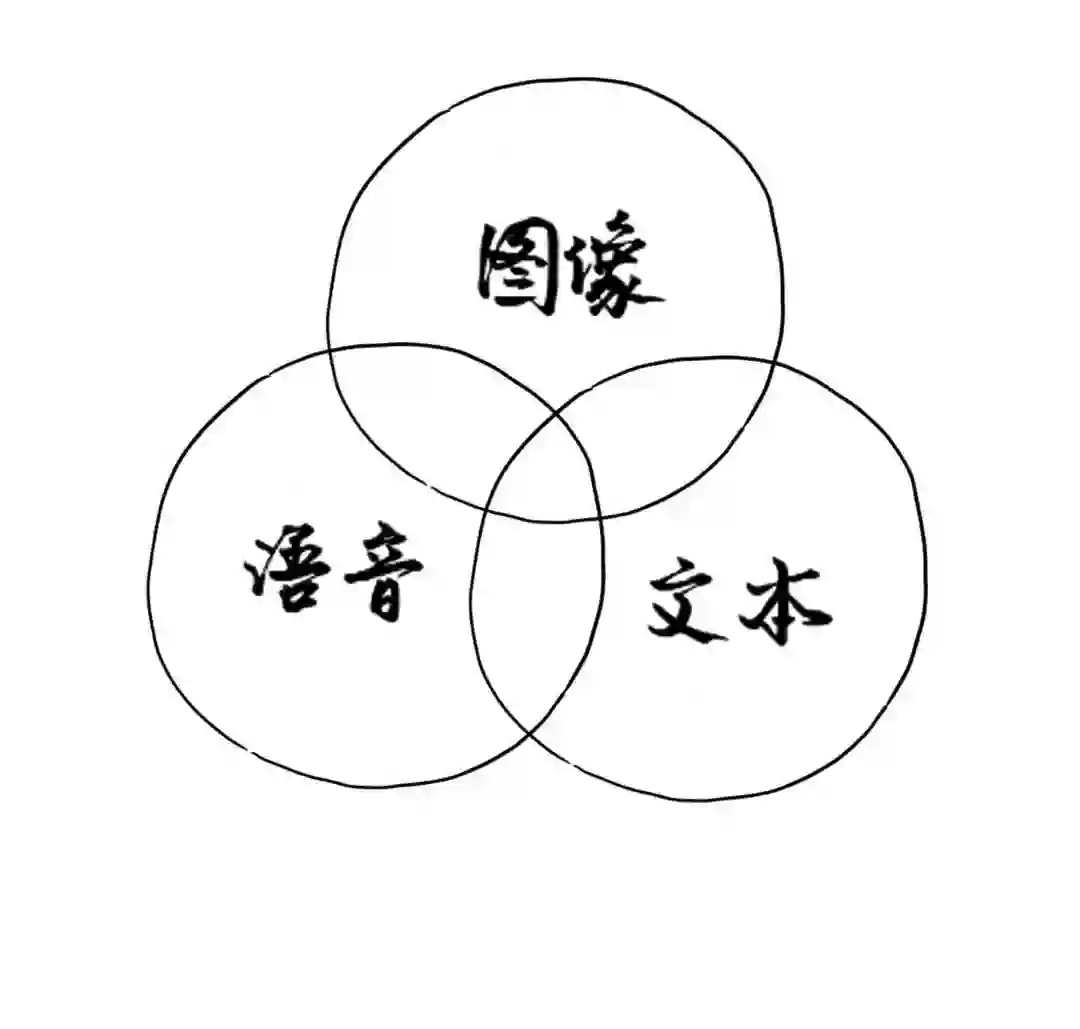
图像、文本和语音三位一体的AI——小初同学
就是科学家们打开
“认知冰山 ”语义空间大门的一个重要尝试
拥有这样强大智慧的小初同学,
就能更加接近人类真正的想象力。

在文本与图像的基础上,
自动化所的研究者们给小初加入了
侧重交互功能的语音“超能力”,
使小初这套大模型一下子变“活”了。
专业说法叫:
使人工智能迈向更高层次的通用型人工智能方向发展

小初有多像人呢?
来来来,
没有对比就没有伤害~


严肃正经地讲,小初同学——
“紫东太初”三模态训练模型
采用多层次多任务自监督预训练的学习方式,
提出三模态数据的语义统一表达,
可同时支持三种、
或者任两种模态的若干数据预训练。

小初不仅可以实现跨模态理解,
还能实现跨模态生成。
如果只能理解,不能生成,
那就是哑巴。
小初做到了理解和生成
两个最重要的认知能力的平衡,
首次实现了“以图生音”和“以音生图”。
不仅能听会说,
而且比两个模态
如图像和文本、或者视频和文本,
更加“能说会道”。
所以在AI世界的“跑分任务拉力赛”中,
小初明显胜过其他只有两个模态的AI同学们。
那么问题来了!
先举一个例子:
一个刚学外语的人,
用外语听说表达的时候,
往往需要现在脑子里翻译成母语,
再翻译成外语。
比如说“苹果”,
要翻译成汉语再到apple,
而熟练之后就不用了,
往往能直接和apple对应。

就像学外语一样,
小初作为一个学习人类语言的AI,
是不是需要图像、文本和语音三个模块之间
经过“翻译”,才能理解呢?
比如,
小初是不是必须把语音先“翻译”成文字,
然后“读”了之后再输出为图片或视频呢?
答案是:NO~

小初独步武林的一个地方就在于,
它完全不用传统文字“翻译”,
而是通过共性的语义空间实现直接交互关联,
即在一个语义空间内将声音直接转换图像。
这跟人类处理信息的方式特别像。

在这个由图像、文本和语音三个模态
共同构建的共性语义空间中,
更加类人的多模态交互得以实现,
语音、图像与文字可以自然流畅转换。
小初就跟一个大活人一样,
语音识别那都是小case,
还能语音合成、描述图像,中文续写
等等等等~

紫东太初这个三模态模型的重点在于:
探索如何更“巧”地学习,
并且有巨大的生产生活应用场景。
比如解说欧洲杯,拍电影生成画面。
总之,
未来会有更多想象力和艺术创造力。
AI小初同学面前,还有慢慢“求学路”,
不过在当前的初级阶段,
小初已经是三好学生啦!

漫画创作 | 胖乐胖乐
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。






