近期必读的七篇 ICLR 2021【因果推理】相关投稿论文
1、Accounting for unobserved confounding in domain generalization
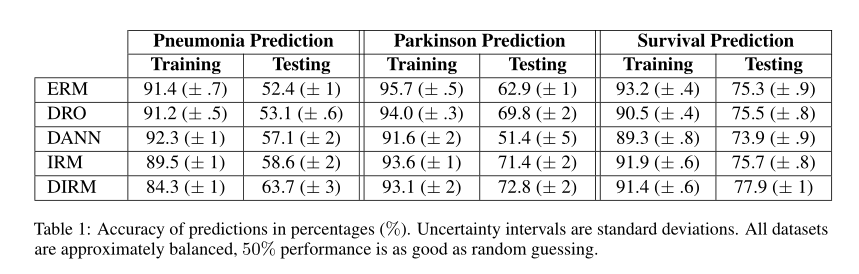
摘要:从观察到的环境到在新的相关环境进行推断或推广的能力是可靠机器学习的核心,然而大多数方法在数据过多时都会失败。在某些情况下,由于对所支配数据的因果结构的误解,特别是未观察到的干扰因子的影响,这些干扰因子使观察到的分布发生变化,并扭曲了相关性。在这篇文章中,我们提出定义关于更广泛类别的分布移位(distribution shifts)的泛化(定义为由潜在因果模型中的干预引起的),包括观察到的、未观察到的和目标变量分布的变化。我们提出了一种新的鲁棒学习原则,它可以与任何基于梯度的学习算法配对。这一学习原则具有明确的泛化保证,并将鲁棒性与因果模型中的某些不变性联系起来,表明了为什么在某些情况下,测试性能落后于训练性能。我们展示了我们的方法在来自不同模态的医疗数据(包括图像和语音数据)上的性能。
网址:
https://openreview.net/forum?id=ZqB2GD-Ixn
2、Amortized causal discovery learning to infer causal graphs from time series data
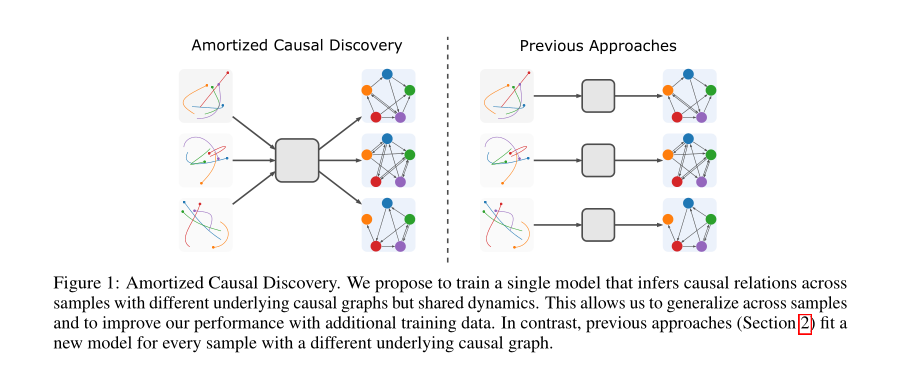
摘要:标准的因果发现方法无论何时遇到来自新的基本因果图的样本,都必须适合一个新的模型。然而,这些样本经常共享相关信息(例如,描述因果关系影响的动态信息),这些信息在遵循这种方法时会丢失。我们提出了一个新的框架-摊销因果发现(Amortized Causal Discovery),它利用这种共享的动力来学习从时间序列数据中推断因果关系。这使我们能够训练一个单一的摊销模型,该模型推断具有不同基本因果图的样本之间的因果关系,从而利用共享的信息。我们通过实验证明了这种以变分模型实现的方法在因果发现性能方面有了显著的改进,并展示了如何将其扩展以在 hidden confounding情况下很好地执行。
网址:
https://openreview.net/forum?id=gW8n0uD6rl
3、Continual lifelong causal effect inference with real world evidence
摘要:当前观测数据非常容易获取,这极大地促进了因果关系推理的发展。尽管在克服因果效应估计方面的挑战方面取得了重大进展,在缺少反事实数据(counterfactual outcomes)和选择偏差的情况下,但是现有方法只关注特定于源的和稳定的观测数据。本文研究了从增量观测数据中推断因果关系的一个新的研究问题,并相应地提出了三个新的评价标准,包括可扩展性、适应性和可达性。我们提出了一种连续因果效应表示学习(Continual Causal Effect Representation Learning )方法,用于估计非平稳数据分布中增量可用的观测数据的因果效应。我们的方法不是访问所有可见的观测数据,而是仅存储从先前数据学习的有限的特征表示子集。该方法将选择性均衡表示学习、特征表示提炼和特征变换相结合,在不影响对原始数据估计能力的前提下,实现了对新数据的连续因果估计。大量实验证明了连续因果推理的重要性和方法的有效性。

网址:
https://openreview.net/forum?id=IOqr2ZyXHz1
4、Counterfactual generative networks
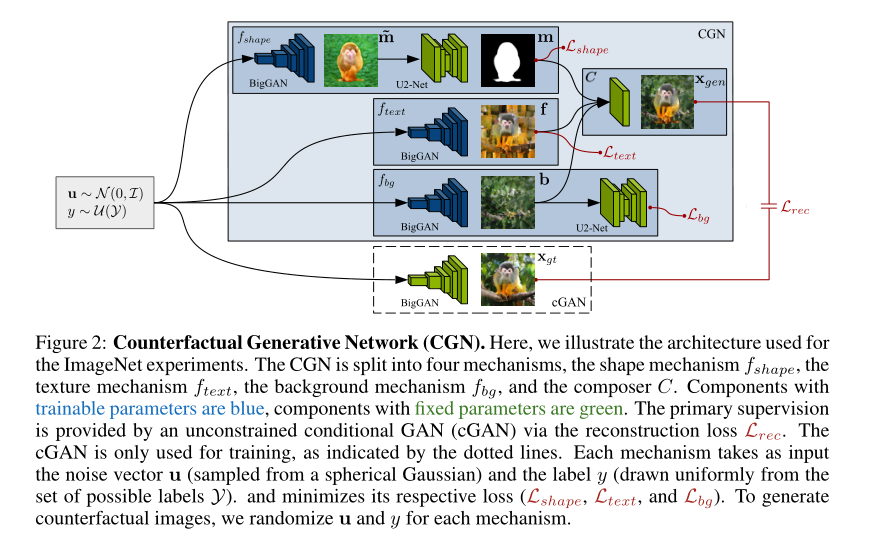
摘要:神经网络很容易找到学习捷径--它们经常对简单的关系进行建模,而忽略了可能更好地概括更复杂的关系。以往的图像分类工作表明,深度分类器不是学习与物体形状的联系,而是倾向于利用与低层纹理或背景的虚假相关性来解决分类任务。在这项工作中,我们朝着更健壮和可解释的分类器迈进,这些分类器显式地揭示了任务的因果结构。基于目前在深度生成建模方面的进展,我们提出将图像生成过程分解为独立的因果机制,我们在没有直接监督的情况下对这些机制进行训练。通过利用适当的归纳偏差,这些机制将对象形状、对象纹理和背景分开;因此,它们允许生成反事实图像。我们演示了我们的模型在MNIST和ImageNet上生成此类图像的能力。此外,我们还表明,尽管反事实图像是人工合成的,但它们可以在原始分类任务的性能略有下降的情况下,提高分布外的稳健性。最后,我们的生成式模型可以在单个GPU上高效地训练,利用常见的预训练模型作为归纳偏差(inductive biases)。
网址:
https://openreview.net/forum?id=BXewfAYMmJw
5、Disentangled generative causal representation learning
摘要:这篇文章提出了一种解缠的生成式因果表示(Disentangled Generative Causal Representation,DEPE)学习方法。与现有的强制独立于潜在变量的解缠方法不同,我们考虑的是潜在因素可以因果关联的一般情况。我们表明,以前的方法与独立的先验不能解开因果相关的因素。受这一发现的启发,我们提出了一种新的解缠学习方法DELE,该方法实现了因果可控生成和因果表示学习。这一新公式的关键是使用结构因果模型(SCM)作为双向生成模型的先验。然后,使用适当的GAN损失与生成器和编码器联合训练先验。我们给出了所提公式的理论证明,保证了在适当条件下的解缠因果表示学习。我们在合成和真实数据上进行了广泛的实验,以证明DEAR在因果可控生成方面的有效性,以及学习的表示在样本效率和分布稳健性方面对下游任务的好处。

网址:
https://openreview.net/forum?id=agyFqcmgl6y
6、Explaining the efficacy of counterfactually augmented data
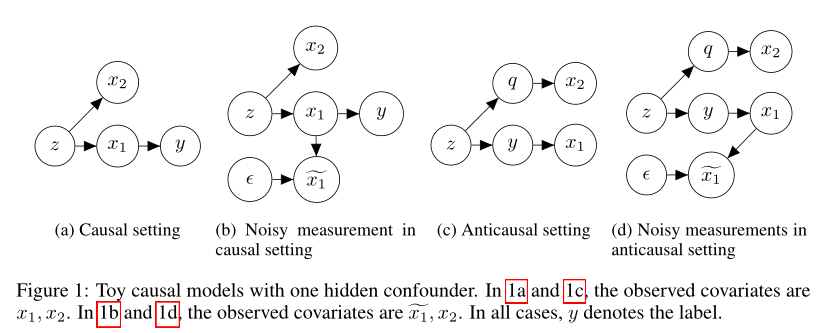
摘要:为了减少机器学习模型对训练数据中虚假模式的依赖,研究人员最近提出通过human-in-the-loop进程来生成与事实相反的增强数据。正如在NLP中所应用的那样,给定一些文档及其(初始)标签,人类的任务是修改文本以使(给定的)反事实标签适用。重要的是,这些说明禁止进行翻转适用标签时不必要的编辑。在扩充(原始和修订)数据上训练的模型已被证明较少依赖语义无关的单词,并能更好地概括域外。虽然这项工作借鉴了因果思维,将编辑塑造为干预措施,并依靠人类的理解来评估结果,但潜在的因果模型并不清楚,也不清楚在域外评估中观察到的改进背后的原则。在这篇文章中,我们探索了一个模拟玩具(toy analog),使用线性高斯模型。我们的分析揭示了因果模型、测量噪声、域外泛化和对虚假信号的依赖之间的有趣关系。有趣的是,我们的分析表明,通过向因果特征添加噪声而损坏的数据将降低域外性能,而向非因果特征添加噪声可能会使模型在域外更加健壮。这一分析产生了有趣的见解,有助于解释反事实增强数据的有效性。最后,我们提出了一个支持这一假说的大规模实证研究。
网址:
https://openreview.net/forum?id=HHiiQKWsOcV
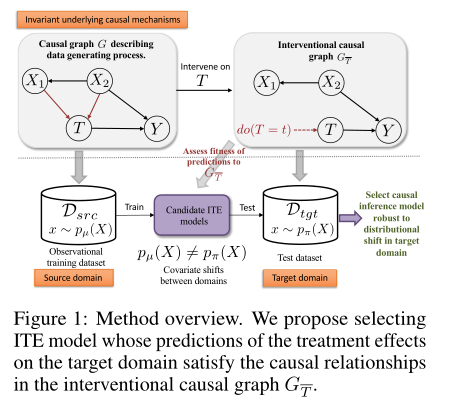
7、Selecting treatment effects models for domain adaptation using causal knowledge
摘要:从观察数据中选择因果推断模型来估计个体化治疗效果(ITE)是一个挑战,因为从来没有观察到反事实的结果。该问题在无监督域自适应(UDA)设置中进一步受到挑战,在该设置中,我们只能访问源域中的已标记样本,但是我们希望选择在仅有未标记样本可用的目标域上实现良好性能的模型。现有的用于UDA模型选择的技术是针对预测设置设计的。这些方法检查源域和目标域中输入协变量之间的判别密度比,并且不考虑模型在目标域中的预测。正因为如此,在源域上具有相同性能的两个模型通过现有方法将获得相同的风险分数,但在现实中,它们在测试域上具有显著不同的性能。我们利用因果结构跨域的不变性来引入一种新的模型选择度量,该度量专门针对UDA设置下的ITE模型而设计。特别是,我们建议选择对干预效果的预测满足目标领域中已知因果结构的模型。在实验上,我们的方法在几个合成和真实的医疗数据集上选择对协变量变化更稳健的ITE模型,包括估计来自不同地理位置的新冠肺炎患者的通风效果。
网址:
https://openreview.net/forum?id=AJY3fGPF1DC
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ICLR2021CI” 就可以获取《7篇顶会ICLR 2021因果推理(Causal Inference)相关论文》的pdf下载链接~





