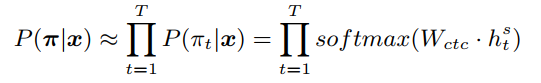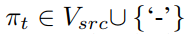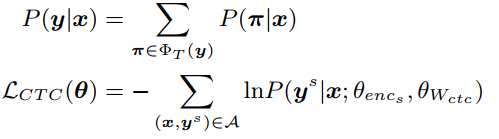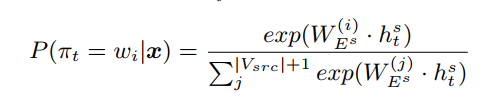在端到端的语音翻译中,虽然预训练配合微调的方法被广泛使用,但两个环节尚且不能很好地进行衔接。微软亚洲研究院提出串联编码网络(Tandem Connectionist Encoding Network, TCEN),使参与语音翻译任务的每个子网络都能够被预训练,且预训练中学到的参数都将在微调过程中使用,从而显著提升语音翻译模型性能。
端到端的语音翻译(Speech Translation, ST)是指将一段源语言语音直接翻译为目标语言的文本,而不产生任何中间表示(比如源语言文本)。随着神经网络的发展,这个任务正受到越来越多的关注。已有工作表明预训练和多任务训练可以显著提升端到端语音翻译的效果,通常的做法是分别在语音识别任务(Automatic Speech Recognition, ASR)和机器翻译任务(Machine Translation, MT)上训练一个编码器-解码器模型,然后将前者的语音编码器和后者的文本解码器组合起来,在语音翻译的任务上进行微调。
然而,这种做法使得预训练和微调过程存在以下三个问题:1. 网络参数浪费,即机器翻译模型中文本编码器学习到的源语言的语法语义知识并没有在后续微调过程中用到,而这部分知识对于翻译任务而言至关重要;2. 网络功能不匹配,语音编码器在预训练中只需要学习语音特征,而在后续任务中则需要学习语法语义知识,任务难度显著增加;3. 端到端语音翻译模型中的注意力机制无法参与预训练。
为了解决以上三个问题,我们提出了一种新的模型结构,称作串联编码网络(Tandem Connectionist Encoding Network, TCEN)。这种结构能够使参与语音翻译任务的每个子网络都能够被预训练,且预训练中学到的参数都将在微调过程中使用。和传统的预训练、多任务学习的模式相比,我们提出的网络结构和训练方法可以显著提升语音翻译模型的性能。
下文中,我们用 x=(x_1,x_2,…,x_(T_x )) 来表示输入的语音特征,y^s=(y_1^s,y_2^s,…,y_(T_s)^s) 表示源语言文本,y^t=(y_1^t,y_2^t,…,y_(T_t)^t) 表示目标语言文本。在训练中,共有三种可用数据集,ASR 数据集 A=(x,y^s ), MT 数据集 M=(y^s,y^t ) 和 ST 数据集 S=(x,y^t)。我们的目标是训练一个端到端模型,能够直接从 x 生成 y^t。
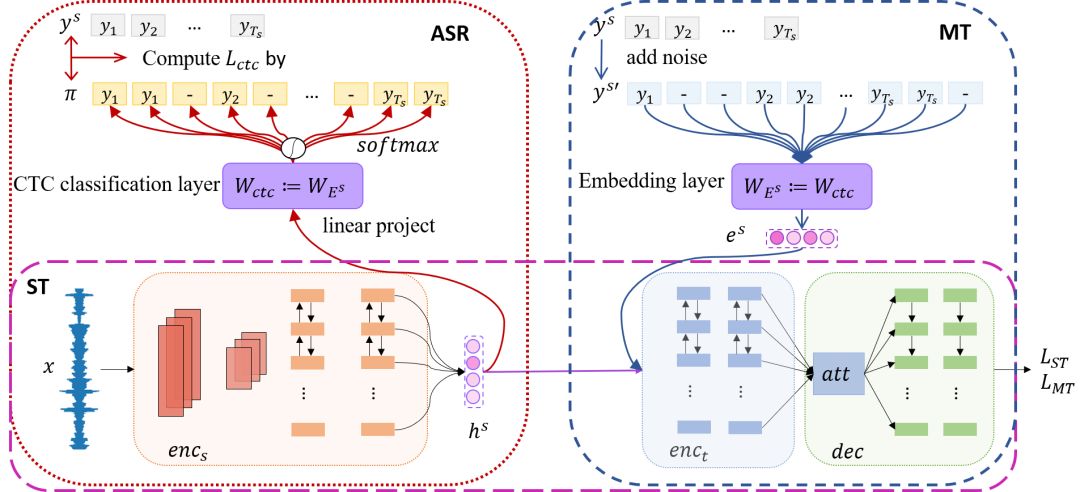
我们的模型结构如图1所示,它共包含两个编码器:语音编码器enc_s和文本编码器enc_t, 以及一个解码器dec。其中语音编码器的作用在于将语音特征进行编码,转换至源语言的词向量空间。文本编码器将词向量编码,学习更深层的语法语义知识,解码器将根据编码器生成的隐向量解码生成目标语言文本。两个串联编码器的设计使得学习语音特征和学习语言学特征的任务分离开,这样预训练任务中学到的所有知识都能够被利用。然而,这种设计导致了子网络不一致问题,我们将在后文介绍并提出解决方案。
在预训练中,对于 ASR 任务来说,我们去除了原本的解码器,利用 CTC (Connectionist Temporal Classification)损失函数训练编码器。给定一个输入语音序列 x,语音编码器产生一个隐向量序列 h^s, 接着一个 softmax 分类层预测出一个 CTC 路径 π,其中每一个符号都属于源语言词表或为空符号‘-‘,即:
一个合法的 CTC 路径是源语言句子的一个变体,其中允许出现空符号,或多个符号的重复,如下表1示例:
表1:给定语音对应文本,合法 CTC 路径的两个例子
CTC 目标函数将最大化正确句子对应的所有合法路径的概率和:
对于机器翻译任务而言,我们则按照通常做法训练一个编码器-解码器结构的神经机器翻译模型。
在微调过程中,我们利用预训练的网络模块初始化一个 TCEN 网络结构,并交替训练语音识别、机器翻译和语音翻译三个任务。对于每一种任务,我们给它分配一个更新比例 α,并依照 α_i/(∑_j ·α_j ) 的策略随机选择一个任务 i。
将两个编码器串联相接的方法会存在子网络不一致问题:语义不一致和长度不一致。具体而言,语音编码器和文本编码器在预训练中是单独训练的,而在微调过程中两个编码器直接相连,无法保证语音编码器的输入和原本文本编码器的输入处于同一空间内,另一方面,语音序列的长度比文本要长的多,导致文本编码器在不同任务中将接收不同长度的输入。针对这两个问题,我们分别提出了如下解决方案。
为了得到语义一致性,我们在预训练过程中共享语音识别模型中的 CTC 分类层参数和机器翻译模型中的源语言词向量参数,通过参数共享,在预测 CTC 路径时,观测到某一个标签的概率与语音编码器输出隐向量和该标签词向量的点积成正相关,即:
该目标函数拉近了该隐向量和正确的词向量之间的距离,使得 h^s 和机器翻译中的词向量属于同一种分布。
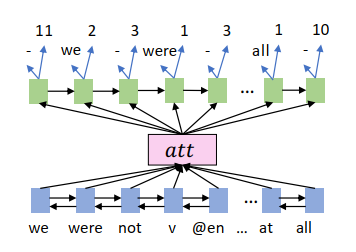
为了获得长度一致性,我们对机器翻译的数据进行了预处理,通过在源语言句子中添加重复和空符号,模拟 CTC 路径的格式。为了达到这个目的,我们训练了一个 seq2seq 模型,该模型同时预测出现的词以及重复的次数,如图2所示:
接着我们使用该模型处理 MT 数据集 M 并得到一个源语言带有噪声的伪数据集 M', 在训练 MT 模型时,我们交替从 M 和 M’ 中采样。
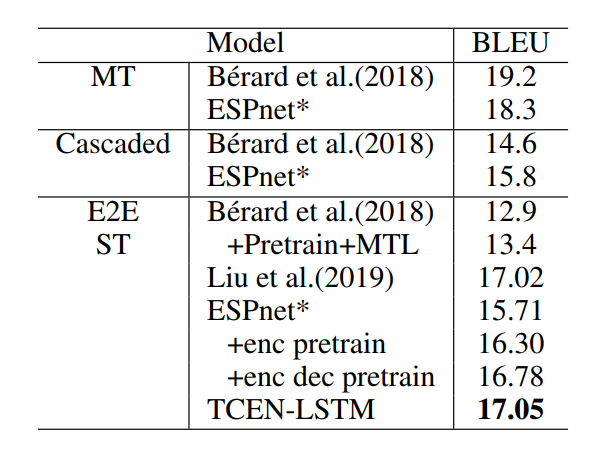
1. 在 IWSLT18 En-De 数据集上基于 LSTM 的实验结果
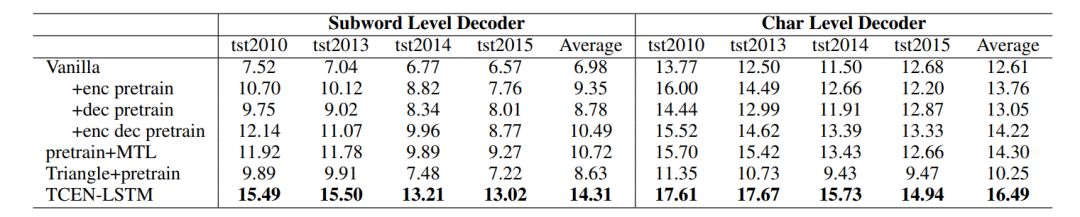
在本实验中,我们采用了 LSTM 的结构,并采用了 subword 和 character 两种解码方式进行实验。我们利用 TEDLIUM2 作为扩充 ASR 数据集,WMT18 En-De 和 WIT3 作为扩充 MT 数据集,实验结果如表2所示:
表2:IWSLT18 En-De 数据集上基于 LSTM 的实验结果
表2显示,和传统的预训练以及多任务学习方式相比,我们的方法显著提升了翻译性能。
2. 在IWSLT18 En-De 数据集上基于 Transformer 的实验结果
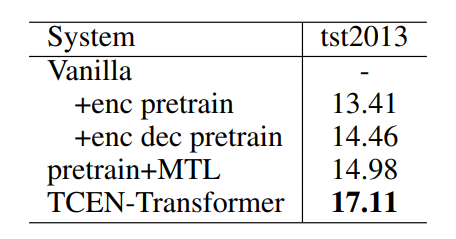
为了证明 TCEN 模型框架的适用性,我们进一步采用了 Transformer 的模型结构进行实验,在该实验中,我们仍使用 TEDLIUM2 作为扩充 ASR 数据集,仅使用 WIT3 作为 MT 数据集,并在 tst2013 上进行测试。实验结果如表3所示:
表3:IWSLT18 En-De 数据集上基于 Transformer 的实验结果
该结果证明我们的框架在 Transformer 结构中依然有效。
3. 在 Librispeech En-Fr 数据集上的实验
在该实验中,我们使用了基于 LSTM 的网络结构,没有利用额外数据进行 ASR 及 MT 模型的预训练。
表4:Librispeech En-Fr 数据集上基于 LSTM 的实验结果
实验结果表明,在数据量小的情况下(100h ASR, 40k MT),我们的方法依然有效。
01. 时间可以是二维的吗?基于二维时间图的视频内容片段检测
02. 全新视角,探究「目标检测」与「实例分割」的互惠关系
03. 新角度看双线性池化,冗余、突发性问题本质源于哪里?
04. 复旦大学黄萱菁团队:利用场景图针对图像序列进行故事生成
05. 2100场王者荣耀,1v1胜率99.8%,腾讯绝悟 AI 技术解读
06. 多任务学习,如何设计一个更好的参数共享机制?
07. 话到嘴边却忘了?这个模型能帮你 | 多通道反向词典模型
08. DualVD:一种视觉对话新框架
09. 清华大学:借助BabelNet构建多语言义原知识库
![]()
招 聘
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiawei@leiphone.com
![]()
![]() 点击“阅读原文” 加入 观看 AAAI 预讲直播视频
点击“阅读原文” 加入 观看 AAAI 预讲直播视频