赛尔原创 | 基于连通图的篇章级事件抽取与相关度计算
摘要:事件抽取及基于此的事件相关度计算在自然语言处理领域有着非常广泛的应用前景。然而,当前对事件的研究大多数着眼于句子级别。事实上,在很多应用中,尤其是面向真实的需求,篇章级的事件分析更有影响力。为此,本文在句子级事件抽取的基础上,提出一种篇章级的事件相关度计算方法,利用句子级事件的抽取结果构建篇章事件连通图,然后选取图中重要的节点作为篇章级事件的代表,之后通过计算两篇文章在篇章事件连通图上的重合程度确定篇章级事件的相关度。
关键词:篇章事件连通图;PageRank;篇章级事件相关度
1. 前言
篇章级事件抽取是抽取出最能代表篇章核心内容的事件。篇章级事件不一定是出现频率最高的事件,但篇章中的所有事件,都一定都是围绕核心事件展开的,即篇章中的所有事件都一定与核心事件有关联。篇章级事件抽取可以通过将句子级事件抽取结果叠加来实现。然而,一篇文章 往往描述了多个事件,简单叠加句子级事件抽取的结果无法获取篇章的核心事件。这一观察显示了研究从篇章级研究事件抽取的重要性。好的篇章级事件抽取模块可以更好地对篇章进行建模,从而更好地服务于事件相关度计算。
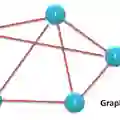
在一篇文档中,同一实体可以与多个事件对应(见下图)。以实体为桥梁,篇章中的事件可以使用篇章事件连通图进行建模。对事件联通图进行挖掘,就可以得到篇章级别的重要信息。本文研究了如何使用PageRank的方法进行挖掘。

图 1通过篇章“特朗普携夫人访问英国。特朗普与首相共同接受记者采访。女王在白金汉宫举办欢迎晚宴。”构建的篇章事件连通图。
通过抽取篇章级事件,两个篇章的相似度可以根据结果中的事件元素、触发词的相似性进行建模。事件元素的相似度计算相对容易,触发词的相似度计算则面临相同语义不同表述的问题。比如“打球”中的“打”与“投篮”中的“投”在比赛这个特定领域中语义相似。然而,这种相似性通常难以通过词表示(Word embedding)或者语义资源(VerbNet)等进行刻画。为了克服这类问题,我们提出了基于VerbNet的连通图方法以构建特定领域的词语分类体系,利用此分类体系确定触发词之间的相关性,进而确定篇章级事件的相关性。
2. 算法流程
篇章级的事件表示以句子级事件为基础,将句子级事件的触发词和事件元素作为节点,首先构造句子级事件多边形,再根据节点共现以及词语的词义相似或相关性将事件多边形连接起来构造篇章级的事件连通图。之后,使用随机游走算法确定篇章级事件连通图中节点的权重,根据权重提取出相对于文章来说最重要的若干节点。由于文章的标题(尤其是新闻标题)能够标识文章的主题,因此单独对文章标题提取事件触发词及事件元素。将从篇章连通图中提取出的权重较高的节点和从文章标题中提取中的触发词和事件元素取并集,通过计算两篇文章对应的集合的重合度确定两篇文章的篇章级事件相关度。算法流程图如下:
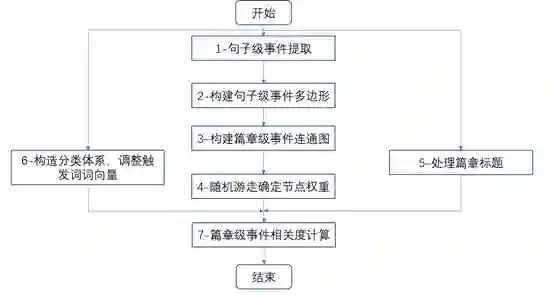
图2 本文算法流程
3. 事件抽取
3.1 句子级事件提取
本文以句子级事件的提取为基础构建篇章级事件表示。具体而言,即是以句子级的事件触发词和事件元素作为篇章级事件连通图的节点。因此句子级事件的触发词和事件元素的提取不需非常准确,但是需尽可能涵盖丰富的信息,以供连通图挖掘。考虑到提取速度,我们利用句法树结构,融合依存句法分析和短语结构句法分析,按照预先设定的提取规则从句法树中进行事件触发词和事件元素的识别。
3.2 句子级事件多边形的构建
将第一步提取出的事件触发词、事件元素(名实体、时间、地点以及有意义的补语状语等)作为节点,连接成一个具有中心节点的封闭多边形。比如句子“特朗普携夫人访问英国。”中提取出事件元素“特朗普”、“夫人”、“英国”,提取出事件触发词“访问”,首先将“访问”与“特朗普”、“夫人”、“英国”分别相连,再将“特朗普”、“夫人”、“英国”按照在句子中出现的先后顺序依次连接起来。构成图形如下:
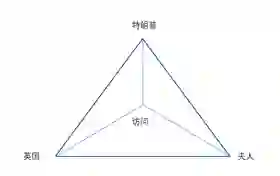
图3一个句子级事件多边形的例子
这样,整个句子级事件就用一个带有中心节点的封闭三角形表示出来了。如果一个事件具有n个事件元素,则该事件表示为一个具有中心节点n边形。
3.3 篇章级事件的连通图的构建
跨事件的节点链接有两种方式,第一种是如果一个事件元素既出现在一个事件中又出现在另一个事件中,则这两个事件多边形共用一个节点。第二种是如果两个多边形中有某两个节点的余弦相似度的值超过预先设定的阈值,则将这两个节点连接在一起。图1显示了一个事件连通图的例子。
3.4 随机游走(PageRank)计算节点的权重
本文利用PageRank计算图中节点的权值代表该节点作为篇章级事件表示的可能性,步骤如下:
1)在初始阶段:每个节点设置相同的PageRank值,通过若干轮的计算,会得到每个节点所获得的最终PageRank值。随着每一轮的计算进行,节点当前的PageRank值会不断得到更新。当迭代次数达到一个阈值或者权重的变化程度小于一个阈值,停止更新。
2)更新节点的PageRank值:每个节点将其当前的PageRank值平均分配到本节点包含的出链上,这样每个链接即获得了相应的权值。而每个节点将所有指向本节点的入链所传入的权值求和,即可得到新的PageRank值。当每个节点都获得了更新后的PageRank值,就完成了一轮PageRank计算。
3.5 篇章标题的处理
对标题的处理与对句子的处理类似,根据依存句法分析及短语结构句法分析相结合的方式提取标题中的触发词及事件元素,作为计算篇章相似度的部分依据。
至此,本文对一篇文档的篇章级事件进行了抽取。接下来介绍如何为计算两篇文档的相似度构造特定领域的动词分类体系,以及如何计算两篇文档的相似度。
4. 构造特定领域的动词分类体系
同一个词语在不同语境下具有不同的含义。比如“踢”这个词,在“社会类新闻”中具有这样一句话,“嫌疑人A踢中受害者B的头部致其死亡”,此时“踢”具有和“打”相同的含义;但是在一篇“体育类新闻中”,“球员A将球踢进球门赢得一分”,此时“踢”与“射”具有相同的含义。由此可见,相同的动词在不同领域中具有不同的语义,会与不同的词语处于同一类别中。为此,我们搭建基于VerbNet和连通图的特定领域动词聚类框架以提高事件相关度计算的准确率。
首先生成词汇聚合


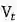
构造词对集合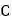
根据集合
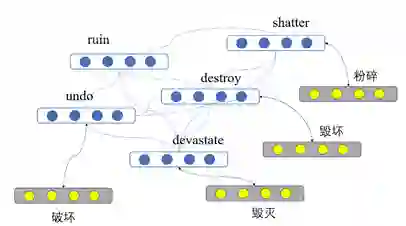
图4 词对连通图示例
当两个目标领域的动词通过同义约束连接到同一个英语单词,或者两个目标领域的动词通过同义约束连接到两个不同的英语单词,但是这两个英语单词又通过吸引约束连接在一起时,将这两个目标领域的动词词向量
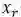
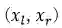
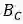
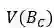
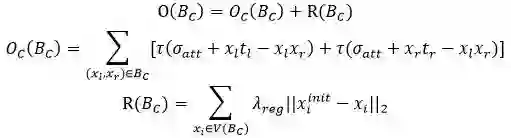
损失函数包含两个部分:
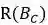
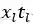
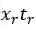
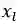
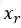
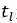

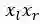
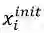
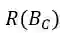
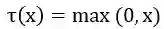
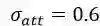
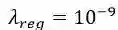
表1 词篇章矩阵


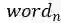
其中
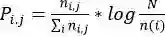
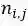
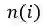
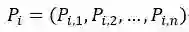
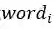
构造连通图,连通图的每一个节点代表一个词语,节点之间的边的权重


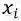
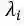
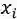
采用PageRank算法计算每一个节点的权重,当权重收敛后,将节点权重与第一步通过VerbNet训练得到的节点对应词语的词向量相乘得到新的节点向量表示。
5. 根据篇章连通图及标题计算篇章级事件的相关度
根据权重大小对连通图中的节点进行三类排序:把文章中所有的名实体按照权重大小进行排序、把文章中的触发词按照权重大小进行排序、把文章中的所有节点按照权重大小进行排序。将每个排行榜上的前五个词提取出来作为篇章级事件的代表。分别计算两篇文章的前五个篇章名实体的余弦相似度的均值、前五个篇章触发词的余弦相似度的均值(触发词的词向量为第6步得到的结果)、前五个词语的余弦相似度的均值、标题触发词的余弦相似度(触发词的词向量为第6步得到的结果)、标题名实体的余弦相似度均值、标题词语的余弦相似度的均值,并将这六项求和。得到的值作为两篇文章的篇章级事件的相关度。
6. 实验效果、评价方法及未来工作
为验证算法的性能,我们初步在具备27个标签的包含200篇体育新闻的测试集上进行了实验。我们随机从每个标签对应的新闻集合中选择新闻,组成了20000对新闻对作为测试集,然后手工标注,选择了其中6000对相关新闻和10000对不相关的新闻作为测试集。
针对篇章级事件提取任务,我们设计了三种对比方法,分别是:
对比方法一:计算两篇文档词语的tf/idf值,然后按权重排序,取前10个词组成集合,计算两篇文档的集合的重合程度,设阈值5,超过5个为相关,少于5个为不相关。
对比方法二:在前述方法基础上计算两两词对的词向量余弦相似度,然后将所有相似度求和后取平均值,大于阈值为相关。
对比方法三:按原有的方法以事件为节点,选取PageRank值最高的5个事件节点,判断两篇文档相似度。
通过参数调节,在相同的召回率下(10%、20%、30%、40%),四种方案的准确率如下:
表2 四种方案准确率
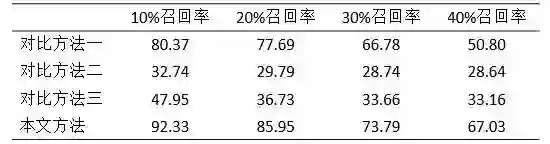
通过分析可以发现,通过调整参数,召回率相同的条件下,本文所提的方法均优于三种对比方法。其中,对比方法一通过tf/idf值发现了对文章贡献最大的若干词语,但是这种方式忽略了事件之间的关联性,提取出的词可能全部是事件元素或者全部是事件触发词,即使是相似的新闻,在用词上也会有差别,因此准确率较低。对比方法二在方法一的基础上引入了余弦相似度,因此能够在一定程度上发现由于相似用词而引起的事件相关性,但是该方法穷举了所有可能的词对,也引入了大量的噪声,因此准确率反而低于对比方法一。对比方法三找出权值最高的事件,但是这种表示事件的方式过于粗粒度,两篇同样围绕同一事件的文章,其中一篇提取出的权值最高的事件可能是“某某进球得分”,另一篇提取出的可能是“某某犯规”,这种方式最后还是通过句子级事件去衡量篇章级事件的相关性,其准确率远低于本文提出的方法,这也从侧面上说明,本文提出的篇章级事件挖掘方法是有效的。
本文提出的算法虽然构造了篇章连通图,但是连通图的作用也仅限于提取权重较高的节点,而图的结构信息并没有被充分利用到。下一步的工作目标即是将图的结构信息引入到篇章级事件的相关度计算中,提高计算的准确率。
同时,在发现相关篇章的基础上,对文章进行逻辑推理也是非常有意义的工作。下一步,我们期望能够完成篇章与篇章之间的逻辑关系发现任务。
7.参考文献
[1] Yubo Chen, Liheng Xu, Kang Liu, Daojian Zeng and Jun Zhao. 2015. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. In Proc. of ACL.
[2] Dian Yu, Heng Ji. Unsupervised Person Slot Filling based on Graph Mining.2016. In Proc. Of ACL.
[3] Quan Wang, Jing Liu, Yuanfei Luo, Bin Wang, Chin-Yew Lin. 2016. Knowledge Base Completion via Coupled Path Rank. In Proc. Of ACL.
[4] Kristina Toutanova, Xi Victoria Lin, Wen-tau Yih. 2016. Compositional Learning of Embeddings for Relation Paths in Knowledge Bases and Text. In Proc. of ACL.
[5] Shulin Liu, Yubo Chen, Shizhu He, Kang Liu, Jun Zhao. 2016. Leveraging FrameNet to Improve Automatic Event Detection. In Proc. Of ACL.
[6] Han Xiao, Minlie Huang, Xiaoyan Zhu. 2016. TransG: A Generative Model for Knowledge Graph Embedding. In Proc. of ACL.
[7] Yubo Chen, Shulin Liu, Xiang Zhang, Kang Liu, Jun Zhao. 2017. Automatically Labeled Data Generation for Large Scale Event Extraction. In Proc. of ACL.
[8] Wenyuan Zeng, Yankai Lin, Zhiyuan Liu, Maosong Sun. 2017. Incorporating Relation Paths in Neural Relation Extraction. In Proc. of EMNLP.
[9] Bingfeng Luo, Yansong Feng, Zheng Wang, Zhanxing Zhu, Songfang Huang, Rui Yan, Dongyan Zhao. 2017. Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix. In Proc. of ACL.
[10] Chen Chen, Vincent NG. 2012. Joint Modeling for Chinese Event Extraction with Rich Linguistic Features. In Proc. of COLING.
本期责任编辑: 刘一佳
本期编辑: 赵怀鹏
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。