赛尔原创 | ACL 2018使用知识蒸馏提高基于搜索的结构预测
论文作者:刘一佳,车万翔,赵怀鹏,秦兵,刘挺
1 基于搜索的结构预测
1.1 结构预测
自然语言结构预测是这样一类问题:问题的输出有多个变量,并且变量之间有相互依赖。图1给出了结构预测与分类的一个对比。可以看到,对于图1中的结构预测问题——机器翻译,算法要输出四个变量(对应四个翻译的词),而且翻译出的四个词是相互依赖的。

图1 分类(上)与结构预测(下)的对比
1.2 基于搜索的结构预测:搜索过程、打分函数与学习算法
一种求解这些多变量的方法是将求解过程建模为一个搜索过程。我们从起始状态出发,每次选择一个搜索动作(对于机器翻译来讲,可以认为从词表中选一个词作为翻译是一个搜索动作),进入新的状态。不断重复这一过程,就可以获得最终的结构(如图2所示)。
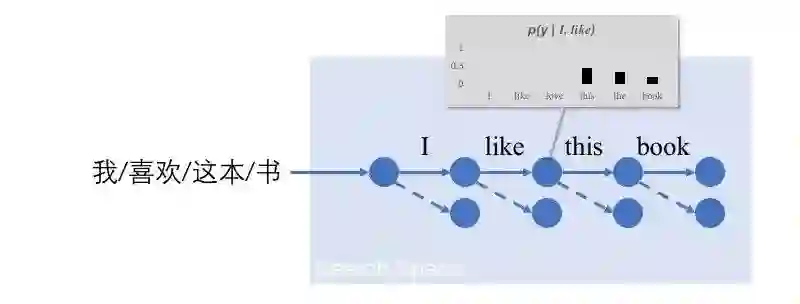
图2 基于搜索的结构预测与控制预测过程的打分函数
在这个搜索过程中,我们需要一个打分函数。这个打分函数告诉我们:在一个状态下,每个动作的可行性有多大。一种常见的方法是将这个打分函数建模为一个分类器(如图2中的p)。这个打分函数的一般学习过程可以归纳为:首先根据专家知识找到一个正确的搜索状态序列(图3中橙色的搜索序列)。然后,在这些正确的状态上,以正确的搜索动作为正例训练分类器。
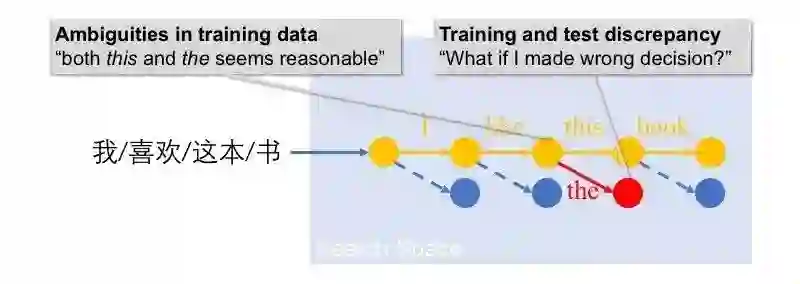
图3 基于搜索的结构预测的一般学习过程及其问题
1.3 问题
上述学习过程有两种常见的问题:
训练数据歧义性:在我们的翻译的例子里,”这“可以翻译this也可以翻译为the,但训练数据往往只有一种参考翻译。
训练测试不一致:在训练分类器时,我们是基于正确的搜索状态。但在实际测试阶段,算法会进入错误状态(如图3中的红色状态)。我们训练的分类器往往不具备在错误状态中做决策的能力。
在这项工作中,我们希望通过知识蒸馏(knowledge distillation)统一地解决这两种问题。
2 知识蒸馏
知识蒸馏[Hinton et al., 2015]是一种机器学习算法。不同于传统的从训练数据中有监督地学习,知识蒸馏从一个复杂模型(teacher model)的概率输出中学习参数。图4给出了知识蒸馏的学习目标,以及和对数似然学习目标的对比。当然,两种学习目标可以通过插值简单组合。
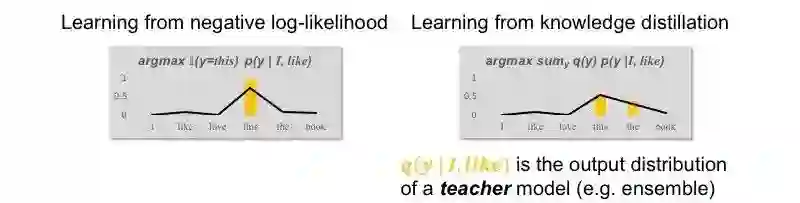
图4 知识蒸馏学习目标(右)与对数似然学习目标(左)的对比
在这项工作中,我们希望通过知识蒸馏统一地解决基于搜索的结构预测中的问题。对于训练数据歧义的问题,前人工作中常见的解决方法是使用模型集成[Dietterich, 2000]。在基于搜索的结构预测中,我们同样可以采用模型集成来提高模型应对有歧义训练数据的能力。然后通过知识蒸馏,将复杂模型(模型集成)的应对歧义的能力转移到简单模型中。具体来讲,我们可以直接在传统学习算法的基础上将对数似然替换为知识蒸馏的学习目标(如图5所示)。由于这种知识蒸馏方法在正确状态(reference state)上进行知识蒸馏,我们将其命名为distilling from reference。
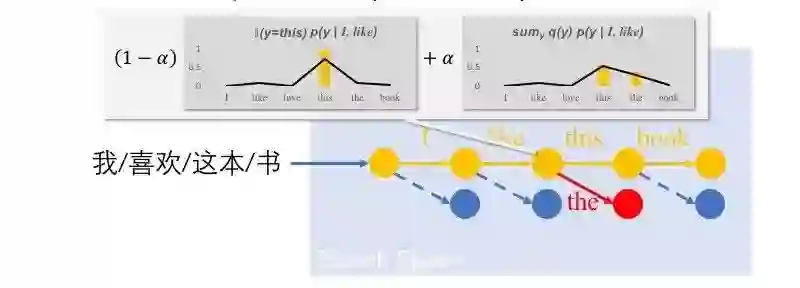
图5 Distilling from reference
对于训练测试不一致的问题,前人研究的主要解决思路是在训练过程中引入错误状态并在错误状态上进行模型学习。在这项工作中,我们也沿用了这一思路,用模型集成随机地探索状态空间,并在探索到的状态上使用知识蒸馏目标学习模型参数(如图6所示)。由于这种知识蒸馏方法在探索得到的状态(explored state)上进行知识蒸馏,我们将其命名为distilling from exploration。
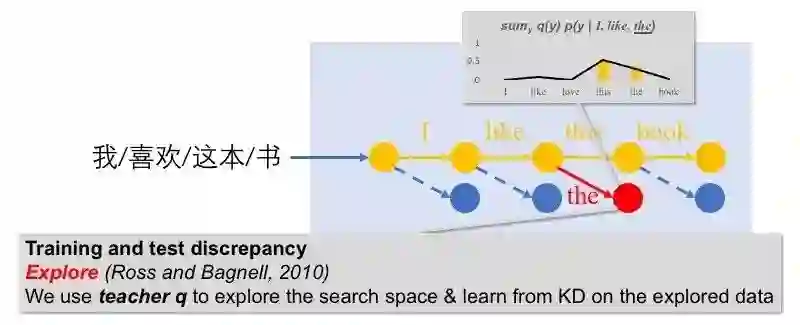
图6 Distilling from exploration
实践中,distilling from reference与distilling from exploration可以通过简单组合来进一步提到学习效果。我们在实验部分也验证了这点。
对于Distilling from exploration,我们完全放弃了传统对数似然的学习目标。后文的实验分析中,我们经验性地证明完全从探索中学习知识蒸馏模型也是可行的。
3 实验
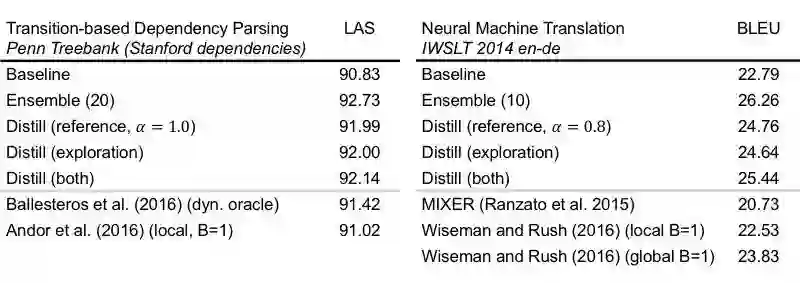
我们在基于转移的句法分析以及一个小规模机器翻译数据集上进行了实验。实验结果如表1所示。相较基线模型,我们的蒸馏模型在不改变模型结构的情况下将句法分析的准确率提高1.3,并将机器翻译准确率提高2.6。
表1 实验结果
3.1 模型集成是否具有克服歧义性的能力?
通过在依存句法分析中以dynamic oracle为工具(对于依存句法,d.o.可以在任意状态下给出最优的动作),我们发现,相较基线模型,模型集成选择的动作与dynamic oracle的选择来更接近。
3.2 完全从探索中学习知识蒸馏模型是否可行?
我们通过改变α调整从知识蒸馏学习的比例。我们发现,两个任务都呈现出越多地从知识蒸馏中学习,效果越好。这说明完全从探索中学习知识蒸馏模型是可行的。
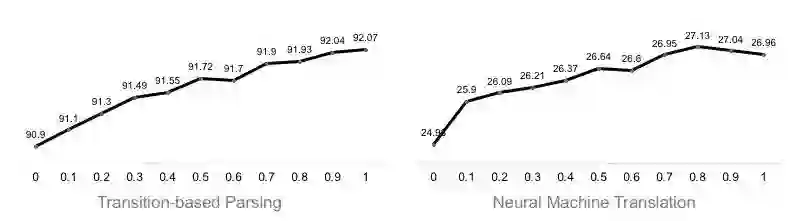
图7 α值与开发集性能的曲线
3.3 从知识蒸馏中学习是稳定的吗?
从violin-plot来看,从知识蒸馏中学习模型相较基线模型来讲对初始化更不敏感,有更好的模型稳定性。
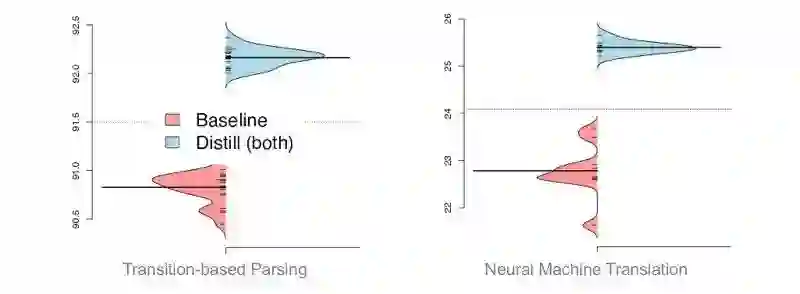
图8 模型稳定性
4 结论与补充资源
我们尝试用知识蒸馏解决基于搜索的结构预测的问题,并且取得了模型性能的显著提高。实验分析给出了知识蒸馏应用于基于搜索的结构预测的一些性质并经验性地解释了性能提高的原因。
论文:https://arxiv.org/abs/1805.11224
依存句法代码:https://github.com/Oneplus/twpipe
机器翻译代码:https://github.com/Oneplus/OpenNMT-py
AIS演讲视频(34分到43分):https://v.qq.com/x/page/m0686geizuw.html
5 引用文献
Thomas G. Dietterich. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Machine Learning, 40(2):139-157, 2000.
Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. CoRR, abs/1503.02531, 2015.
本期责任编辑: 丁 效
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



