赛尔原创 | EMNLP 2018 抽象语义表示中使用基于转移的方法学习词到概念映射
本文介绍哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)录用于EMNLP 2018的论文《An AMR Aligner Tuned by Transition-based Parser》中的工作。
论文作者:刘一佳,车万翔,郑博,秦兵,刘挺
1 简介
将自然语言分析成机器可以理解的语义表示是自然语言处理的长期以来的一个目标,抽象语义表示(AMR)是这些语义表示方式中的一种。AMR中的“抽象”指的是自然语言以句子为单位被抽象成语义图(如图1,节点表示概念,边表示概念与概念的关系)。这种抽象给标注过程带来了一定的自由。标注者在标注过程中不需要关心原始句子中词级别的语义。
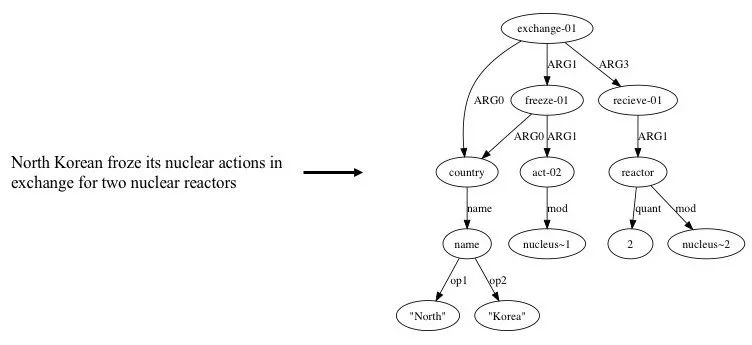
图1. 一个AMR的示例
句子级的抽象是AMR的特点,也是给AMR分析带来了诸多困难。现阶段,大部分的句法语义分析算法是以词为最小单位设计的,主流的AMR分析算法也不例外。Flanigan et al. [2014]提出的算法是目前大部分AMR分析算法的基础。他们的算法可以归纳为两步:首先从输入句子中识别出语义图中应该包含的概念,然后为这些概念建立关系。这种算法设计依赖于一个词到概念的映射。只有知道一个词对应哪个概念,我们才能训练概率模型自动完成从输入句子中识别出语义图中应该包含概念的目标。
那么怎样才能知道一个词对应哪个概念呢?Flanigan et al. [2014]给出了一个方案:从训练数据输入的句子和图中“猜”这种对应关系(alignment)。图2给出一个猜alignment的例子。经过数年的发展,Flanigan et al. [2014]提出的猜alignment的方法已经成为诸多AMR语义分析的基础。然而,他们的alignment远非完美。他们的“猜”法可以总结为贪心地匹配一个词与所有概念,这意味着输出唯一的alignment结果。为了提高准确率,他们的方法放弃召回一些如action到act-01的alignment;同时,alignment的好坏,对于下一步建立概念关系的模型的学习会产生怎样的影响,这些都没有考虑。这使得在人工标注的少量alignment数据中,他们的方法只有90%的准确率。
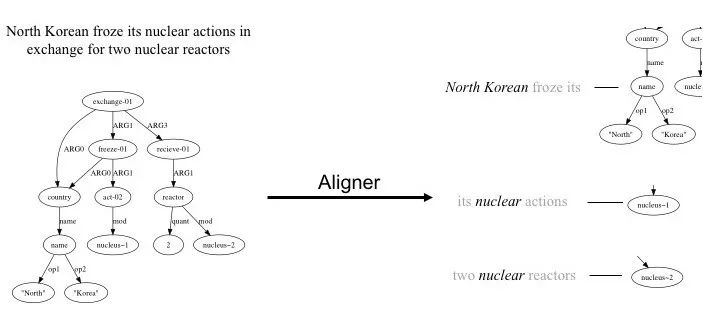
图2. 从训练数据输入的句子和图中“猜”这种对应关系
而本文要做的就是提高alignment的准确率,进而提高AMR分析的性能。我们的思路可以概括成:
• 在Flanigan et al. [2014]的基础上取消“贪心匹配”过程。并用外部资源增加匹配的召回率,使得算法可以输出多个alignment候选;
• 用一个oracle parser决定上面输出的alignment哪个最好。oracle parser会保持某个alignment结果的前提下根据训练数据尽可能找到分数最高的alignment。
上面的过程可以用图3来描述。 通过这种方法,我们得到了准确率更高的alignment,并且帮助提高了AMR分析的准确率。
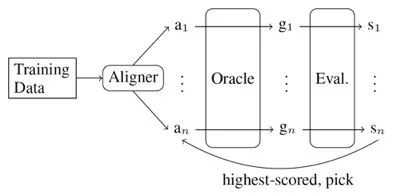
图3. 本文算法框架,其中a代表alignment,g代表AMR图,s代表AMR图比照黄金AMR图的分数。
2 实验
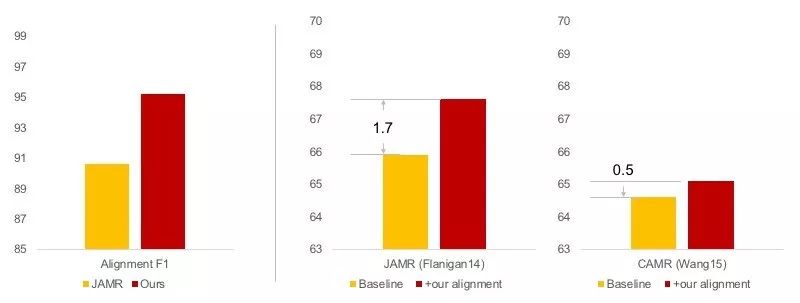
图4. (左)手工标注alignment的准确率,(右)不同的alignment对于最终AMR分析性能的影响。
我们分析了我们的alignment在手工标注数据上的准确率。其结果如图4所示。我们的alignment优于Flanigan et al. [2014]。然后,我们将开源两个系统(JAMR:Flanigan et al. [2014],CMAR:Wang et al. [2015])中的alignment替换为我们的alignment并比较得到的parser的性能。可以看出,我们的alignment可以稳定地提升两个开源AMR分析器的性能。
3 拓展阅读
想要更多地了解算法的细节,欢迎参考我们的论文。同时,本文的oracle parser是基于Choi and McCallum [2013]提出的使用cache处理非投射依存句法树(nonprojective dependency tree)的算法设计的。我们也在此基础上设计了自己的基于转移的AMR分析器。实验表明,这种基于转移的分析器速度快、准确率高。如果读者对于实验细节感兴趣,也欢迎参考我们的开源代码:https://github.com/Oneplus/tamr。
References
Jinho D. Choi and Andrew McCallum. Transition-based dependency parsing with selectional branching. In Proc. of ACL, 2013.
Jeffrey Flanigan, Sam Thomson, Jaime Carbonell, Chris Dyer, and Noah A. Smith. A discriminative graph-based parser for the abstract meaning repre- sentation. In Proc. of ACL, 2014.
Chuan Wang, Nianwen Xue, and Sameer Pradhan. A transition-based algorithm for amr parsing. In Proc. of NAACL, 2015.
点击文末“阅读原文”查看往期精彩原创推送。
本期责任编辑:张伟男
本期编辑:吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




