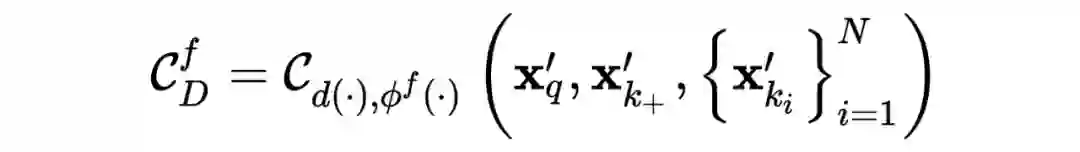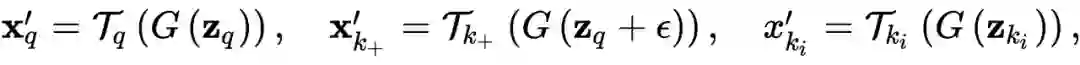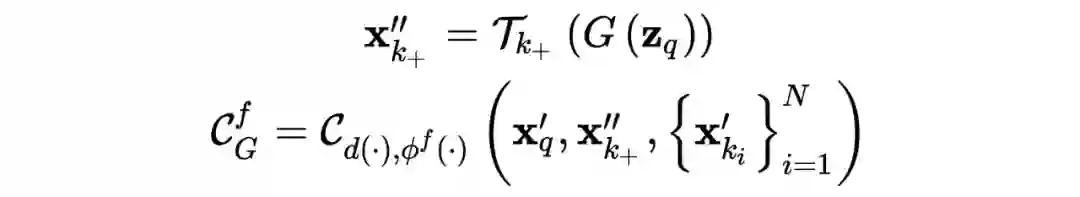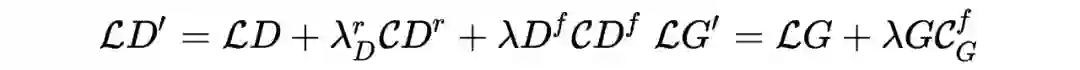![]()
©作者 | 杨孟平
学校 | 华东理工大学
研究方向 | 深度生成模型、小样本学习
本文介绍一篇利用实例判别实现数据高效(Data Efficienct)图像生成的论文,发表在 NeurIPS 2021,是香港中文大学周博磊老师课题组的一篇文章。
![]()
论文标题:
Data-Efficient Instance Generation from Instance Discrimination
https://arxiv.org/abs/2106.04566
https://github.com/genforce/insgen
![]()
Motivation & Observation
当数据量不够时,训练生成对抗网络通常会导致判别器过拟合,判别器容易简单的记住整个训练样本集。
从而使得判别器给生成器提供的反馈信号不足,降低生成器的生成质量。
近期很多研究采用各类数据增强的方式来减缓数据有限场景下的过拟合问题,但是有一点不会改变的是,判别器的学习目标还是区分给定图片是真实的还是生成的,而这一任务就必然会在有限数据下发生性能指数级(Substantial)的下降。
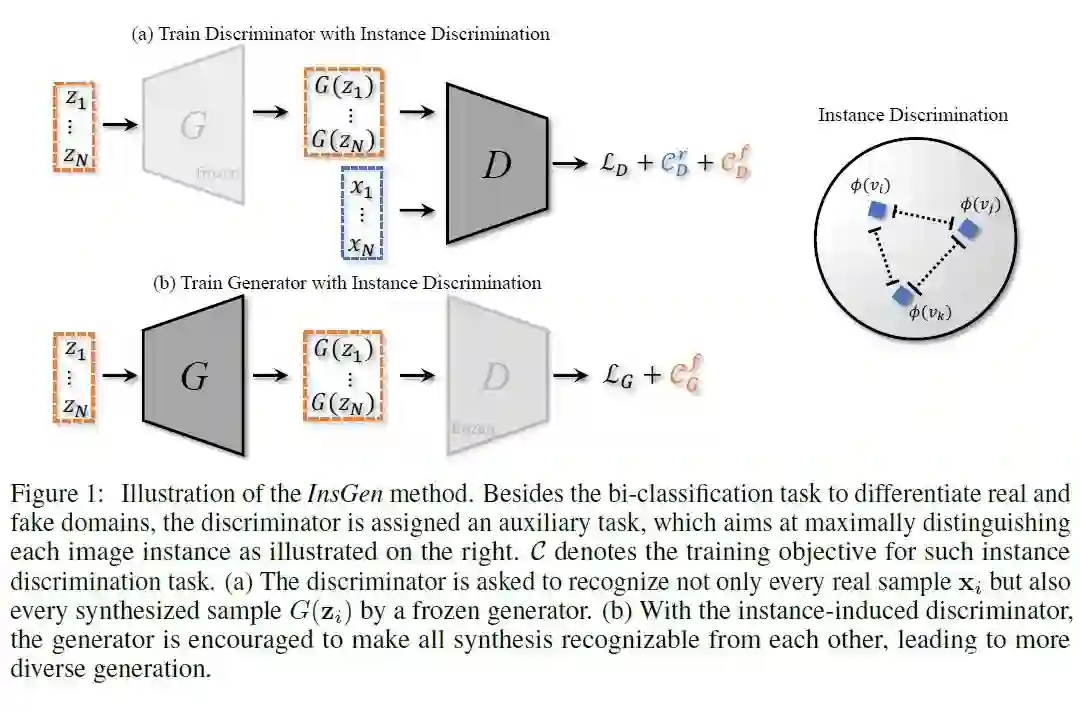
本文认为,仅仅让判别器学习如何区分真实图片和生成图片可能过于简单了,因此本文提出,判别器不仅需要区分 real/fake images,还需要将每一章图片归类至特定的类别。
这样的话,判别器就必须得提高提取判别特征的能力。
同时,不仅要为真实图片归类,也同样需要对生成数据进行归类。
这里对生成数据的分类很有意思,因为理论上生成数据的数量可以是无限的,那其实理论上可以利用无限的数据来训练判别器,让判别器有足够强的特征表示能力。这样相比于一般模型的判别器,这里的判别模型就需要同时对真实图片和生成图片进行实例判别,进一步提高判别模型提取 discriminative representation 的能力。
当时看到这里的时候,我其实很想不明白,实例判别,我们的数据都没有标签,怎样对其给定一个固定的类别呢?
Related Work
相关工作分为两部分介绍:1)介绍 GANs 中的数据增强,尤其是针对样本量有限场景下的一众方法,包括 ADA、DAG、DiffAug、CR、ICR 以及 ContraD;2)介绍 GANs 中的自监督学习,看到自监督可能就恍然大悟了,原来作者其实是利用了对比学习的方式来构建实例关系来完成实例判别的,此处介绍的方法也比较常见,Self-supervised 相关的 GAN 应用。
本文不同点:给判别器增加一个额外的任务,让判别器实现实力判别,希望对每一个图片实例,不管其是真实的还是生成的,都能够较好的完成识别。帮助提升判别器的鉴别能力,从而提升模型生成性能。
![]()
方法细节
![]()
1. Distinguishing Real Images
,即让判别器能够更好的提取图像特征,这样能够反过来(In turn)更好的指导生成器,这里也说到了选择判别器的原因在于判别器才能够又看到生成数据,又看到真实数据,而生成器是看不到真实数据的。那如何实现对真实数据进行鉴别呢,答案就是利用对比学习,对给定的一张图片
,通过不同的数据增广方式得到成对数据
,二者作为正类,其余所有不同于该图片的图片作为负类,最大化以下式子:
![]()
![]()
如此一来,就需要让判别器学习正样本对尽可能靠近,负样本对尽可能远离,以自监督的方式提升了判别器提取特征的表示能力,也就提升了 discriminative ability。
2. Distingguishing Fake Images
,即对生成图像也同样的进行实例级的判别,并且由于生成过程中理论上可以产生无数的生成数据,这样就实现了利用生成器生成很多的数据进行判别器判别能力(提取特征能力)的训练和提升。
3. Noise Perturbation
,为了进一步提升判别器的判别能力,文章还希望判别器对生成数据的轻微不同保持不变,下面公式中的
![]() 是从方差远小于隐向量 z 的先验分布中采样得到的,对隐向量加以这样轻微的干扰,理论上只会让生成图片发生轻微语义及的改变,加以下面表示的约束,让判别器对这样的干扰保持不变,其实就是进一步提高了实例判别的难度,让判别网络进一步提升判别能力。
是从方差远小于隐向量 z 的先验分布中采样得到的,对隐向量加以这样轻微的干扰,理论上只会让生成图片发生轻微语义及的改变,加以下面表示的约束,让判别器对这样的干扰保持不变,其实就是进一步提高了实例判别的难度,让判别网络进一步提升判别能力。
![]()
![]()
4. Toward Diverse Generation
,为了增加生成器的多样性,这里使用了类似于Mode Seeking的一个正则,但是是使用对比损失实现的,就是希望,生成的每一张图片,对于判别器来训练得到后的结果,都是不同的,从而提升的生成过程的多样性。
![]()
![]()
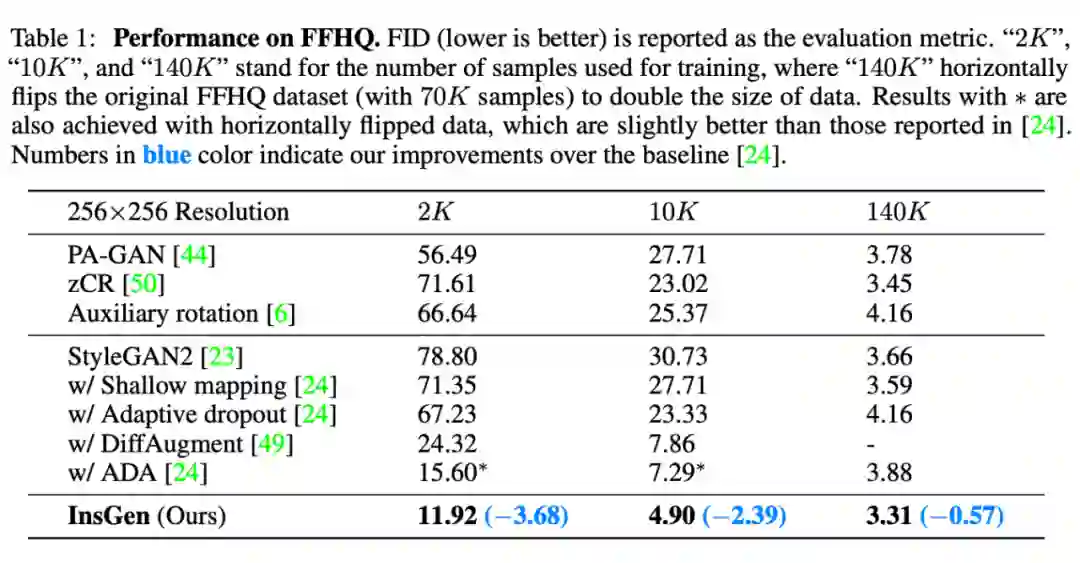
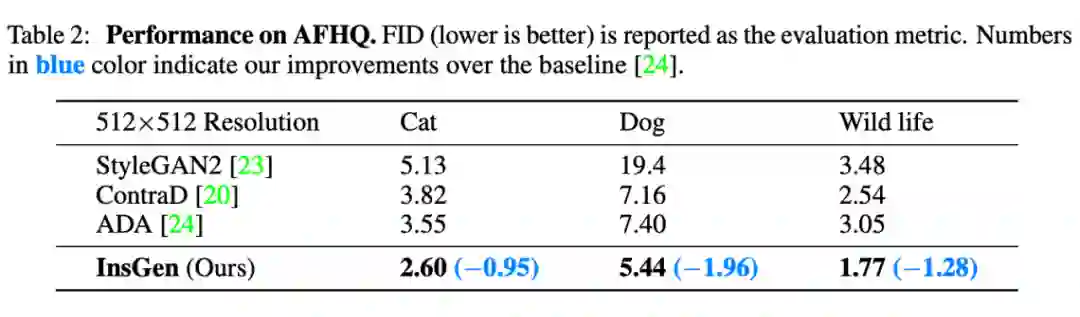
Experiment
![]()
![]()
3. 消融实验:
这里比较每部分模块的有效性,其实感觉可以像表 2 一样给出提升的数值,更有效的看出各模块对模型性能的贡献。
![]()
4. 尽可能多的利用无限多的生成数据:
这里的实验结果很有意思,就是说既然文章构造了正负样本对,并且给判别器添加了额外的实例判别任务,那么我们怎么确认需要判别的数量呢?
实验的做法是 follow 对比学习原论文中的 5% 设置。但是这里发现,其实越多的样本用作实例判别,就可以越多的提升模型性能,这也是我想了很久的点,就是既然给定的训练数据有限,那么我们应该如何利用无限多的生成数据提升模型性能?这里也给出了一种解法,其他的方法也值得探讨和思考。
![]()
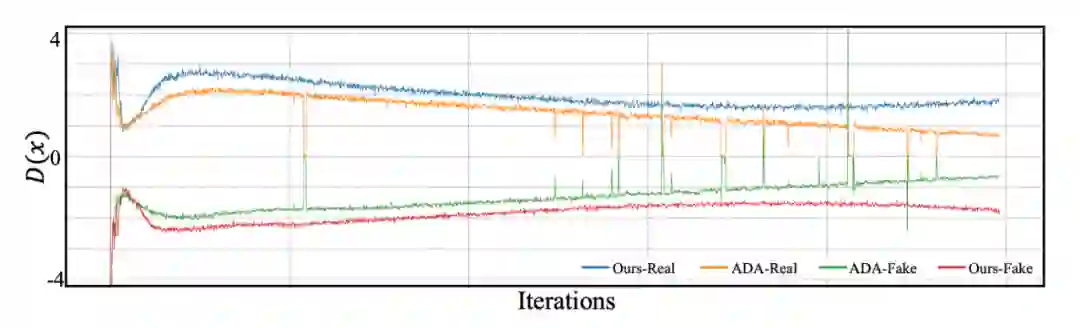
5. 判别器的鉴别能力提升了吗?
从 loss 曲线可以看出,在使用了实例判别后,D 给生成数据更低且真实数据更高的分数,相较于 ADA,的确在鉴别能力上做到了更自信,也展示了更好的判别能力。
![]()
总结
其实这篇文章的思路挺简单的,要引入额外的实例判别任务来增强判别器的鉴别能力,通过自监督的方式,一方面构造了正负样本对,另一方面通过构造的约束来提升 D 提取特征的表示能力,进一步的将实例判别拓展到生成数据,并讨论到生成数据是无限的,并在分析实验中给出如何利用无限生成数据的结论。
此外还添加了 Noise Perturbation 和 Diverse Generation,都通过对比学习的方式来实现。带来的启发一方面是判别器的表示能力通过自监督、无限的生成数据提升是可行的,另一方面是判别器的判别能力与生成性能存在着一定的正相关关系。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()





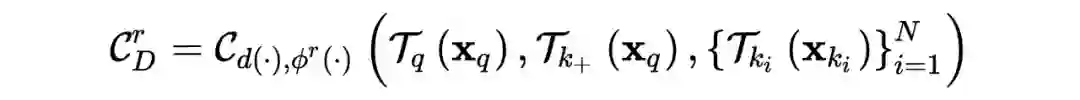
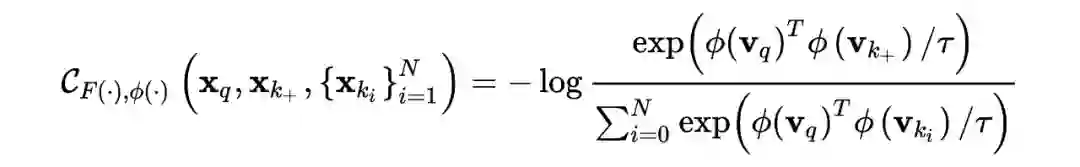
 是从方差远小于隐向量 z 的先验分布中采样得到的,对隐向量加以这样轻微的干扰,理论上只会让生成图片发生轻微语义及的改变,加以下面表示的约束,让判别器对这样的干扰保持不变,其实就是进一步提高了实例判别的难度,让判别网络进一步提升判别能力。
是从方差远小于隐向量 z 的先验分布中采样得到的,对隐向量加以这样轻微的干扰,理论上只会让生成图片发生轻微语义及的改变,加以下面表示的约束,让判别器对这样的干扰保持不变,其实就是进一步提高了实例判别的难度,让判别网络进一步提升判别能力。