新预训练模型CodeBERT出世,编程语言和自然语言都不在话下,哈工大、中山大学、MSRA出品
选自arXiv
机器之心编译
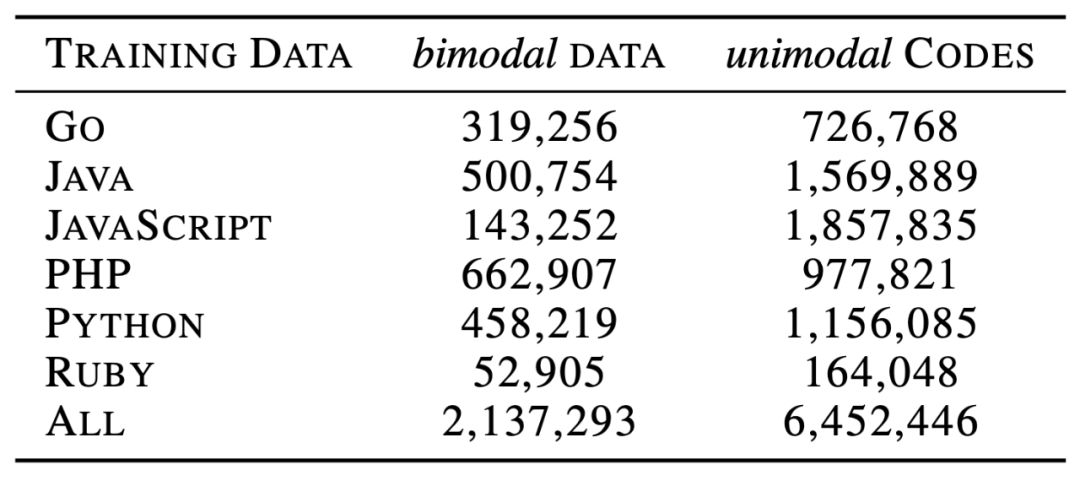
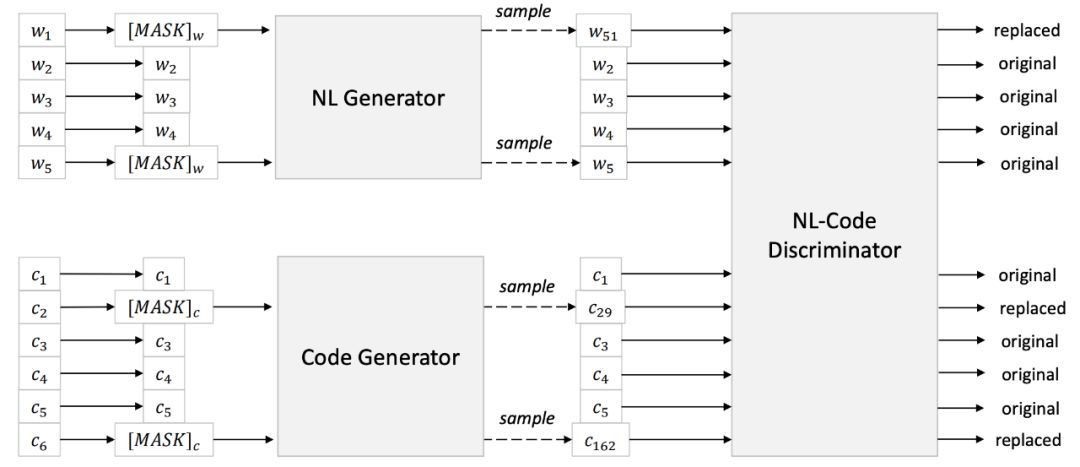
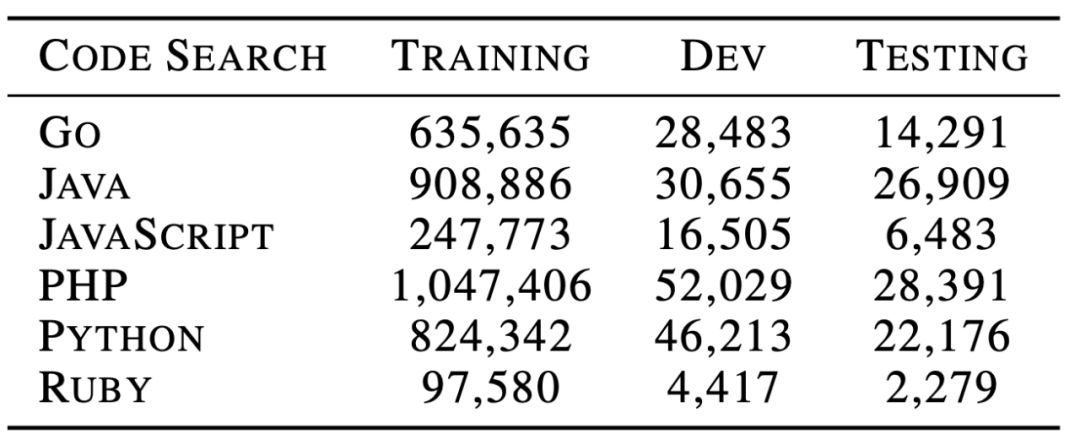
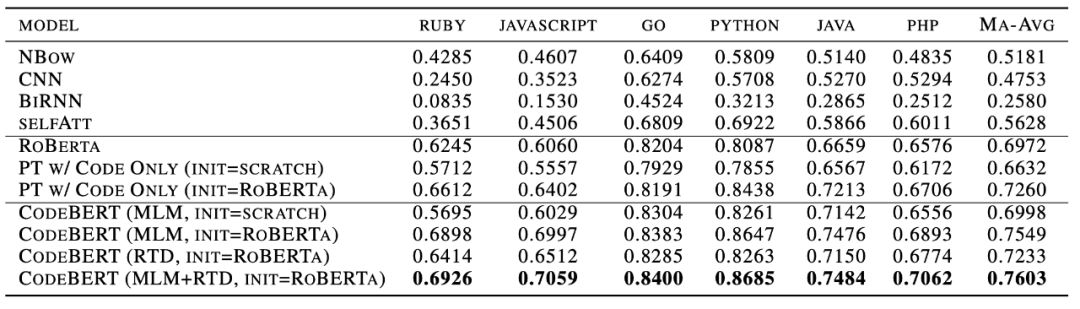
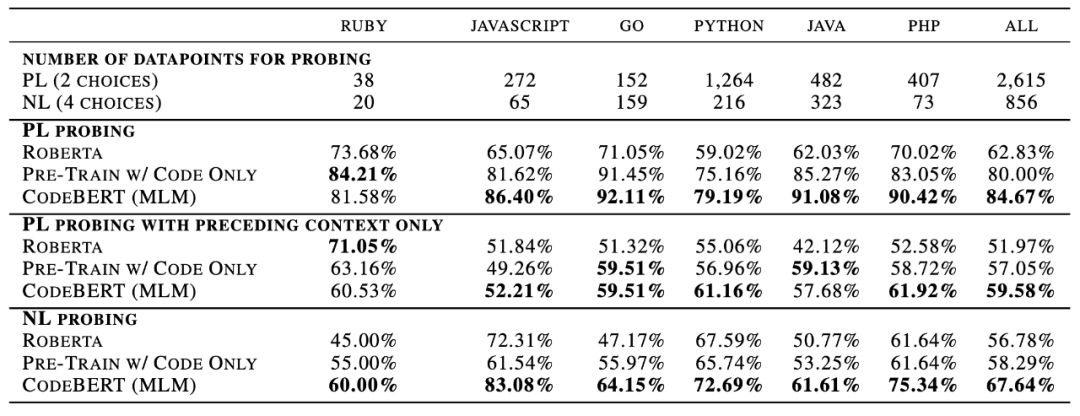
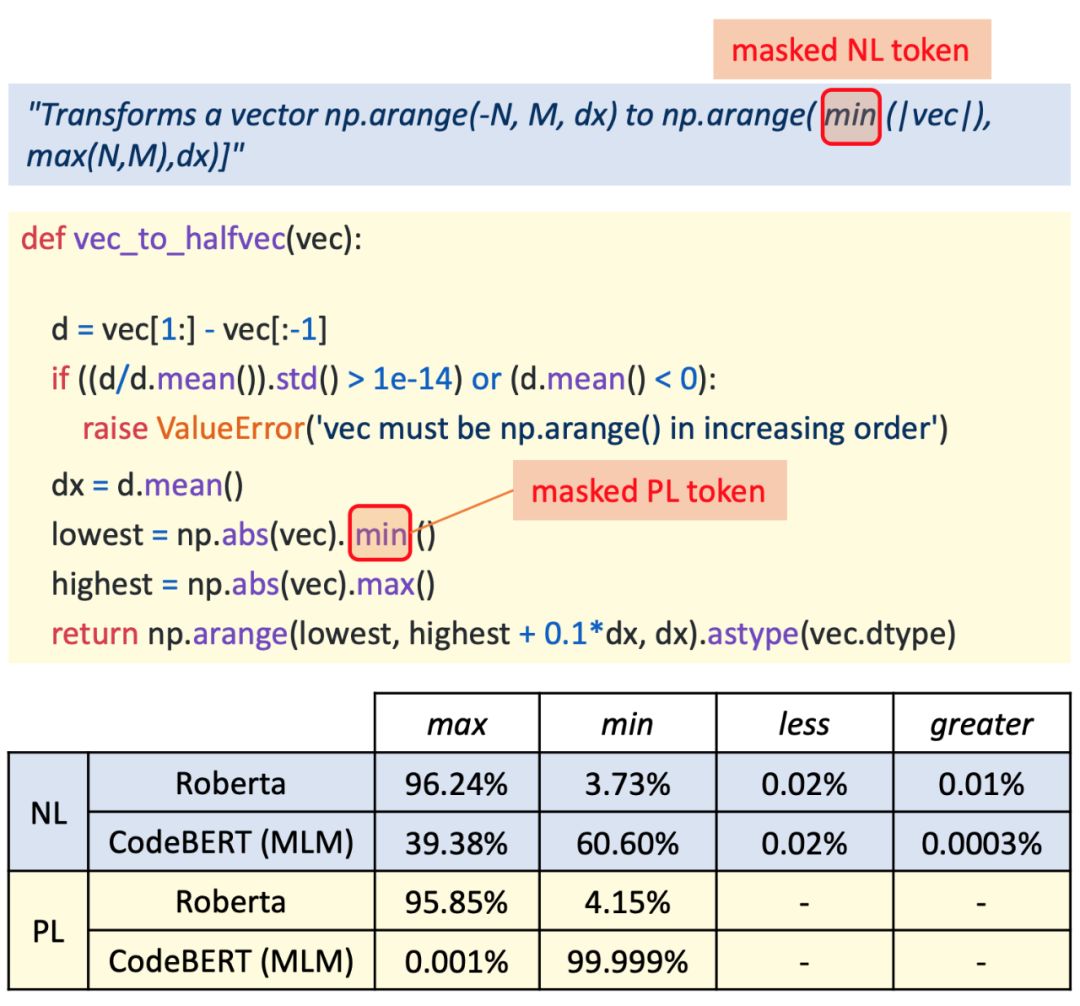
对于自然语言处理从业者来说,BERT 这个概念一定不陌生,自从诞生以来,它在诸多任务检测中都有着非常优秀的表现。 近日,来自哈尔滨工业大学、中山大学和微软亚洲研究院的研究者合作提出了一个可处理双模态数据的新预训练模型 CodeBERT,除了自然语言(NL),编程语言(PL)如今也可以进行预训练了。



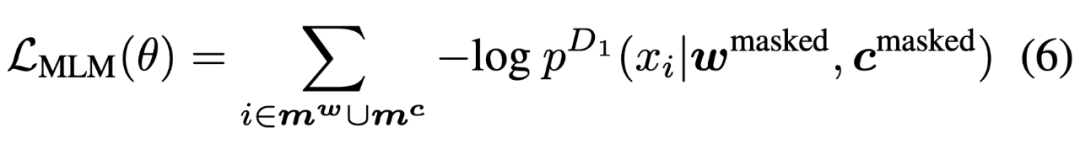
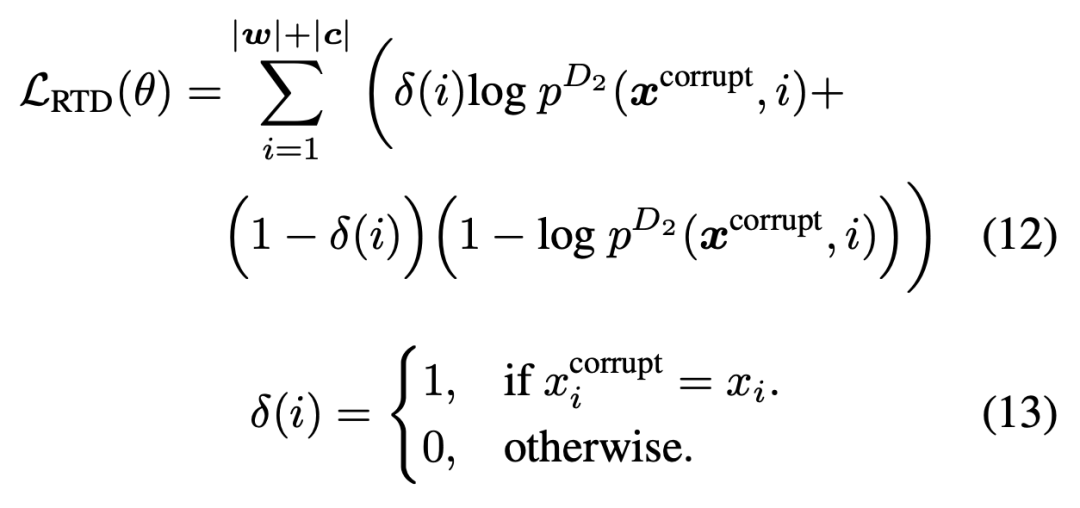
登录查看更多
相关内容
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
4+阅读 · 2018年8月29日




相关VIP内容
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年8月29日