
题目:
Mining Implicit Relevance Feedback from User Behavior for Web Question Answering
简介:
训练和刷新用于多语言商业搜索引擎的Web级问答系统通常需要大量的数据。一个想法是从搜索引擎日志中记录的用户行为从而挖掘隐式相关性。以前所有有关挖掘隐式相关性的著作都将反馈的目标指定为Web文档的相关性。由于QA任务中的几个独特特性,现有的Web文档用户行为模型无法应用于推断段落相关性。在本文中,我们进行了第一项研究,以探索用户行为与段落之间的相关性,并提出了一种挖掘Web QA训练数据的方法。我们对四个测试数据集进行了广泛的实验,结果表明,在没有人标记的数据中,我们的方法显着提高了段落排名的准确性。实际上,已证明这项工作有效地降低了全球商业搜索引擎中质量检查服务的人工标记成本,尤其是对于资源较少的语言。
成为VIP会员查看完整内容


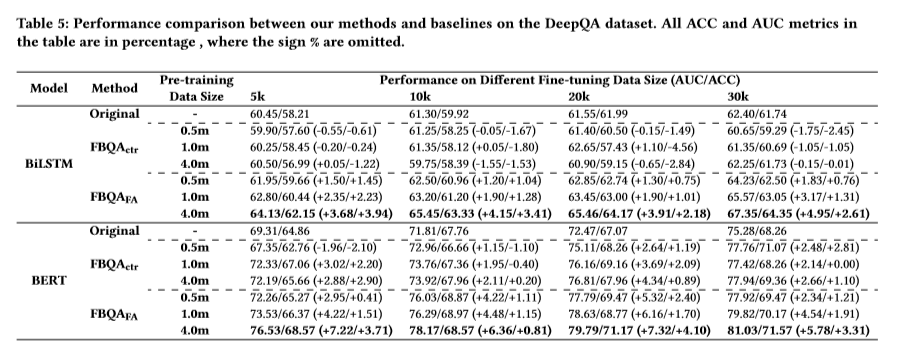
相关内容
Arxiv
3+阅读 · 2020年3月12日
Arxiv
4+阅读 · 2020年2月13日
Arxiv
4+阅读 · 2018年5月29日
Arxiv
5+阅读 · 2018年5月23日
Arxiv
5+阅读 · 2018年1月7日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2020年3月12日
Arxiv
4+阅读 · 2020年2月13日
Arxiv
4+阅读 · 2018年5月29日
Arxiv
5+阅读 · 2018年5月23日
Arxiv
5+阅读 · 2018年1月7日