NeurIPS 2021 | CyGen:基于概率论理论的生成式建模新模式




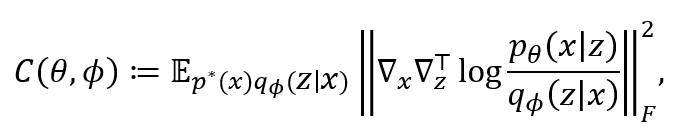
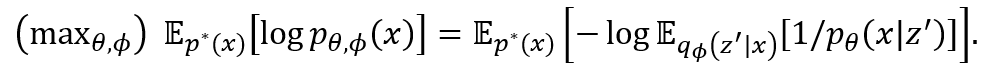

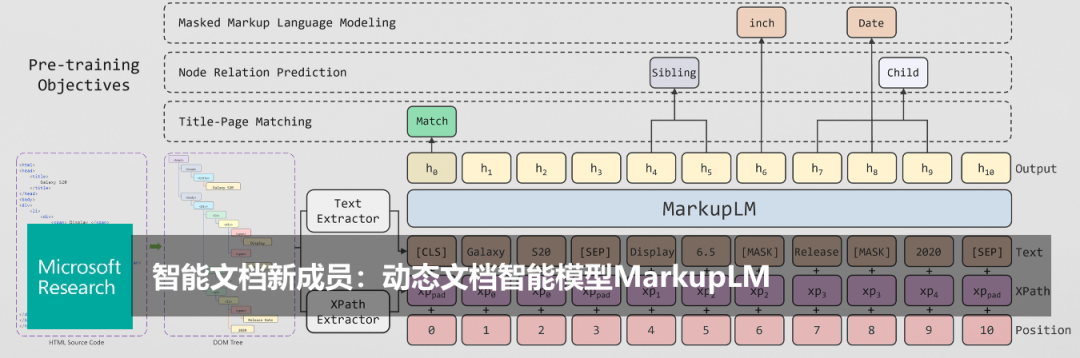
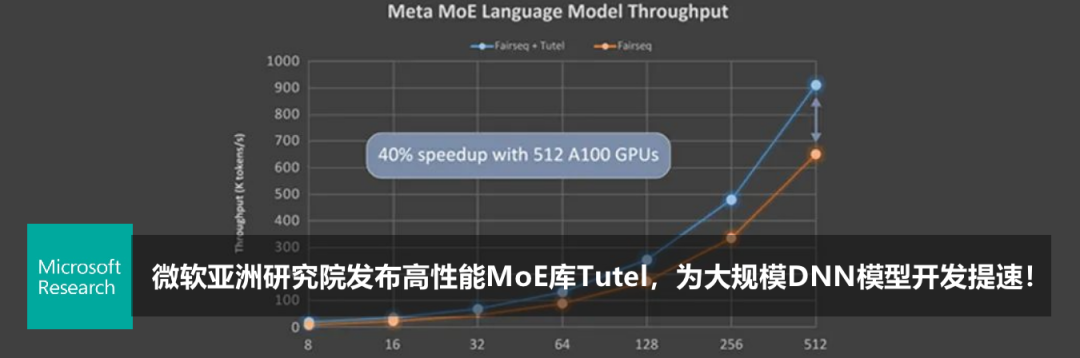



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文