腾讯郭棋林:实验数据难获取?挑战观测数据上的因果推断!

分享嘉宾:郭棋林 腾讯 高级数据研发工程师
编辑整理:甘雨鑫 上海财经大学
出品平台:DataFunTalk
导读:本文的分享主题为观测数据因果推断,希望通过本文可以让大家对观测数据因果推断有一个整体的了解,明晰当前观测数据因果推断的困境和主要处理方法,以及在特定问题中的一套通用解法。具体将围绕以下3部分展开:
观测数据因果推断基本知识
准实验方法在腾讯看点的应用案例
启动重置类问题通用分析方法
01
观测数据因果推断基本知识
1. 混淆结构和对撞结构
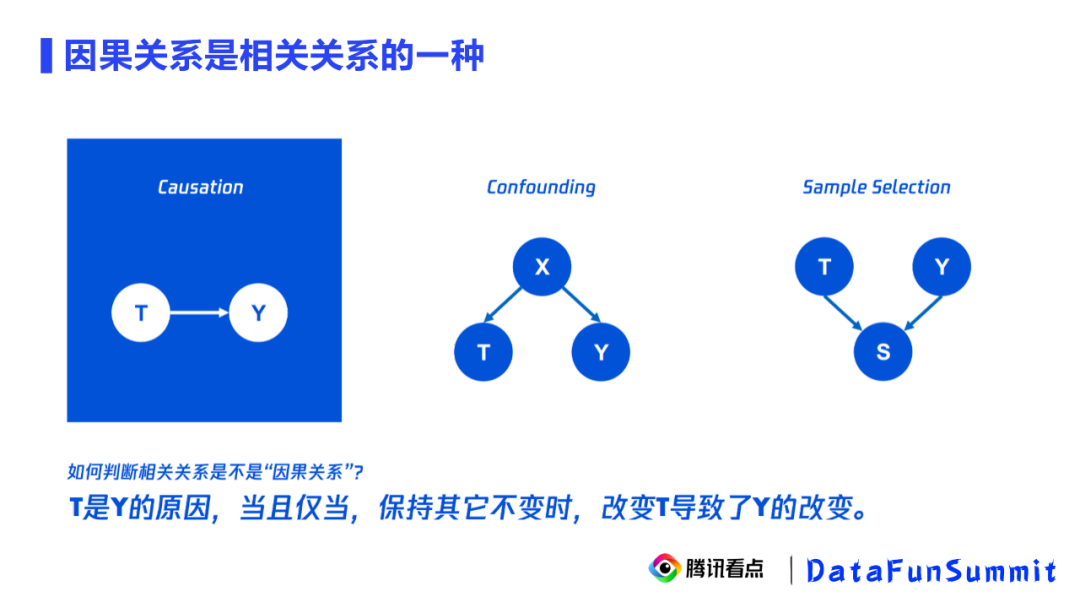
因果关系是相关关系的一种,因果推断用于学习因果关系。左图中T和Y之间的有向边代表因果关系,此因果关系会让它们在上层显示出一个相关性。我们能不能通过相关性去寻找因果性呢?答案是否定的。因为除了因果关系,还有两种结构也会让T和Y显示出因果性,比如右侧的混淆结构(confounding)和对撞结构(sample selection)。在这两种结构中,虽然T和Y之间不存在有向边的因果关系,但却会因为混淆因子和对撞因子的存在,导致它们显现出统计相关性,这样就会给我们的因果推断制造一些干扰,这也是因果推断方法存在的必要性。下面,我们依次举例说明混淆结构和对撞结构。
① 混淆结构
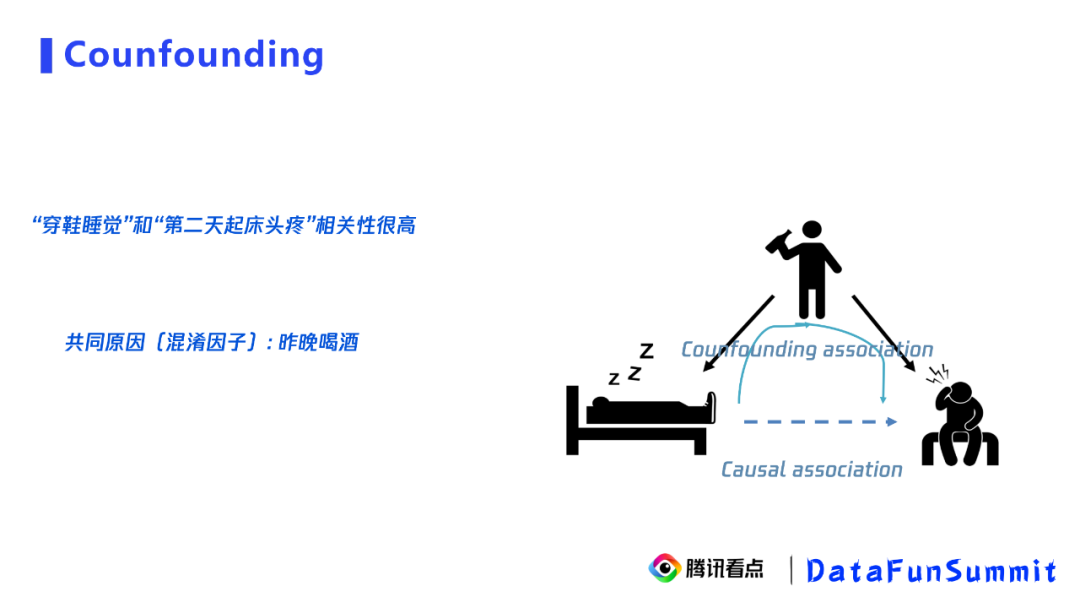
我们拿“穿鞋睡觉“和”第二天起床头疼“来说明由混淆因子带来的相关性。比如,在一个数据集中,我们发现”穿鞋睡觉“和”第二天起床头疼“的相关性很高,因此我们可能推断出”穿鞋睡觉“会导致”第二天起床头疼“。事实上,我们知道在医学中这条有向边是不存在的。那么,这样的相关性是谁带来的呢?我们又看了下数据,发现在数据集中有”昨晚喝酒“这个变量,并且”穿鞋睡觉“的人大部分是”昨晚喝酒“的人。事实上,”昨晚睡觉“会导致”第二天起床头疼“在医学中是具备因果性的,因此最终间接导致了我们看到的“穿鞋睡觉”的人“第二天起床头疼“的比例很高,这就是混淆结构。其中,同时影响”穿鞋睡觉“和”第二天起床头疼“的变量”昨晚喝酒“就是混淆因子。
② 对撞结构
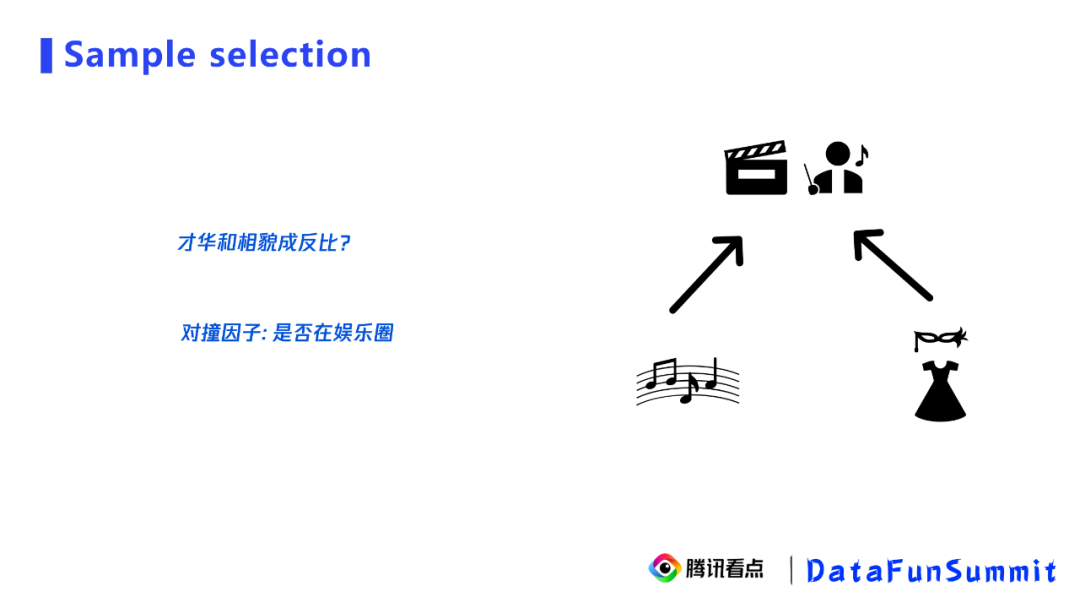
我们常常发现,在娱乐圈中,才华和美貌是成反比的,出现这种现象的原因就是对撞结构,也称之为选择偏差。我们可以看右边的图,其实只要具备才华和美貌中的一项就容易进入娱乐圈,但同时具备才华和美貌本身就是一个小概率事件,所以我们看到娱乐圈中大部分人只具备才华和美貌中的一项,给我们的感觉是他们的才华和美貌成反比。实际上,在全体人群中这两者是没有相关性的,这就是对撞结构。其中,对撞因子是“是否在娱乐圈“,我们只会在娱乐圈看到这种反比。
2. 解决方法
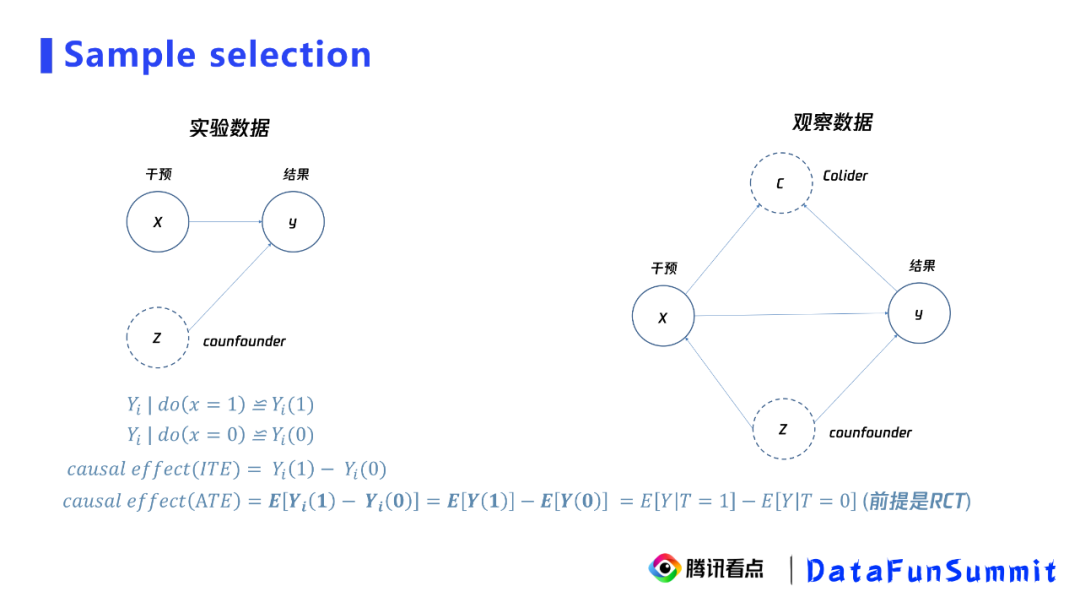
那么如何解决这两种结构带来的干扰,从而得到真正的关系呢?一般的方法是实验。
从左图中可以看到,实验相当于取消了干预在因果图上所依赖的父节点,让干预的分配只依赖于一个随机变量。这时可以证明,在整体人群中的因果效应,我们称之为ATE,等于相关性。这里的关键是用户是被随机分配的,当没有随机条件时,ATE公式(尤其是加粗的部分)将无法成立。比如,在右图观测的数据中,干预是受到混淆变量Z的影响。在这种情况下,加粗部分不成立,我们也就无法通过相关性直接得到因果性。
3. 观测数据和实验数据的区别
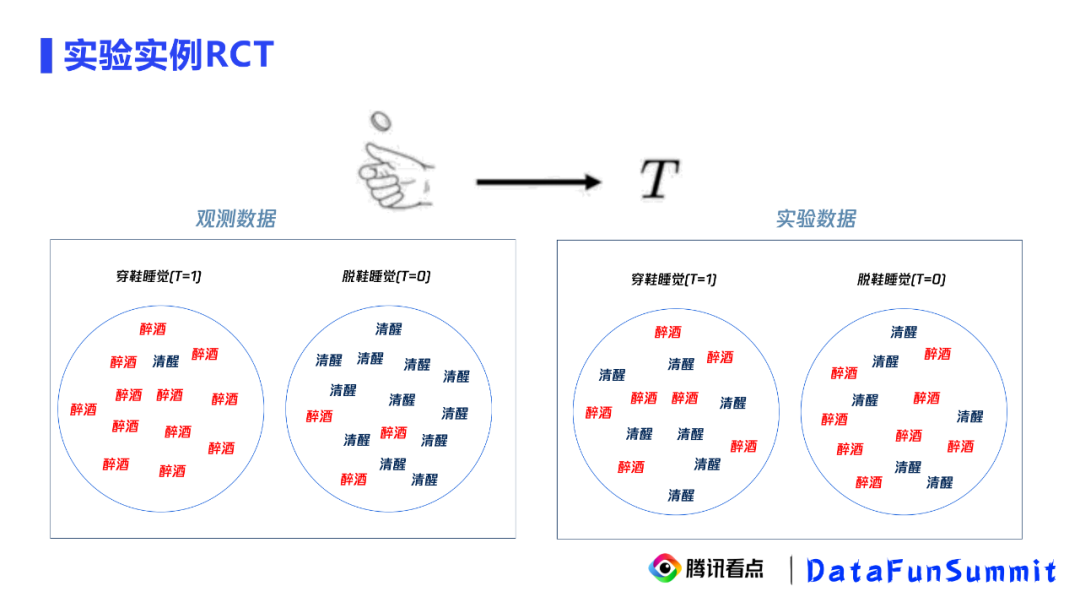
我们拿“穿鞋睡觉”和”第二天起床头疼“的数据来说明实验数据和观测数据的区别。
观测数据中,“穿鞋睡觉“作为实验组,但其中大部分人都是醉酒的,“脱鞋睡觉”作为对照组,但其中大部分人都是清醒的,因此我们看到“穿鞋睡觉”的实验组里中大部分人都醉酒,得出“穿鞋睡觉”导致醉酒(”第二天起床头疼“)的错误的因果关系。我们可以清楚地看到混淆对因果关系的影响,我们发现两个组醉酒的分布是非常不平衡的。
实验数据中,我们会进入每个睡觉的人的房间,通过抛硬币决定给他脱鞋还是穿鞋。最终实验组和对照组醉酒和清醒的状况如右图所示,各种混淆变量比较均衡,我们还发现两个组醉酒的比例都差不多,最终我们得到“穿鞋睡觉“不会导致醉酒(“第二天起床头疼”)的正确的因果关系。
这就是实验数据和观测数据上推断的区别。
4. 实验的局限性

既然如此,这类问题我们都用实验解决不就可以了吗?事实上,存在一些无法实验的原因,比如伦理限制、无法实现、历史遗留等。因此我们不得不借助观测数据上的因果推断来得到因果效应。
5. 挑战观测数据上的因果推断
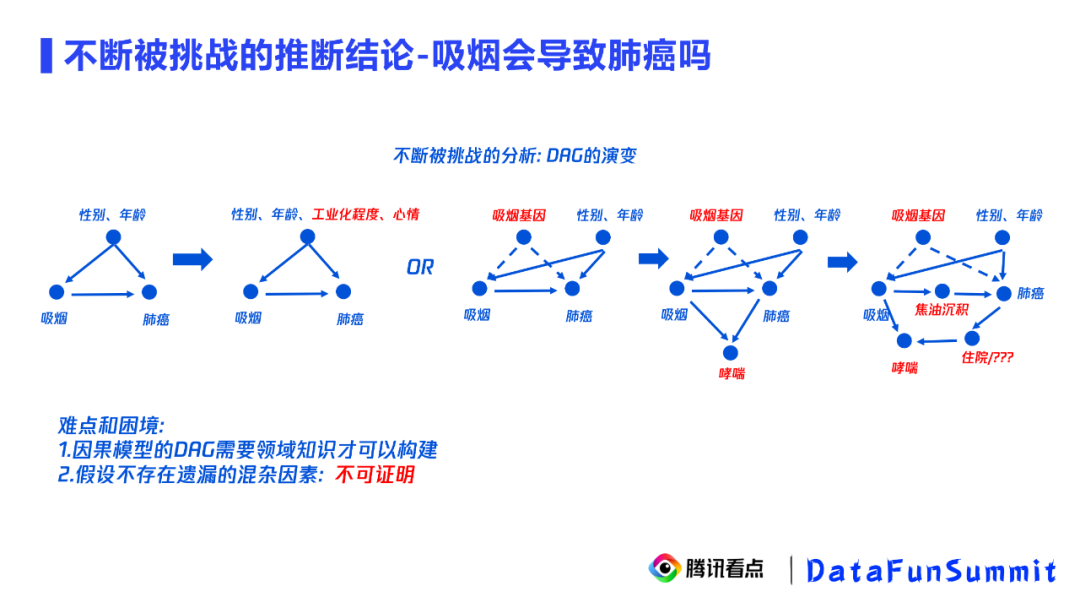
观测数据上的因果推断是需要一定的业务主观性的,因此它分析的结论很容易被挑战。我们拿吸烟会导致肺癌的案例来说明观测数据因果推断目前的主要问题。
刚开始去观测吸烟和肺癌的关系,我们会发现吸烟人群中肺癌的比例很高,因此可能得出结论吸烟会导致肺癌。
① 挑战1
吸烟的人大部分都是男性,而男性和女性肺癌的犯病概率是不一样的,所以如果不控制性别和年龄,可能会导致吸烟和肺癌的结论存在辛普森悖论。
小编补充:辛普森悖论是指当人们尝试探究两种变量是否具有相关性的时候,会分别对之进行分组研究。然而,在分组比较中都占优势的一方,在总评中有时反而是失势的一方,即简单的将分组资料相加汇总,不一定能反映真实情况。
② 挑战2
只固定性别和年龄远远不够,还有很多遗漏的混淆因子,如工业化程度、心情,这些变量也同时影响吸烟和肺癌。更有甚者提出,可能有一些根本无法衡量的因子同时影响吸烟和肺癌,如吸烟基因。在不考虑它的情况下得到的结论也是错误的。
③ 挑战3
即使做了很大努力,把工业化程度和心情全部固定住了,同时把吸烟基因通过敏感性分析的方法排除了。我们还是会被挑战——可能控制了一个对撞因子,比如哮喘。吸烟和肺癌都会导致哮喘,如果不小心在控制混淆因子的同时控制了对撞因子,那么最终得到的因果关系也是带了相关性的。当然,还有随着因果图的复杂,也会带来很多挑战,相应的因果推断也会发生改变。
可以看出,观测数据因果推断的过程比较曲折。
6. 因果推断整体分析框架
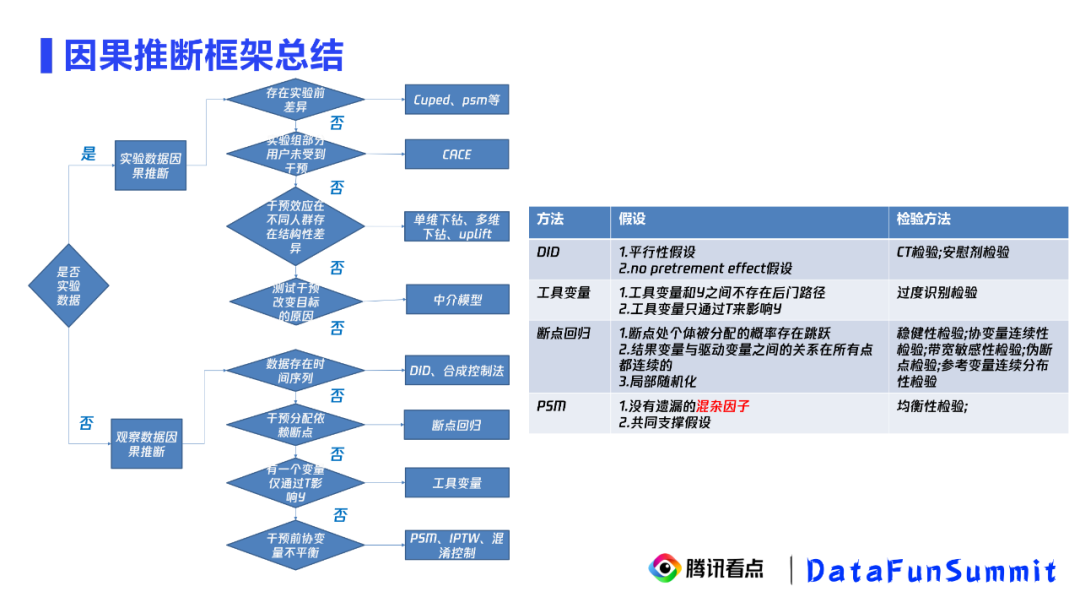
为了绕开观测数据因果推断的问题,我们引入了准实验。从目前因果推断整体的分析框架中可以看到准实验所处的位置,左图包含实验数据和观测数据的因果推断。其中,在观测数据的因果推断中,我们会优先看数据是否满足DID(Differences In Difference,双重差分)、工具变量和断点回归的前提要求。如果满足,会优先使用这三种方法;如果不满足,才会使用PSM(Propensity Score Matching,倾向评分匹配)和混淆PSM方法。这种优先级的原因是相比于PSM,前三种方法绕开了混杂因子,这是唯一的也是最重要的区别。因此它们依赖的假设在业务层面更容易得到满足,同时也很容易被检验,这样的结论也更容易被信服。我们把上面的三种方法称为准实验方法。下面,我们来看看准实验方法在腾讯看点中的应用案例。
02
1. DID双重差分-天气资讯分析

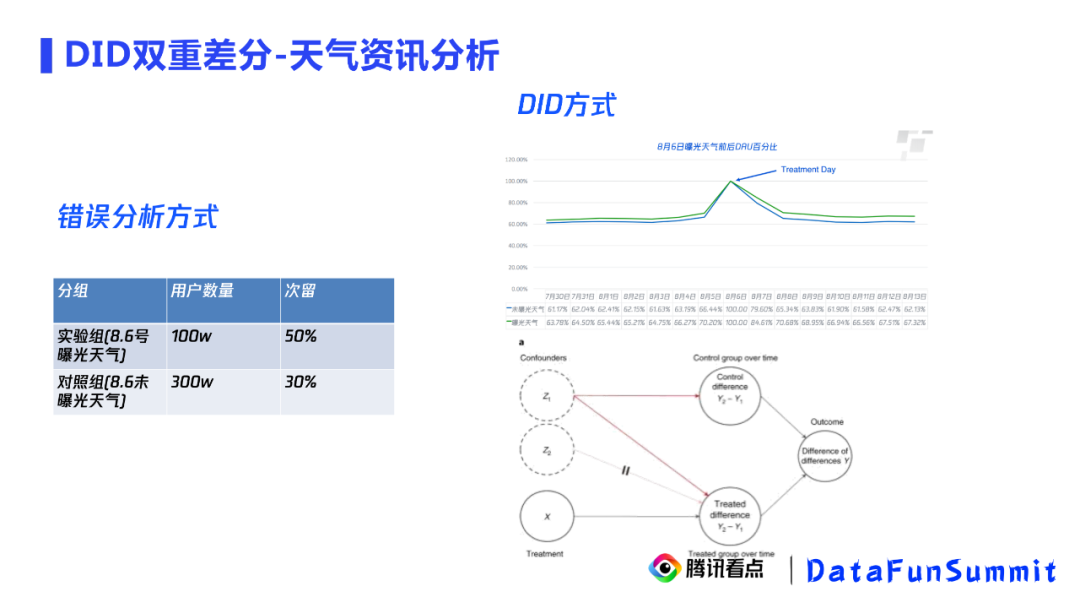
DID在腾讯看点中是一个常用的方法,我们用DID发现了在极端天气下,天气资讯对用户留存的影响。去年8月6号,是台风黑格比经过的时间,我们希望在这样极端的天气下,推送天气的咨询是否能提升用户留存。
对于这个问题,我们首先想到如下实验:
实验组:8月6号曝光天气的用户
对照组:8月6号未曝光天气的用户
结论:曝光天气的用户次留相比于未曝光天气的用户次留高了20%。
事实上,这个结论肯定是错误的。因为曝光天气和未曝光天气这两组用户本身就不平衡,因为我们通常是给活跃用户曝光。因此,这样得到的结论是带有混淆偏差的。
因此,我们又想到如下实验:
实验组:前期未曝光天气,8月6号曝光天气的用户作为实验组
对照组:前期未曝光天气,8月6号未曝光天气的用户作为对照组
结论:曝光天气的用户相比于未曝光天气的用户在受到干预之后,次留扩大了1.4%
基于上述结论,我们判断天气内容的曝光对次留是有因果效应的。为什么说这就是因果效应呢?双重差分中,第一层差分指的是实验组和对照组在实验前后的差异,我们在右上图看到了实验前的平行性是满足的,可以认为混淆变量对实验组和对照组的第一重差分是相等的,那么影响第二重差分(实验组和对照组差分的差分)的因素就只有干预本身了。因此,我们可以通过二次差分得到一个因果效应,也就是这里的1.4%。

为了证明因果结论的正确性,我们验证了天气内容曝光后的转化路径,主要是点击率以及留存。我们发现及时、准确及本地的点击内容的准确性是远超于的大盘的,同时这个高点击率还能延续到第二天,说明这样的内容能够让用户感受到平台的关心,从而带来次留的提升。根据这样的因果结论,我们最终建议对天气做一个单独的推荐和链路审核策略。因为天气对及时性的要求更高,例如,一旦天气过时了一个小时,极端天气已经过了,这样的内容就容易引起反感。因此,链路侧需要有一个更加特定的审核策略,来保证天气内容的供应。同样,推荐策略也需要考虑及时性和本地性。此外,我们还在表达形态上提出建议,我们希望将天气内容单独占据一个资源位。
2. 断点回归-小说业务应用
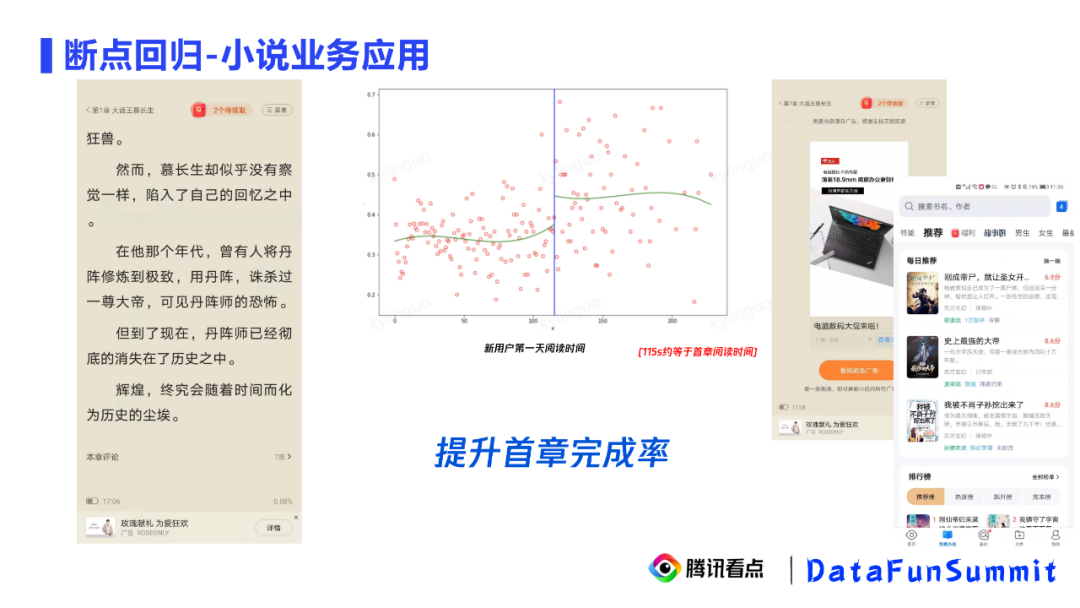
在小说业务中我们发现,提升新用户的首章完成率可以提升新用户的次留。我们可以看到中间这张图,横轴是新用户第一天的阅读时间,纵轴是新用户的次留。我们发现新用户第一天的阅读时间和次留间存在明显的端点,大概在115s左右。这个时间大约是阅读完一章的时间。因为是新用户,所以是新用户的首长阅读时间。因此我们发现了提升新用户的首章完成率对新用户的次留有因果效应。为什么说这是因果效应呢?因为115s左右是一个连续的邻域,我们可以认为其在邻域中各种混淆变量基本不会有太大的差异。根据这个结论,我们应该以提升新用户的首章完成率作为目标。针对这个目标,我们有如下建议:
在首页推荐时,以小说易读率作为一个指标,不优先考虑进入节奏比较慢的小说
取消首章阅读的广告,来提升首章完成率,从而提升用户的次留
类似的问题还有很多,下面我们针对一个启动重置类问题来做一个详细的分享。
1. 产品描述

下面我们拿QQ浏览器的两个使用场景来说明什么是启动重置类问题:
① 首页重置
用户在上一次搜索完感兴趣的内容后,从搜索页面退出。过了一段时间后再返回,发现页面已经变成了信息流首页。这个功能的目的是为了提升信息流的曝光,但我们担心这个功能可能会影响用户的搜索体验,从而影响用户的的活跃度。
② 闪屏
用户在上一次使用完app后,隔一段时间返回,又会出现app的启动加闪屏广告。这个功能设计的目的是提高商业化的收入,但我们也担心这样的设计会得不偿失。
那么针对这样的启动重置类问题,在没有数据的情况下,我们怎么去评估启动重置类策略的总收益呢?下面,我们用首页重置问题作为我们主要的例子进行方案的讲解。
2. 通用分析框架
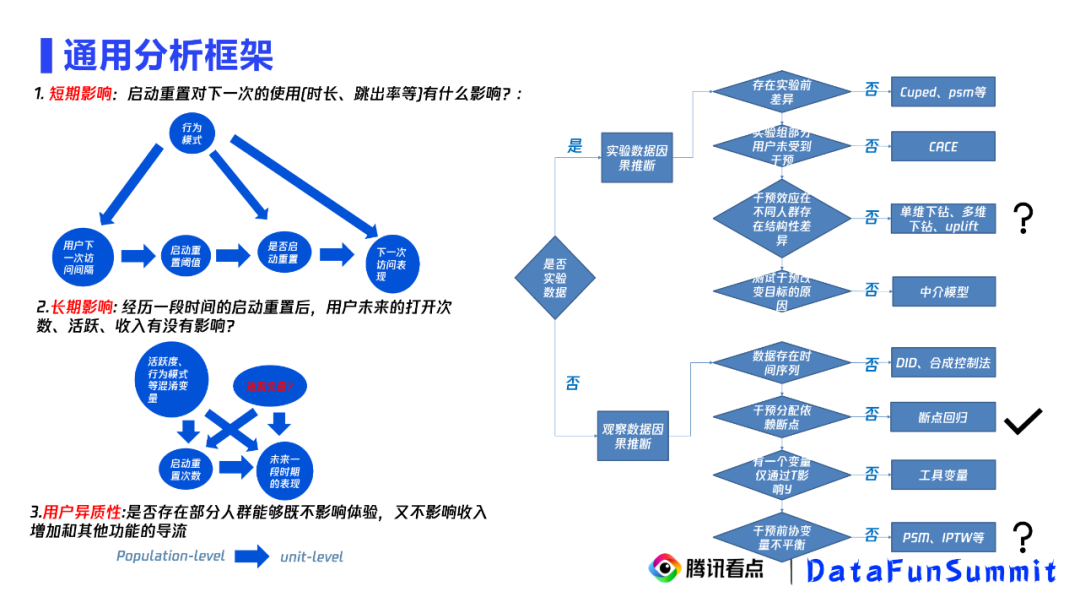
针对这类问题,我们提出一套通用的观测数据因果推断分析方式来给出答案。我们主要关注三个问题,第一个问题启动重置对下一次的使用有没有影响? 第二个问题 一段时间的启动重置下来对用户的未来的打开次数,活跃,收入是否有影响? 前两个问题解决后,我们关心是否存在部分人群能够既不影响体验,又不影响收入增加和其他功能的导流。这三个问题又称为短期影响、长期影响和用户异质性分析。
考虑前面给出的分析框架,我们发现都有相应的解法。
① 短期影响
由于用户是否被启动重置,只取决于用户的访问时间在40分钟右侧还是左侧,那么对于这类问题很适合用断点回归的方式解决。
② 长期影响
长期影响依赖于很多混淆变量,它适合用PSM、混淆控制的方式处理。前面提到,如果我们考虑PSM和匹配方法有一个难题——它的结论很容易被挑战,因为不存在遗漏的混杂因子是无法被证明的。如何解决这个问题是个难点。
③ 用户异质性
异质性分析的前提是实验数据,或者说准实验数据,如何去获并分析短期和长期干预的准实验数据呢?同时在我们的场景中,我们关注多个指标和解释性,异质性没有一个直接可以满足的方法。那么现有的下钻分析和uplift能满足这样的目标吗?
针对这三个问题,我们分别进行阐述。
3. 短期整体效应
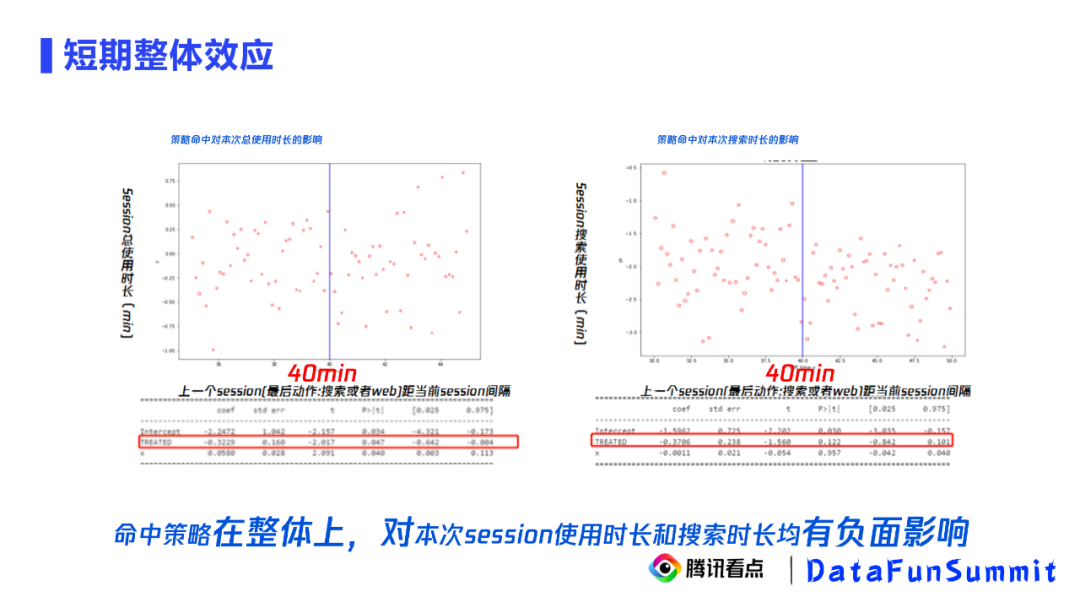
考虑用户在退出app又返回、被启动重置打乱后的这次访问对搜索使用时长和总使用时长的影响。选择这两项的原因是看搜索使用时长可以看启动重置会不会影响用户本次的搜索意愿,看总使用时长可以看启动重置是否确实给用户做到了信息流导流。
具体来看上面两张图,横轴是用户距离上一次的访问间隔,纵轴是session的总使用时长和搜索使用时长。可以看到这两张图在40分钟左右都有一个明显的断点,也就是说短期看,本次访问被重置会导致本次总使用时长和搜索使用时长都下降,这个结论是置信的。
4. 长期整体效应
① 难点
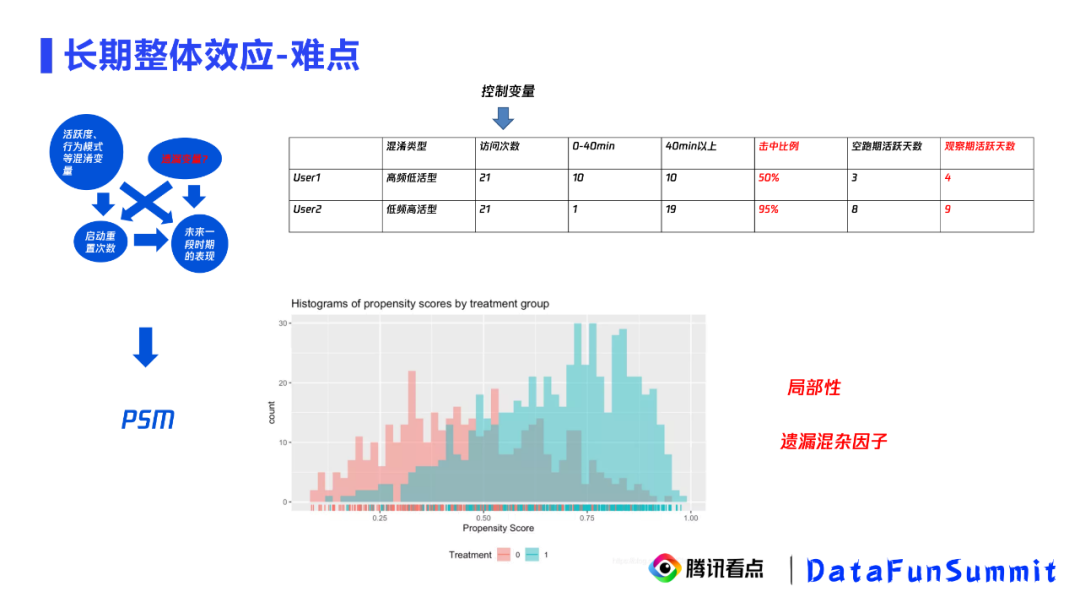
针对长期问题,可以画出如上因果图,考虑一段时间启动重置累积后对用户的影响。长期问题的难点是无法绕开遗漏的混杂因子。比如,我们通过混淆控制的方法去解决这个长期问题,我们先尝试控制用户的活跃度,使其在一段时间内的访问次数都是21,发现击中比例越高的用户的访问天数越多。如果访问次数已经囊括了所有的混淆变量的话,这个结论就是正确的。事实上我们发现,当访问次数都是21的时候,击中比例越高的用户,相当于他们的间隔都比较长,也就是他们是低频高日活型的用户,而击中比例越低的用户,他们正好是高频低日活型的用户。也就是说,我们控制了访问次数,却没有控制住用户的访问模式。这样得出的结论也是错误的。
当然,我们可以用PSM把这些所有可能的混淆变量一步步都考虑进去。但同样会存在两个问题,一是局部性问题,PSM匹配的样本只是样本中的一小部分,无法代表整体样本,二是遗漏的混杂因子的问题依然无法解决。下面给出我们的解决办法。
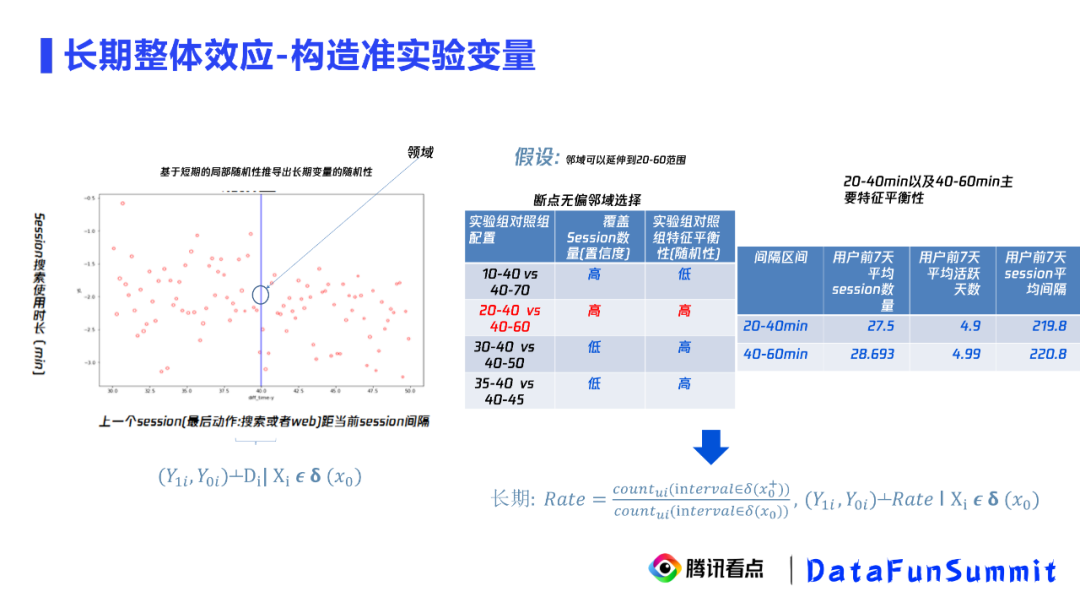
② 构造准实验变量
我们的解决办法是构造了一个长期的准实验变量来绕开混杂因子的难点。
准实验:
在短期的断点回归中,我们可以看到因为访问间隔会随机地落在40分钟的左右两侧,因此在40分钟邻域构成一个准实验。从业务的视角看,这个准实验是用户无法感知这次访问距离上一次是过了39分钟还是41分钟,他是无法感知到这个差异的,这导致来访的用户的各种变量也是随机分配到这个区间的。那么这个邻域是否能一定程度地扩大呢,能否扩大到30到50分钟或者20到60分钟呢?
邻域选择:
邻域的选择是置信度和随机性的折中。当范围越大的时候,我们覆盖的样本就越多,但随机性会变差。当范围越小的时候,随机性很好,但覆盖的样本很少,从而置信度会受到质疑。最终,选择了20到60分钟这个区间。我们还通过特征平衡性来证明这两个区间的样本在各项重要特征上都是比较接近的。
构造变量:
因为我们已经证明了用户的访问行为落在20到40分钟和40到60分钟是一个几乎随机的事件,那么我们可以基于这个事件去构造一个长期的随机变量,就是用户在一段时间内落在40到60分钟的次数除以落在20到40分钟的次数,用这个比例作为长期的准实验变量。
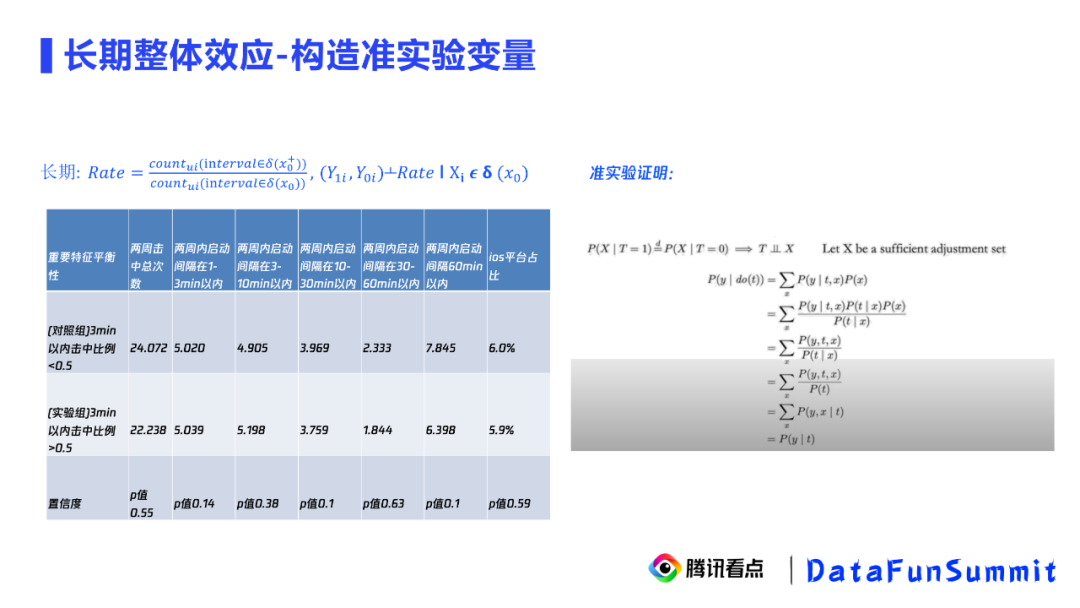
我们用上表按照长期的击中比例来分组,我们发现两组用户在两周内各项数据都没有明显差异。也就是说,我们的长期Rate比例是与各种混淆因子独立的,也就是T独立于X。那么我们可以证明,Rate和活跃天数Y的因果性是等于相关性的。在右图做了大量证明,我们说明了准实验变量的相关性是等于因果性的,我们就可以直接去观测T和Y的关系,也就是我们构造出来的Rate和活跃天数的关系。
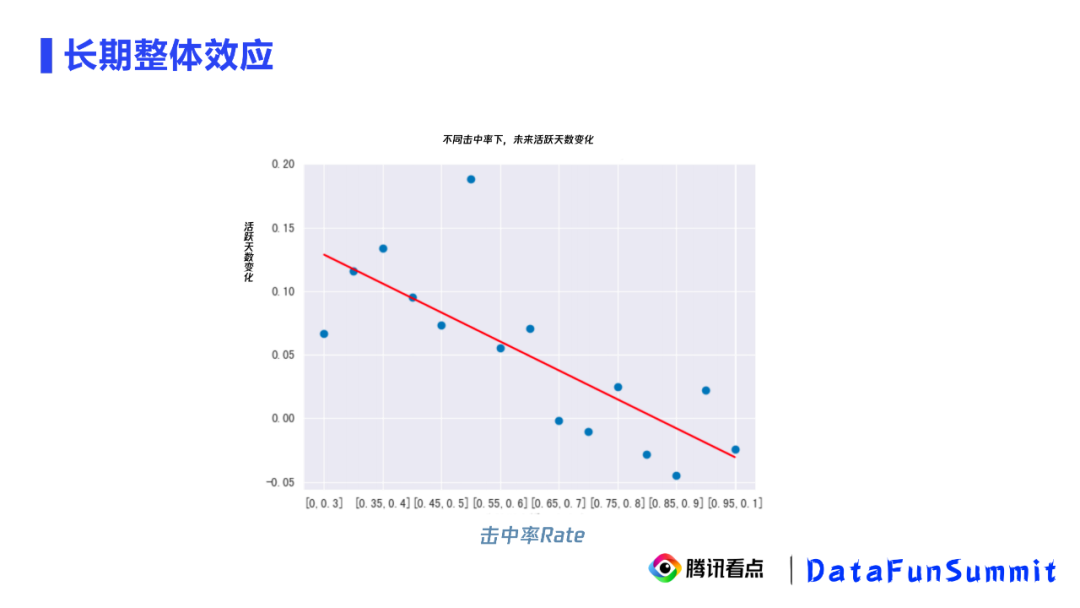
我们发现,我们构造的Rate越大,活跃天数下降得越多。也就是长期来看,一段时间内被启动重置打断的次数比例越高,那么其击中活跃天数越低。这样,我们就解决了长期效应的问题。
5. 异质性效应
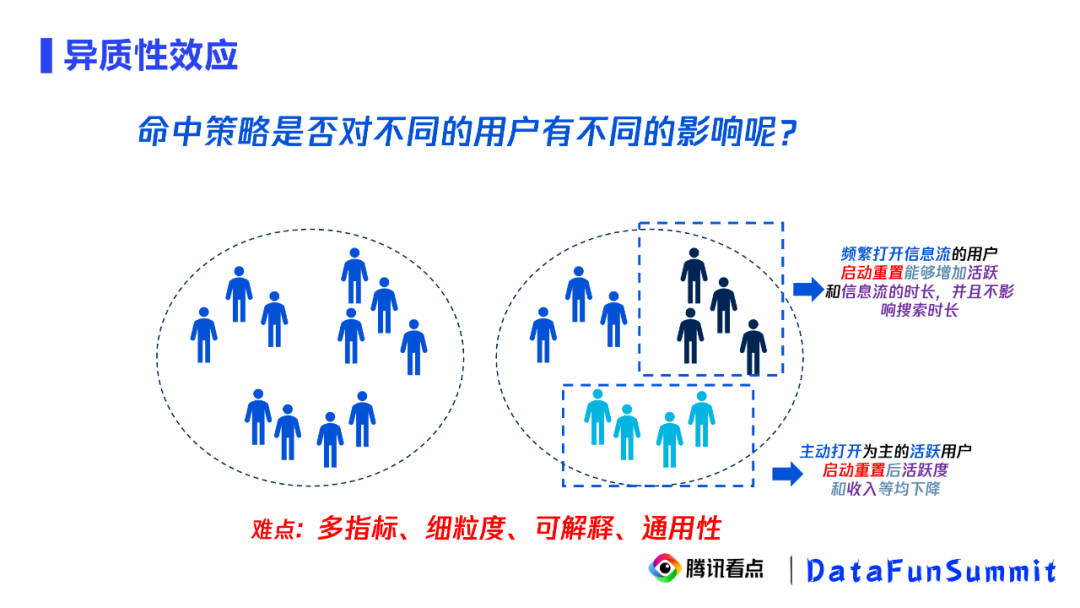
如果说整体上的结论,短期整体和长期整体的结论是显而易见而且直觉的,那么第三个问题细分人群的结论就不是那么显而易见了,异质性分析的前提是实验或者准实验。前面,我们已经构造了准实验变量,创造了无偏样本。下面,我们希望通过异质性分析找到不同人群在不同干预措施下的不同效果,然后去去改善策略。
比如,我们发现主动打开为主的活跃用户在被启动重置打断后的活跃度和收入都出现了下降,那么对于这类用户我们就应该下架策略。又比如,我们发现启动重置打断不仅会增加频繁打开信息流用户的活跃度和信息流的时长,还不影响他们的搜索时长,那么对于这类用户我们就可以执行启动重置策略。
这里的难点是我们的目标指标有多个,包括搜索时长、信息流时长、收入。同时,用户的标签维度很高,包括主动打开、频繁打开信息流等。同时,我们要把这样的结论通过算法解释并满足通用性。需要同时满足这四个要求是个难点。
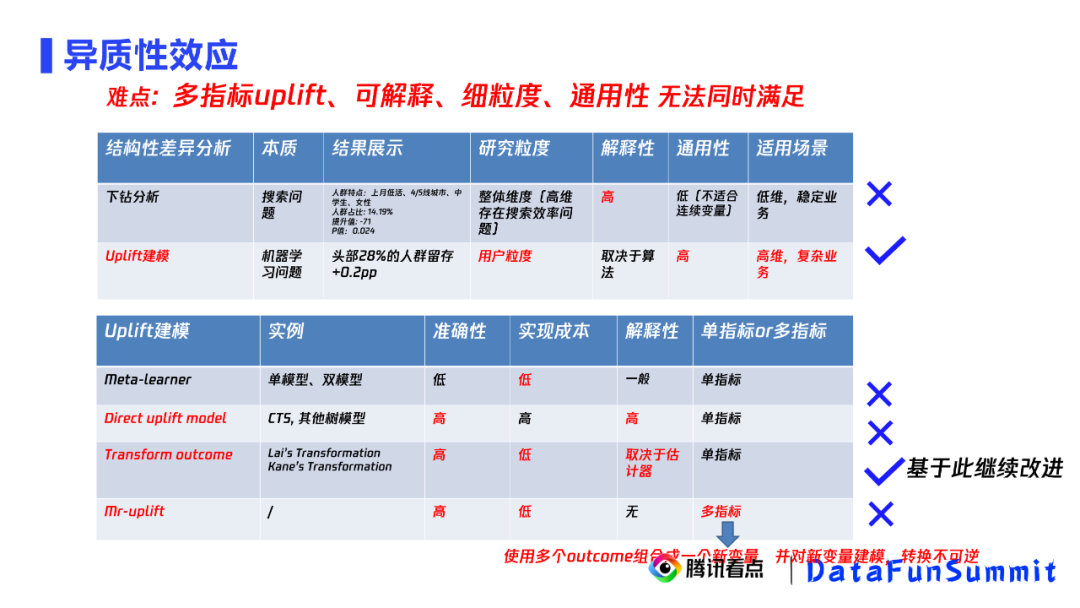
通过调研发现,这四个要求是很难同时满足的。从前面的分析框架中,我们可以看到,异质性分析主要包括下钻分析和Uplift分析。在下钻分析和Uplift分析的调研中,我们发现了解释性、通用性和细粒度之间矛盾。下钻分析有比较好的解释性但通用性比较差,因为它不太适合处理连续变量,而且它一旦遭遇维度比较高的问题会有搜索效率的问题。Uplift在通用性和研究粒度上没有问题,但是它的解释性较差,比较适合高维和复杂业务。可以看到,在我们的问题中Uplift更加满足要求。
我们继续调研Uplift发现,Transform outcome的方法是更满足我们的要求的,它相比Meta-learner有更高的准确性,同时相比于Direct uplift model有更低的实验成本,但问题是,它只适合于单指标的建模。那么多指标的uplift的建模,我们目前了解到的只有Mr-uplift方法。它的实验方法是用多个outcome组成一个新的outcome,然后对新的变量建模。这个转换是不可逆的,也就是说我们的变量对原始的outcome的uplift是无法被复原的。因此我们发现,只有Transform outcome最满足我们的要求,下面我们对其进行改造。
① 异质性分析
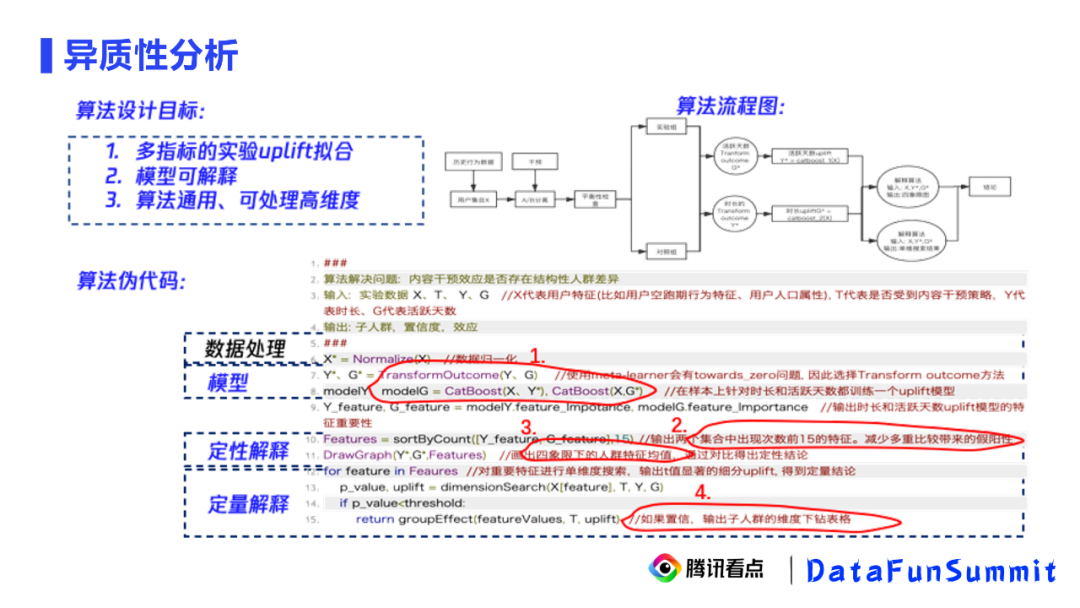
我们的算法目标有3个:
多指标的实验uplift拟合
模型可解释
算法通用、可处理高维度
下面,我们用伪代码来呈现我们是怎么达到以上目标的,主要是四个步骤:
Step1:在数据处理后,先通过Transform outcome去转换我们原始的Y和G。新的变量会被称为Y*和G*。然后对新的变量分别用CatBoost拟合模型。
Step2:输出模型的重要特征,并选择出现次数最多的,用前15个或前10个解释细分人群。
Step3:通过两个模型预测的uplift的正负值划分四个象限,比较不同象限的人群在Step2中得到的重要特征的均值差异,得到一个定性的结论。
Step4:通过Step3的定性结论做一个单维度的搜索,得到定量的结论。然后输出每个维度子人群的uplift的绝对量值以及置信度。
算法效果对比:
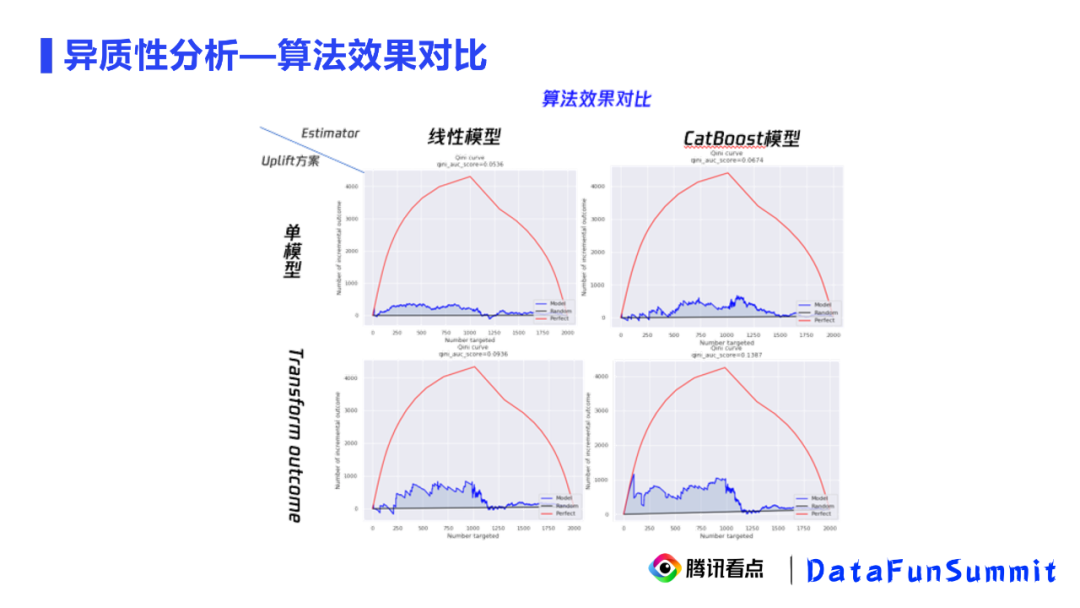
我们通过Gini Score来评估这4种模型方案的准确性,黑线代表的是随机实验的效果,蓝线代表的是当前模型的效果,与黑线构成的面积越大效果越好。红线是理论上能够达到的最大值,但是它不能说明是最优效果,只能说是一个量高。我们发现Transform outcome加CatBoost的模型效果最好,Gini面积达到了0.1387,比单模型方法的效果好两倍。
算法运行结果:
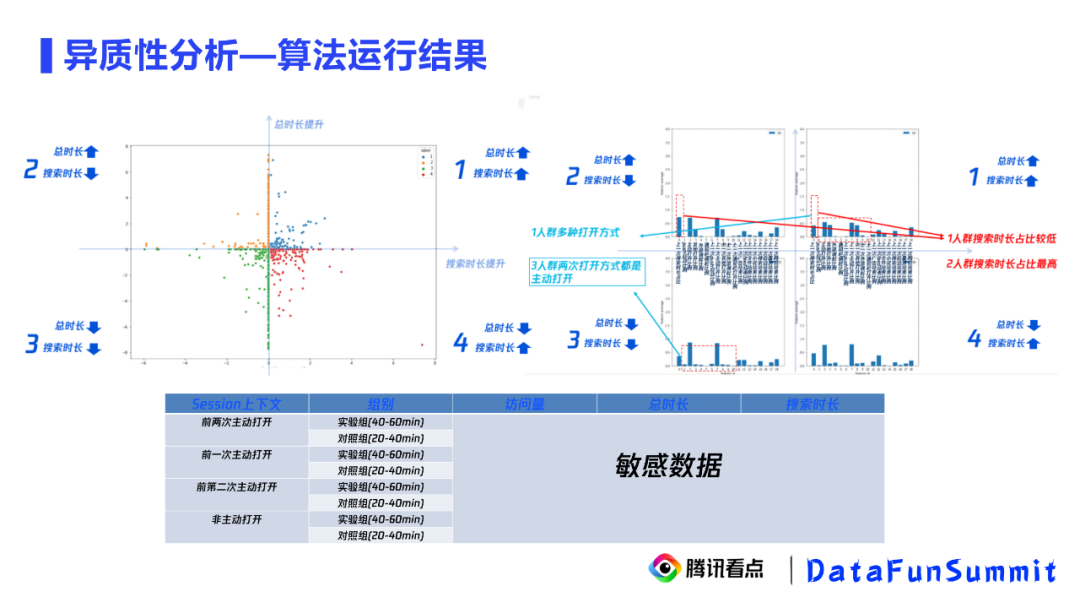
拿短期异质性来举例,我们希望知道不同上下文的访问行为在被启动重置打断后,在搜索使用时长和总使用时长上有没有什么不同的表现。首先,我们根据算法画4个象限图,我们根据总时长和搜索使用时长分别建立一个uplift模型,横轴为搜索使用时长的uplift,纵轴为总使用时长的uplift,每个点表示一次不同上下文的访问行为。那么第一象限代表被启动重置后,其总时长和搜索使用时长都会有提升,第三象限代表被启动重置后,其总时长和搜索时长都会有明显的下降。
接着,我们得到这两个模型的重要特征,然后对比四象限的人群在这些重要特征的均值上的差异。对比第一象限和第二象限,我们发现第一象限的人群搜索时长相比于第二象限的人群搜索时长的占比更低,这说明启动重置策略对搜索时长占比较高的用户可能会下降搜索意愿。对比第一象限和第三象限,我们发现第一象限的打开方式有多种,而第三象限的打开方式主要是主动打开,这说明对主动打开的用户,启动重置策略会引起反感,不仅会降低搜索意愿并且对信息流导流不感兴趣。对于这类用户,我们需要采用下架策略。这样的定性结论到底是正确还是错误,我们还需要定量验证。
对前两次打开方式做一个细分,每一种上下文我们都区分实验组和对照组。通过对比这四种细分上下文实验组和对照组的总时长和搜索时长的差异,得到真实的离线数据的总时长uplift和搜索时长uplift。最终来确定量化的uplift和置信度。
这是短期异质性的四象限分析算法效果,长期异质性也是一致的。
启动重置类问题结论:

最终我们得到,整体上短期和长期的启动重置策略都有副作用。但区分用户看,可以发现可以对搜索活跃度较低的用户保持现有策略,对搜索活跃度相对较高的用户下架现有策略。更加精细化地,我们可以区分不同session上下文的行为。到这里,我们已经说完了异质性的结论。在分析过程中,我们发现启动重置对搜索用户的影响更大。因此,我们特别对产品平台上做了建议,就是在搜索用户搜索完退出再返回时,切换时增加一个动画,提醒用户之前的上下文已经被收纳到这个窗口里了,让用户主动选择是继续之前的上下文还是来到新的信息流页面。
到这里,我们就已经解决了之前提出的3个问题,我们用断点分析解决短期影响,用uplift解决长期影响,用改良的准实验构造解决用户异质性。
今天的分享就到这里,欢迎大家加入腾讯看点,来和我们一起研究因果推断相关的工作。谢谢大家!
Q:Uplift建模和相关性建模有什么区别?
A:我们举个例子来解释这个问题。我们在淘票票购买电影票的时候会发现它会给你投放一个红包,如果只用相关性去看用户购买电影票和投放红包之间有没有相关性的话,肯定是有相关性的。但是其实这里面存在两种人群,一种是不给他投放他也会买电影票,另一种是只有给他投放了红包他才会买。这两种人群在相关性分析中是不能区别的,而在uplift中可以区分,因为uplift计算的是投放红包相比于不投放红包得到的增益。这就是uplift和相关性建模主要的区别。
Q:p值是如何计算的?
A:因为我们这里有大量样本,我们会找到所有细分用户的不同session行为,把实验组和对照组的行为都捞出来,就可以对每个用户建立一个统计量,根据检验统计量的具体分布,可以得到p值。常用的统计量
Q:在异质性分析中,为什么既要定性解释还要定量解释?只做一种有问题吗?
A:如果只有定性解释,是有问题的。我们可以看到四象限人群,定性解释是对每一象限人群的均值做一个比较,但是第一象限人群中有uplift值比较低的,也有比较高的,把它们混在一起看均值可能导致均值被平均化、不明显,或者得到一个错误的结论。加入定量解释,可以区分每个行为得到的最终uplift绝对值,解决了把不同uplift混在一起的问题,最终通过uplift的值得到精准的uplift的值。
如果只有定量解释,也有问题。定量解释是一个单维度搜索,是无法感知高维有多个特征同时显现出差异的细分人群,通过定性解释可以增加更高维的视野。
Q:DID和传统AB test得到的结论有什么不同?
A:抛开错误的打开效应,传统的AB test是一个直接的因果效应,区别在于实验的机制。现实中,往往有很多原因导致无法实验,比如历史遗留问题。在这种情况下,我们在AB test前,需要把各种变量控制好,否则无法得到结论;在DID前即使没有控制好,也能得到结果。
Q:怎么识别启动重置类问题?
A:用户在上一次访问app后过了一段时间再回来,可能会失去之前的上下文,这个过程叫启动重置。我们评估的是这个设计会不会对效益有负面作用。之前说的20到40分钟或40到60分钟是我们针对我们的数据评估出的随机区间,如果换一个业务场景可能需要通过特征提升性的方法来验证选取的区间是随机的。
Q:Uplift建模时怎么控制实验组和对照组的变量分布一致?
A:这个有多种方法。针对于观测数据,一般可以通过PSM构造无偏样本,对无偏样本去做uplift,也可以像我们这里启动重置这里的分析方法,构造一些依赖断点回归的拓展构造无偏样本,对无偏区间做一个uplift。
Q:Uplift怎么捞出对策略不同反应的用户?每个用户都有一个uplift值吗?
A:每个用户都有自己的属性和预测的uplift值。每个用户都有一个uplift值,用户属性需要解释uplift模型才能得到的。我们把相同属性和相同或近似的uplift的值聚合解释出来,就得能到有效策略。
今天的分享就到这里,谢谢大家。
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“因果推断” 就可以获取《因果推断专知资料》专知下载链接




