【泡泡图灵智库】无监督方法的多姿态人物图像合成
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Unsupervised Person Image Synthesis in Arbitrary Poses
作者:Albert Pumarola,Antonio Agudo,Alberto Sanfeliu,Francesc Moreno-Noguer
来源:CVPR 2018
编译:张博
审核:彭锐
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——无监督方法的多姿态人物图像合成,该文章发表于CVPR 2018。
提出通过对抗学习合成任意姿态人像的一种新方法。给定一张单人图像和由平面骨架表示的期望姿态,模型呈现同一个人的新姿态图像。综合输入图像部分可见的新视图并推测未可见部分。已经由有监督学习解决了该问题,利用新姿态的标注图像对网络进行训练。本文提出的无监督策略超过了这些方法。将问题分成两个主要的子任务来解决具有挑战性的问题。首先,构思能够返回图像初始姿态的姿态双向生成器,之后不使用任何训练图像而直接与输入图像对比。第二,构建了一种包含内容和样式的新型损失函数,生成高感知质量的图像。基于DeepFashion大量实验对比表明模型产生的图像与全监督方法获取的图像非常接近。
主要贡献
1. 提出了一种在任意姿态下渲染出人像的方法。
2.采用GAN模型并通过无监督方式训练。
算法流程
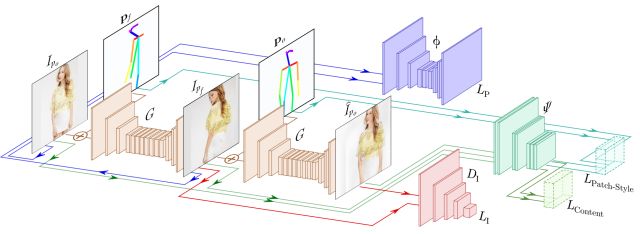
图1 通过无监督方法产生人的多视图图像概述
包含4个主要部分:生成器G,鉴别器D,二维姿态回归器Φ和预训练特征提取器Ψ 。
第一步:生成器G(I|p)作为一个可分辨的渲染,将给定的人在特定姿势下的一个输入图像映射到同一个人在不同姿势下的输出图像。网络中G使用了两次,首先映射输入图像之后返回原来姿态。
第二步: 回归器Φ估计平面图像中人的关节位置
第三步:判别器对生成的样本和真实的样本进行区分。
第四步:不通过标注计算的保持人物同一性的损失函数,提出的新的损失函数可以增强语义内容相似性。
主要结果
文章主要结果:
1. 定性对比结果。
1.1 所生成的图像保持身体形状,并且新纹理与原始图像一致,即使输入和所需姿态是不同的。
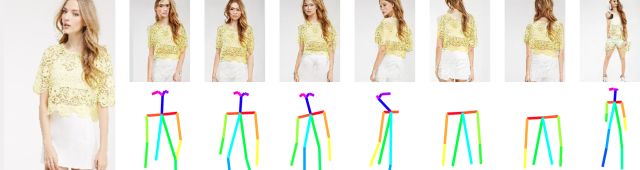
图2 提供一个原始图(左)和期望的平面姿态图(下行),模型生成该姿态下的真实感图像(顶行)。主要贡献是用无标记数据来训练生成模型。
1.2 图3呈现模型产生的另一组结果。成功解决了一定数量的复杂情况。一些案例展示了渲染姿态由前向到背向。例子中当原始图像在一个侧面,只有一个手臂能被观察到时,期望姿态是面朝前,需要同时渲染出双臂。且T恤的纹理丰富,在新的姿态下也很好的呈现了出来。

图3 DeepFashion数据集实验结果
每个测试样本有4张图像表示:输入图像,平面期望姿态,合成图像与正确标注数据。
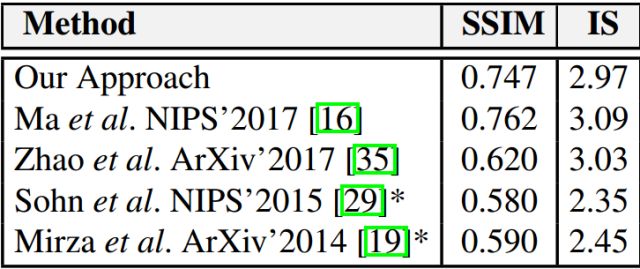
图4 基于DeepFashion数据集的定量分析。SSIM和IS是无监督的方法和另外四个最优良的监督方法的指标,测值越高越好,结果仅是指示性的,由于以前的方法中的测试分割是不能获取的,并且表中不同方法之间可能有所不同。定量分析结果表明无监督方法可与其它有监督方法相媲美。
1.3 图5展示了四个典型的失败案列,左上角例子中,原始图像纹理没有正确的映射到生成图像中。右上角例子中,原始图像面部没有在生成图像中完全去除。左下角例子中,原始图像姿态没有被恰当的转换成目标图像。右下角例子中,原始图像中身体一部分映射到生成图像中。

图5 基于DeepFashion数据集实验失败结果。失败案例(详见文中)中四种典型错误。
2. 替换为L1损失函数的结果。
文中每个组成成分生成、回归、分辨等都至关重要,去除任何部分都会损害图像效果。结果如图6所示。

图6 L1与同一性损失对比,通过L1损失训练并用与图2相同的输入条件处理时,模型得到的合成样本将结果与图2的结果进行比较,可得出,L1损失不能获取人物同一性。
3. 测试模型极限
图7给出了当输入图像包含背景时模型性能的评价。令人惊讶的是,尽管模型没有背景一致性的损失,也没有受过背景图像的训练,但结果仍然非常一致。此人被正确地渲染,而背景被过度平滑。要对背景变得鲁棒,需要更复杂的数据集和专门的损失函数。

图7 有背景的实验结果。左边提供了有背景的原始人物图象在第二行给出了平面期望骨架姿态图,生成的人物图象在首行,尽管通过无背景图像训练,但在该情况下效果良好(与图2相比)。

Abstract
We present a novel approach for synthesizing photorealistic images of people in arbitrary poses using generative adversarial learning. Given an input image of a person and a desired pose represented by a 2D skeleton, our model renders the image of the same person under the new pose, synthesizing novel views of the parts visible in the input image and hallucinating those that are not seen. This problem has recently been addressed in a supervised manner [16, 35], i.e., during training the ground truth images under the new poses are given to the network. We go beyond these approaches by proposing a fully unsupervised strategy. We tackle this challenging scenario by splitting the problem into two principal subtasks. First, we consider a pose conditioned bidirectional generator that maps back the initially rendered image to the original pose, hence being directly comparable to the input image without the need to resort to any training image. Second, we devise a novel loss function that incorporates content and style terms, and aims at producing images of high perceptual quality. Extensive experiments conducted on the DeepFashion dataset demonstrate that the images rendered by our model are very close in appearance to those obtained by fully supervised approaches.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com

