GAN的原理和数学推导
点击上方【AI人工智能初学者】,选择【星标】公众号
期待您我的相遇与进步
1 简介
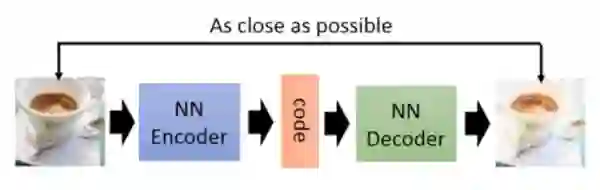
我们都知道可以通过最大似然估计的方式来获得一个模型 以用于生成图像,之所以它可以用来生成图像是因为最大似然估计可以获得一个 ,可以让 你和真实数据的分布情况。
上述的最大似然估计的方法虽然可行,但是有比较大的约束,即 模型不能够过于复杂;例如 服从正态分布,那么最大似然估计的方法就可以计算出 ,但如果 是一个非常复杂的分布,那么使用这种方式难以获得一个比较理想的模型。这种强制性的约束会带来各种限制,而我们则是希望 可以拟合任何分布,于是这里便引出了GAN了。
2 生成器拟合分布
在GAN中有2个主要的组成部分,分别是生成器和判别器,
2.1 生成器
因为通过最大似然估计的方式计算复杂的分布 ,所以GAN的方法就是使用一个神经网络来完成数据分布拟合的事情,而这个神经网络就是生成器,因为神经网络理论上可以拟合任意的分布,所以生成器可以代替最大似然估计来拟合数据的分布。
对于GAN中的生成器而言,它会接收一个随机噪声输入,这个噪声可能来自于正态分布、均匀分布或其他任意分布,经过生成器的转换,输出的数据可以组成一种复杂的分布,最小化这个分布于真实数据分布之间的差异。
对于输入给生成器的数据分布不用太在意,因为生成器是一个复杂的神经网络,它有能力将输入的数据“改造”成各种各样的数据分布。
那么对于生成器而言,它的目标函数为:
即最小化生成分布 与真实数据分布 之间的距离 。
因为我们无法准确的知道生成分布 与真实分布 的具体的分布情况,所以依旧使用采样的方式来解决这个问题,即从数据集中抽取一个样本,将抽出的样本的分布看成是 和 的分布。这种做法的思想其实是大数定律,知道2个分布后,就可以通过训练生成器来最小化两个分布之间的差异。
2.2 判别器
通过前面的描述我们可以知道生成器可以最小化生成分布 与真实分布 之间的距离,但是如何定义这个距离呢?即生成器目标函数中的 如何定义呢?
GAN可以通过判别器来定义这两个分布的距离,如下图所示:
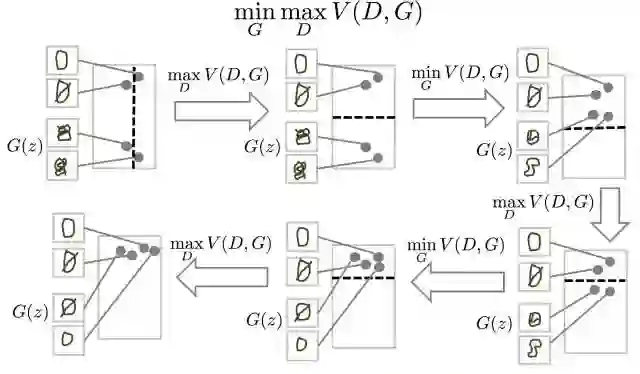
使用真实数据与生成数据来训练判别器,训练的目的是让判别器可以分别出哪些是真实数据哪些是生成的数据,即给真实数据打高分,给生成的数据打低分,其公式如下:
对于从真实分布 中抽样的样本 就打高分,即最大化 ;对于从生成分布 中抽样的样本 就打低分,即最大化 ,那么判别器D的目标函数是:
2.3 目标函数
回到一开始的话题,生成器在训练的时候需要先定义生成分布 与真实分布 之间的距离 ,而两个分布之间的距离可以由判别器来进行定义:
从而生成器可以获得新的目标函数公式:
3 GAN的数学推导
通过前面的讨论,我想大家应该已经明白生成器用来拟合真实数据分布,而判别器用来度量真实分布与生成分布之间的距离,接下来就来推导一下
因为在训练生成器之前,先要由两个分布之间距离的定义,所以这里就来推导 ,这里先将判别器的目标函数变换成积分的形式:
因为判别器希望 最大,其实就是要求上式的中间部分最大,即最大,为了简化计算,这里将 记为 ,将 记为 ,将 记为 ,则可以变换为如下的形式:
要找到一个 使得 函数最大,求其导数为0的值即可:
将上式进行简单的简化的变化可以求得:
这里将 和 替换为原来的值,获得如下的公式:
推导出 ,就可以得到将推导出来的结果代入生成器的目标函数中:
将其变换为积分的形式可以得到如下:
这里做一些简单的变换可以得到:
其实通过上面的推导可以看出来,上面的公式就是JS散度,这里再回忆一下JS散度公式:
通过上式可以看出 用于类似的样式,所以可以将 简化为下式:
推导到这里就可以看出,生成器最小化GAN的目标函数其实就是最小化真实分布与生成分布之间的JS散度,即最小化两个分布的相对熵。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“生成式对抗网络” 就可以获取《生成式对抗网络资料全局》专知下载链接







