【泡泡图灵智库】实时的同时三维重建和光流估计(WACV)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Real-Time Simultaneous 3D Reconstruction and Optical Flow Estimation
作者:Menandro Roxas Takeshi Oishi
来源:2018 IEEE Winter Conference on Applications of Computer Vision
播音员:四姑娘
编译:张国强
审核:汤文俊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——实时的同时三维重建和光流估计,该文章发表于2018 IEEE Winter Conference on Applications of Computer Vision。
我们提出了一种在变分框架中求解两个视图的运动立体问题的替代方法。我们通过最小化由光流约束和光流约束组成的联合能量函数来同时估计光流和三维结构,而不是直接求解深度3D约束。与立体视觉方法相比,我们将极线几何形状强加为软约束,这使得搜索空间更具灵活性,而不是简单地跟随极线,使得对于姿态估计中的小误差能够更加精确的应对。这种方法还允许我们使用快速密集匹配方法来处理3D表面上的大位移以及基于形状的平滑度约束。我们在结果中表明,就准确性而言,我们的方法在两帧变分深度估计方面优于现有技术方法,并且与现有光流估计方法的结果相当。通过我们的实施,我们能够使用现代GPU实现实时性能。
主要贡献
在本文中,我们提出了一种变分方法,用于最小化迭代框架中嵌入的联合能量函数。 与经典的变分立体方法相比,我们的方法可以实现更精确的3D重建。 我们还提供了一种实现实时性能的方法。
在这项工作中,我们专注于解决两帧的重建问题。 尽管存在许多多视图方法可以提供更准确的重建结果,但我们将扩展和比较留给多视图问题以供将来工作。
算法流程

图1 算法结果对比图
上图将极线几何作为软约束应用与经典变分立体方法相比的稳健性。与我们的方法相比,将相机姿态的平移向量改变5°会导致中的视差误差(错误像素的百分比> 3)显着增加。
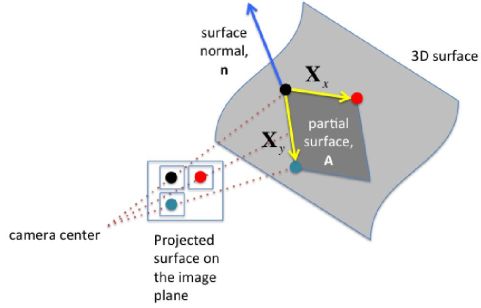
图2 最小的表面正则化器

图3 重建结果(点)
(a)从没有3D正则化器[1]的光流估计获得的对应关系中重建。(b)重建后应用3D正则化。(c)使用我们的方法重建。
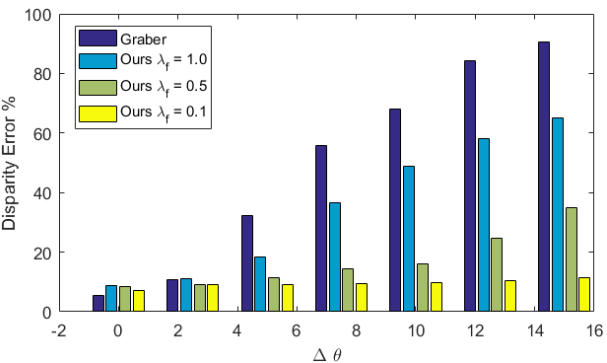
图4 差异误差与姿态变化。
主要结果
我们发现,在NVIDIA TITAN X GPU上,预测320x256色彩的表面法线和遮挡边界需要约0.3秒。 在英特尔至强2.4GHz CPU上解决深度的线性方程式需要约1.5秒。
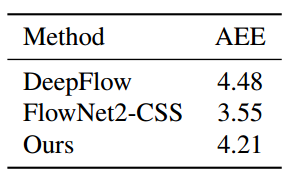
表1 方法比较
在DeepFlow,FlowNet2和我们的方法中,光学流量结果的KITTI2012数据集比较的AAE(平均端点误差)。 由于姿势估计中的错误,我们的方法稍微降低了FlowNet2-CSS的结果。
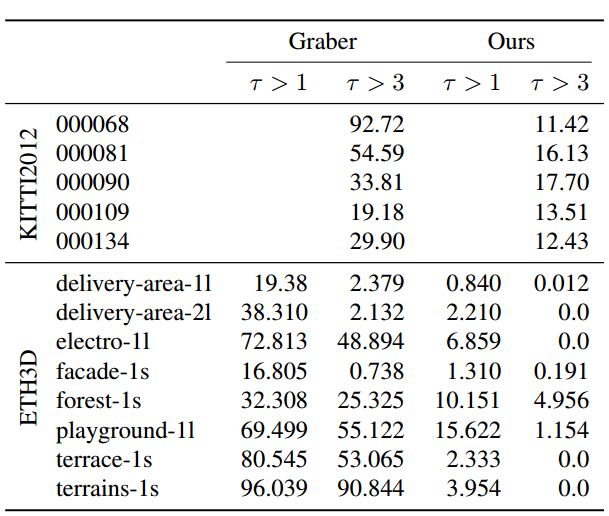
表2 比较原方法和我们的方法对选定的KITTI2012和ETH3D数据集的深度结果,显示Out-Noc度量τ。

图5 光流和Out-Noc(非遮挡区域中错误像素的百分比)是针对DeepFlow ,FlowNet2-CSS 和我们的方法的KITTI 2012的单目训练集产生的。
本文提出的方法是比较深度估计设置下的最先进的方法。 我们的方法不仅产生准确的深度值,而且还产生如表面法线中所反映的大尺寸几何结构
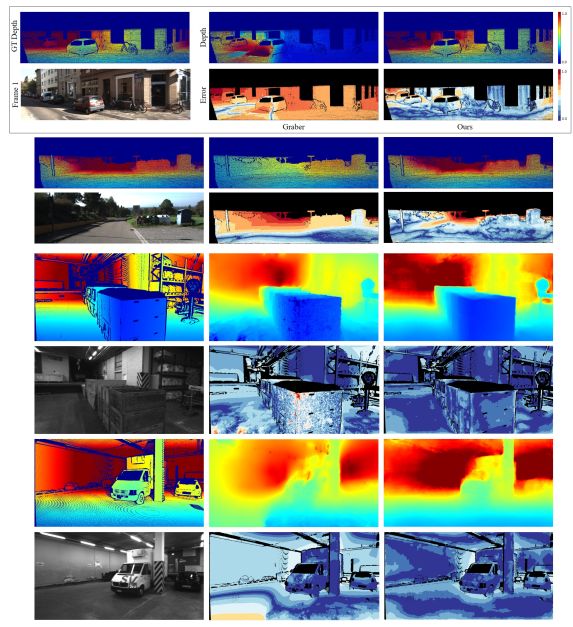
图6 实验对比结果
上图表 使用类似的估计(KITTI2012)和地面实况(ETH3D)姿势比较Graber 和我们的方法之间的深度(标准化颜色)。 从上到下:KITTI2012 000068,000081; ETH3D递送区域-1l,递送区域-2l

Abstract
The goal of our work is to complete the depth channel of an RGB-D image. Commodity-grade depth cameras often fail to sense depth for shiny, bright, transparent, and distant surfaces. To address this problem, we train a deep network that takes an RGB image as input and predicts dense surface normals and occlusion boundaries. Those predictions are then combined with raw depth observations provided by the RGB-D camera to solve for depths for all pixels, including those missing in the original observation. This method was chosen over others (e.g., inpainting depths directly) as the result of extensive experiments with a new depth completion benchmark dataset, where holes are filled in training data through the rendering of surface reconstructions created from multiview RGB-D scans. Experiments with different network inputs, depth representations, loss functions,optimization methods, inpainting methods, and deep depth estimation networks show that our proposed approach provides better depth completions than these alternatives.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



