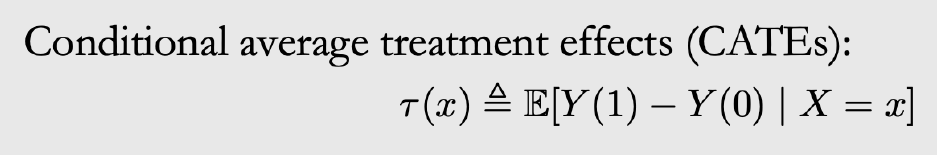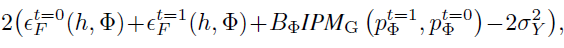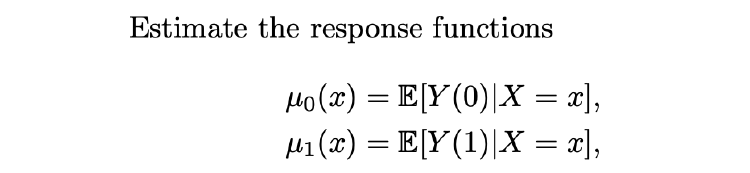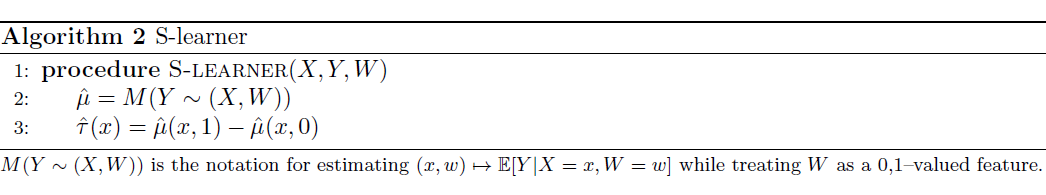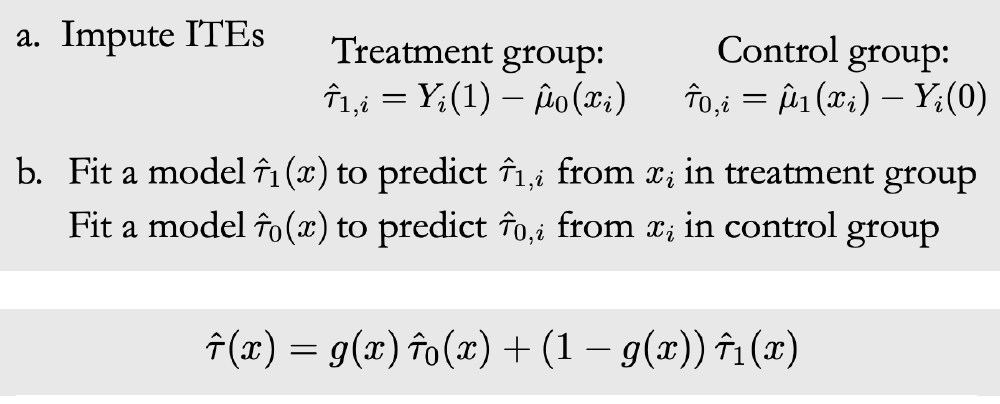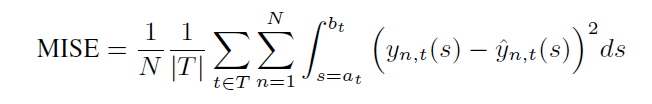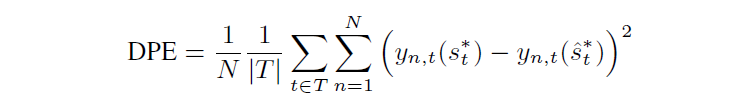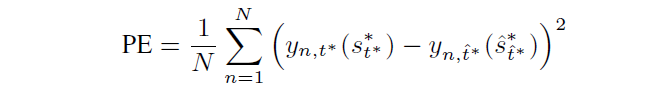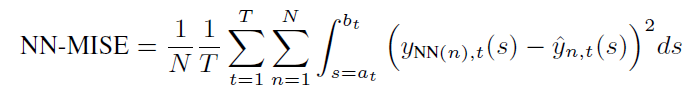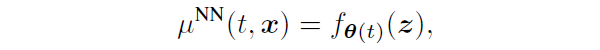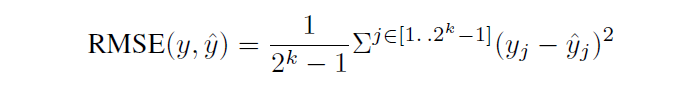![]()
©PaperWeekly 原创 · 作者 | 张一帆
学校 | 中科院自动化所博士生
研究方向 | 计算机视觉
![]()
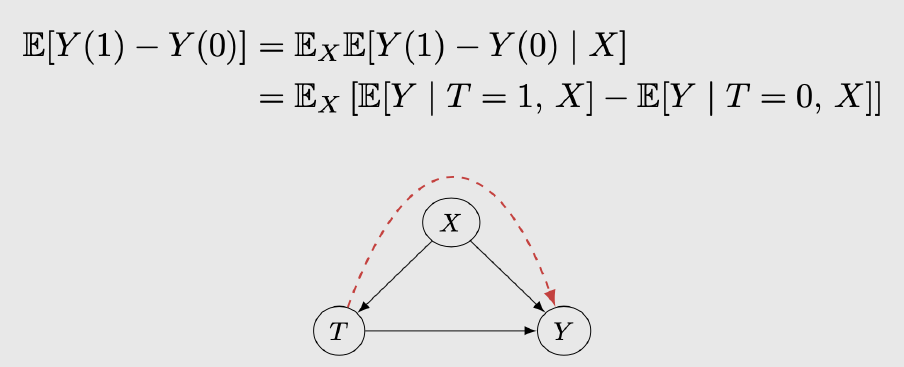
预测行动间的因果关系是一个非常重要的研究课题。例如,医生判断哪种药物会对病人产生更好的效果。在这种任务中,我们的可观测数据有过去采取的行动(吃了哪些药),它们的结果(病情),可能还有更多的协变量 covariate information(病人信息),但我们不知道行为与结果之间的因果关系。一种简单的估计方法是基于干预,即保证两次实验环境完全一致,只改变
(是否用药),然后将得到的结果求差即用药的收益。
但是,
不是那么容易的,根据观测数据我们只能得到条件分布
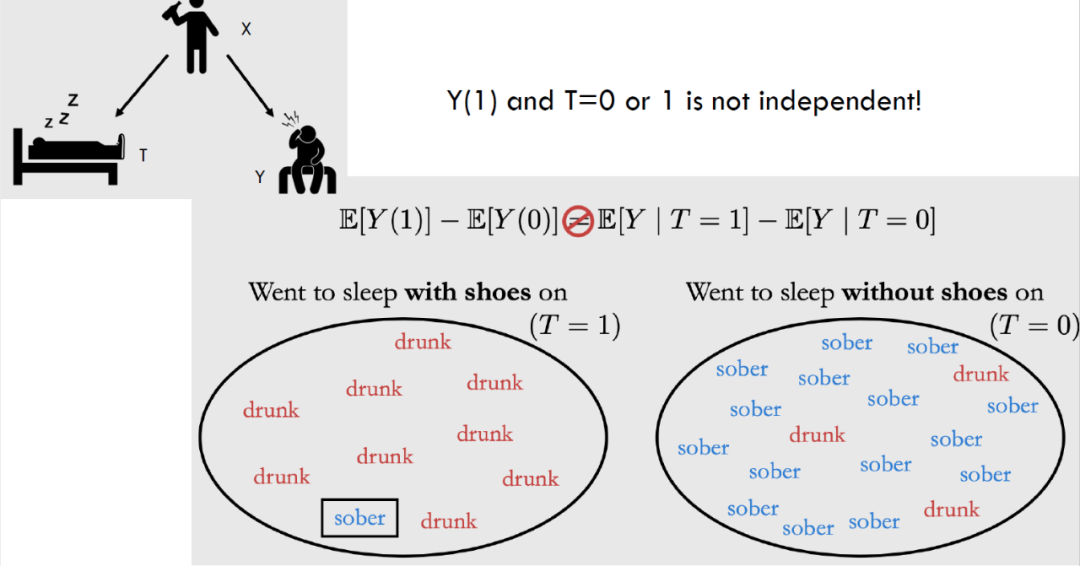
。考虑下面得例子。设
为睡觉时是否穿袜子,
为是否喝醉。
![]()
显然
有很强得相关性,但是我们知道二者并不具有因果关系,
之间还存在一些混杂因子(confounder)
(sober or drunk)影响了我们对因果关系的判断。要正确的估计
之间的因果关系,我们必须得到将
带来的影响使用 ATE 公式消除。
![]()
![]()
如果协变量包含所有混杂变量(即 treatment 和 outcome 的共因),那么因果效应称为可确定的(identified)。因此大多数 paper 都会假设没有不可观测的混杂因子。
在日常生活中,对于每个个体,我们大概率只能看到他们对其中一个可能的行动的反应,即
或者
只有一个可以观测,我们将
称为 control,将
称为 treatment。这种情况下我们如何来估计特定行为对个体在因果上的影响?这就是所谓的 individual treatment effect(ITE),公式化的描述有助于我们更好的理解这个问题。
给定数据空间
上的分布
,我们有一系列样本
,其中
。如果
,
如果
。我们的目标是学习一个 representation
和一个分类器
,这两组组件组成了一个因果估计器
,我们希望这个估计器得到的结果和真实的因果效应尽可能相似,即
。
ITE 问题可以看作是域迁移和数据集极度不均衡的结合体。首先,如上所示每个个体只能得到其中一个
的效果,而我们要预测其在另一种 treatment 下的结果。其次,相关的数据集往往分布很不均衡,比如大多数人遇到炎症会选择吃药
,因此
数据很少,这也是接下来的文章逐步解决的问题。
本文从第一篇以深度学习的工具研究 individual treatment effect 的文章开始,挑选了 6 篇顶会文章对该领域的发展做一介绍。这些文章主要集中在以下几个要点。
![]()
![]()
论文标题:
Estimating individual treatment effect: generalization bounds and algorithms
收录会议:
ICML 2017
https://arxiv.org/abs/1606.03976
https://github.com/clinicalml/cfrnet
本文第一次提出了 ITE 的概念,并使用 DA 的一套理论对其进行 bound,依次设计了一套行而有效的算法。
在背景部分我们提到了,ITE 与域自适应有着紧密的联系,本文的 bound 也是基于传统 DA 的那一套 VC dim 的理论,这里直接给出结果。
![]()
可以理解为 ITE 的整体性能被两项所 bound,第一项是在训练数据上的 empirical loss,第二项可以理解为 source 和 target 训练得到表示的差异,该差异越小,说明模型对 treatment 不敏感,更有可能抓住
之间的因果关系。
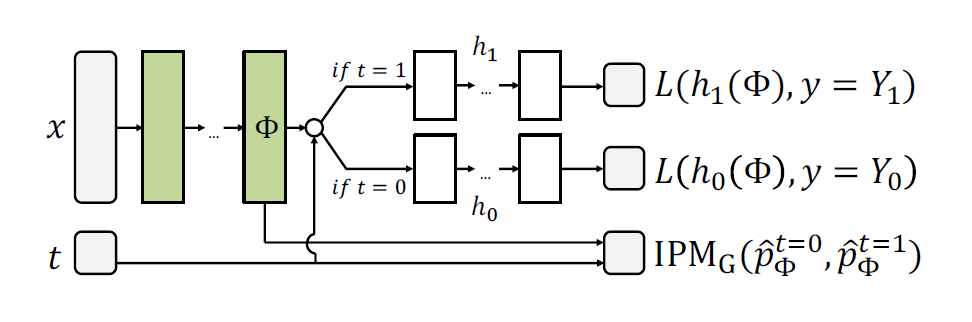
在这个理论基础上,作者设计了如下的框架,输入
,我们先抽取的特征,然后根据
的不同训练不同的分类器,最小化两个分类器 empirical loss 的同时,减少 representation 分布之间的差异。
![]()
本文解决数据集不平衡的方法很简单,即给 empirical loss 前根据样本数目加上一项权重。
![]()
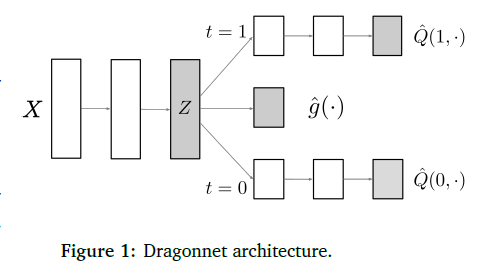
Dragonnet
![]()
Adapting Neural Networks for the Estimation of Treatment Effects
收录会议:
论文链接:
https://arxiv.org/abs/1906.02120
代码链接:
https://github.com/claudiashi57/dragonnet
这篇文章的核心思想是这样的:我们没必要使用所有的协方差变量
进行 adjustment。
![]()
中有一部分变量只与 outcome 相关,和 treatment 无关,这些部分与因果关系的估计无关,是进行 adjustment 的噪声,因此我们应该抛弃这部分变量。就像 DA 或者 DG 一样,我们需要找到域不变的特征这样才能有好的泛化性能。但是背景之类的特征往往有助于模型在当前分布下提升辨别能力。同样的,这里丢弃一部分协方差变量也会带来预测精度和鲁棒性的 tradeoff。
![]()
1. 首先,一个三头的网络,和上一篇文章一样,一个 encoder 提取特征,然后给两个 branch 基于 treatment 和协变量预测 outcome。
2. 不同的是,这里训练一个分类器
,这样做的目的是。利用神经网络的特点,被分类器利用。即
激活的特征更有可能是与
相关的协变量。
3. 为了更好的鲁棒性,在下游任务中估计因果关系时只使用
挑选出来的协变量。
所以总的 loss 也不难理解了,一个回归损失加上一个分类损失。
![]()
CATE
Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning
收录会议:
论文链接:
https://arxiv.org/abs/1706.03461
本文提出了一种新的框架 X-learner,当各个 treatment 组的数据非常不均衡的时候,这种框架非常有效。
![]()
已有的算法主要分为两类:
T-learner:即上述文章使用的模式,使用两个不同的 branch 估计两种后验概率。
![]()
S-Learner:将
或者说
作为特征输入,使用同一个 branch 对二者进行估计。但是这种方法往往需要对
进行一定的变化,因为
只是一个标量,我们将他放入高维的特征中,影响微乎其微。
![]()
1. 本文使用两个 branch 对两个 group 的后验概率分别进行估计,值得注意的是
的时候,
都可以作为真实的因果估计值。
2. 最后两个估计值根据一个权重
联合成为一个估计,
通常选择使得
的方差最小。最优的情况是,如果我们可以计算
那最小化它就能得到最优的
。
![]()
DRNets
![]()
Learning Counterfactual Representations for Estimating Individual Dose-Response Curves
收录会议:
论文链接:
https://arxiv.org/abs/1902.00981
代码链接:
https://github.com/d909b/drnet
本文提出了新的 metric,新的数据集,和训练策略,允许对任意数量的 treatment 的 outcome 进行估计。
Setting:本文考虑 treatment 有多个的场景,即
,如果是医生-病人的场景,每个 treatment 可能对应一个用药的剂量 。训练目标是对每个 treatment 范围内的任意一个
都可以给出一个估计值,因此此时对于一个个体
,因果效应显示为一个曲线,
为 treatment
的函数。
Metric:本文给出了衡量该场景模型效果的 metric,给定 treatment 和相应的剂量
,模型给出一个估计值
,那么总共的评估指标如下所示,对所有样本,所有 treatment,在其剂量范围内均方误差的积分。
除了对均值进行评估,本文还提出了对最优剂量进行评估,对每个个体每个 treatment 的每个剂量我们找效果最好的那个,和预测的最好的那个进行比较,即给每个 treatment 评估其最优剂量是否正确。
更进一步,我们在所有 treatment 中取最优,即个体层面看预测的最优 treatment 是否正确。这种做法往往是有意义的,因为在药物方面,医生也总是想选最优的 treatment,而不关注其他次优的 treatment 的预测精度。
![]()
通过考虑多个指标,我们可以确保预测模型既能恢复整个剂量反应,又能选择最佳治疗和剂量选择。
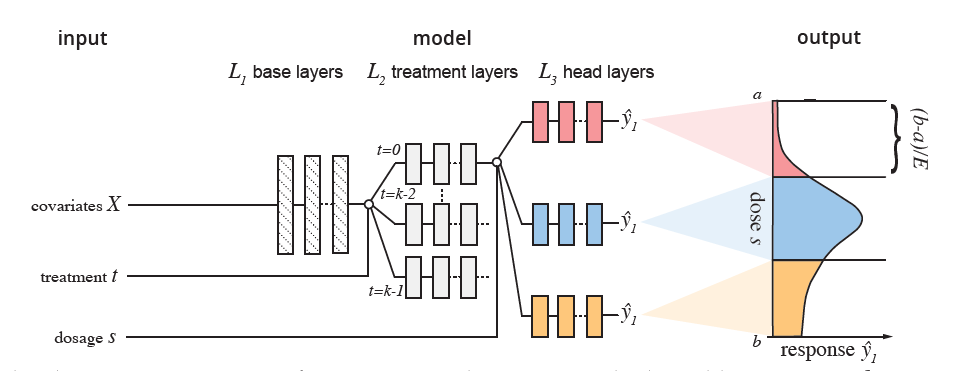
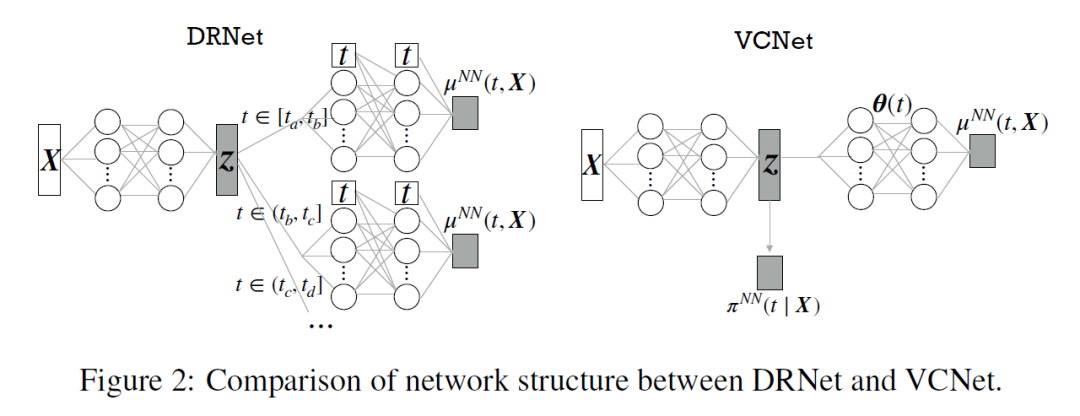
Model Architecture 从问题中我们可以看出现在有三层关系,一个个体,对应多个 treatment,每个 treatment 有很多的剂量。因此本文将以往的工作进行扩展,提出了分层的结构。
一个特征层提取协变量的特征,每个 treatment 对应一个 branch 将特征进一步处理,最后对于连续变量的问题,我们将区间分成
份,每个 branch 对应
,所以
越大,branch 越密集,我们对连续变量的近似就越好,但是参数量也越大,二者是一个 tradeoff。为了进一步提升
对网络参数的影响,作者在 head 层每一层都会将
concatenate 进去。
![]()
Model Selection 因为在训练过程中,我们只能得到模型在一个 treatment 上的 outcome,因此不能计算上述指标来进行模型选择,作者转而求其次,选择最近邻样本。如下所示,虽然样本
没有在每个 treatment 上的结果,但是我们选其拥有该结果的最近邻作为替代近似的选择模型。
![]()
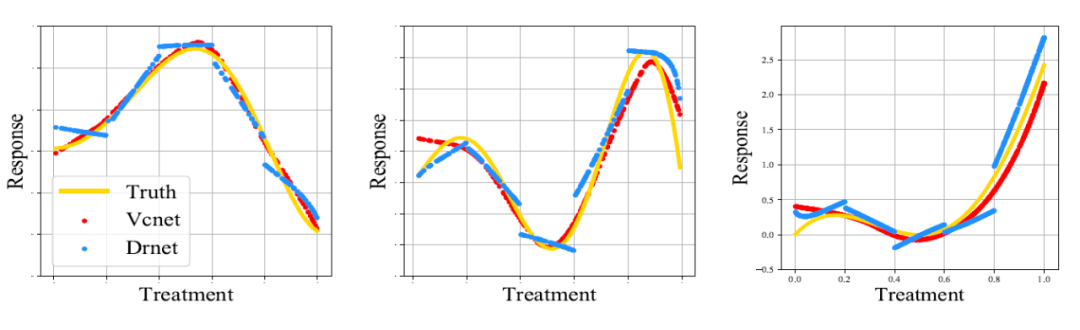
可以看到这篇文章实现的连续并不是真正的连续,而是一种近似。在下图中本文提出的模型 Drnet 的弊端可以得知,其与 GT 之间的差距还是有很大的,连续性并没有那么好。
![]()
VCNet
![]()
VCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments
收录会议:
论文链接:
https://arxiv.org/abs/2103.07861
代码链接:
https://github.com/lushleaf/varying-coefficient-net-with-functional-tr
本文基于 varying coefficient model,让每个 treatment 对应的 branch 成为 treatment 的函数,而不需要单独设计 branch,依次达到真正的连续性。除此之外,本文也沿用了 Adapting Neural Networks for the Estimation of Treatment Effects 一文中的思路,训练一个分类器来抽取协变量中与
最相关的那些。
所谓的 varying coefficient model 其实就是说后面的分支:
![]()
他的参数不再是固定的,而是 t 的函数,这意味着神经网络定义的非线性函数依赖于变化的 treatment
。
![]()
![]()
NCoRE: Neural Counterfactual Representation Learning for Combinations of Treatments
收录会议:
论文链接:
https://arxiv.org/abs/2103.11175
本文考虑更复杂的情况:多种 treatment 共同作用。作为一个具体的例子,考虑治疗 HIV 患者,医生会同时开出抗逆转录病毒药物的组合,而不是只给一种药,以防止病毒逃逸。这种场景非常具有挑战性,考虑 15 种可能的 treatment,就有
种可能的组合,而大多数组合很少甚至不会出现在真实数据中。这时候如果我们沿用上述的做法,每种组合搞一个 branch,参数量太大,而且每个 branch 相应的数据可能很少,很难训练。
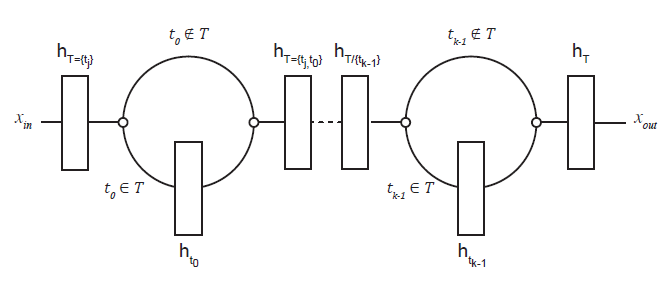
本文提出了一种新的网络架构,如下所示,依然维护
个 branch,如果协变量
对应的多个 treatment 分别为
,那么这三个 branch 都会进行训练。
![]()
那么如何建模多个 treatment 之间的相互影响呢?答案就在于上图中的蓝色部分,他们纵向是有相互连接的,显然此时x会经过
三个 branch。最终所有 treatment 得到的 embedding 做均值得到最终的表达。
文章的 metric 是直观的,在所有可能组合的 treatment 上评估 outcome 的回归结果。
总结一下,现在 ITE 的发展主要集中在,主要集中在(i)放松假设,treatment 从二值变得更多,甚至连续,最后考虑 treatment 之间的相互作用。(ii)设计更简单,效果更好的网络结构,多头网络每个头只能单独训练,如何减少 branch 同时保证不同 treatment 对 branch 的影响仍然是核心问题。(iii)设计更好的正则化策略,treatment group 之间的样本数目差距很大,如何从算法的角度减小这个差距也是一个研究重点。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()