近期必读的六篇 NeurIPS2020【因果推理】相关论文和代码
1. Causal analysis of Covid-19 spread in Germany
作者:Atalanti A. Mastakouri, Bernhard Schölkopf
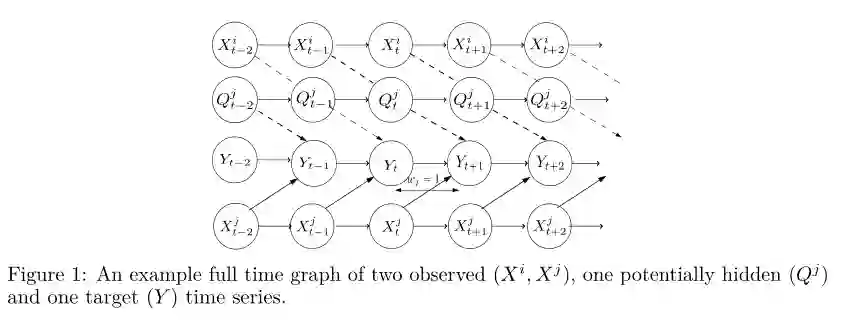
摘要:在这项工作中,我们研究了自大流行开始以来,德国各地区在Covid-19传播方面的因果关系,并考虑了不同联邦州实施的限制政策。本文提出并证明了时间序列数据因果特征选择方法的新定理,该定理对潜在混杂因素具有鲁棒性,并将其应用于Covid-19病例编号。我们报告了病毒在德国传播的发现和限制措施的因果影响,讨论了各种政策在控制传播中的作用。由于我们的结果是基于相当有限的目标时间序列(仅是报告的病例数),因此在解释它们时应谨慎行事。然而,我们发现如此有限的数据似乎包含了因果信号。这表明,随着获得更多数据,我们的因果方法可能有助于对影响Covid-19发展的政治干预措施进行有意义的因果分析,从而也有助于制定合理的、以数据为驱动的方法来选择干预措施。
网址:
https://arxiv.org/abs/2007.11896
2. Algorithmic recourse under imperfect causal knowledge: a probabilistic approach
作者:Amir-Hossein Karimi, Julius von Kügelgen, Bernhard Schölkopf, Isabel Valera
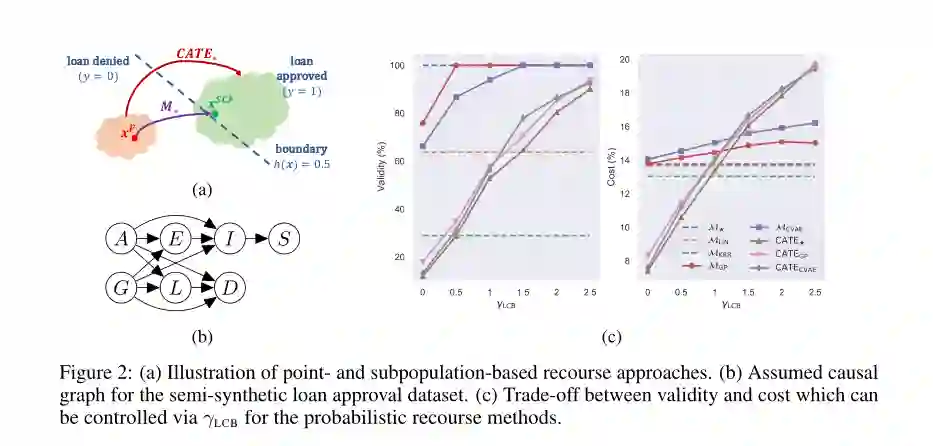
摘要:最近的工作已经讨论了反事实解释(counterfactual explanations)的局限性,以为算法追索权(algorithmic recourse)推荐行动,并认为需要考虑特征之间的因果关系。但是,在实践中,真正的潜在结构因果模型通常是未知的。在这项工作中,我们首先表明,它是不可能保证追索权(recourse)没有获得真正的结构方程。为了解决这一局限性,我们提出了两种概率方法来选择在有限的因果知识(例如:仅因果图)下以高概率实现追索的最优行动。第一个模型捕捉了加高斯噪声下结构方程的不确定性,并使用贝叶斯模型平均估计反事实分布。第二种方法通过计算追索权行为对类似于寻求追索权的平均影响,消除了结构方程上的任何假设,从而产生了一种基于亚群体的新型干预(subpopulation-based interventional notion)追索权概念。然后我们推导了一个基于梯度的程序来选择最优的追索权行动,并且经验地表明,在不完全因果知识下,所提出的方法比非概率基线下的建议更可靠。
网址:
https://arxiv.org/abs/2006.06831
3. CASTLE: Regularization via Auxiliary Causal Graph Discovery
作者:Trent Kyono, Yao Zhang, Mihaela van der Schaar
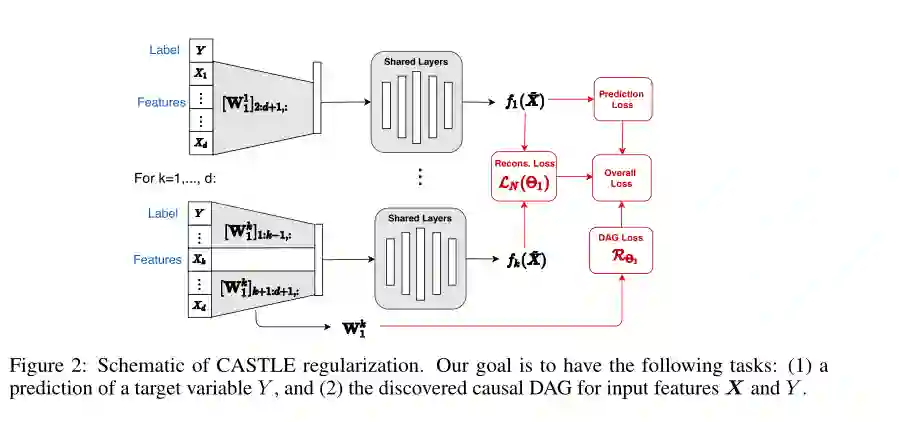
摘要:正则化改进了监督模型对样本外数据的泛化。先前的研究表明,在因果方向(由原因产生的结果)上的预测比在反因果方向上的预测能产生更低的测试误差。然而,现有的正则化方法不知道因果关系。我们引入因果结构学习(CASTLE)正则化,并提出通过共同学习变量之间的因果关系来对神经网络进行正则化。CASTLE学习了因果有向无环图(DAG)作为嵌入在神经网络输入层的邻接矩阵,从而促进了最佳预测器的发现。此外,CASTLE只有效地重构具有因果邻接的因果DAG中的特征,而基于重构的正则化器则次最优地重构所有输入特征。我们为这个方法提供了一个理论泛化边界,并在大量合成和真实的公开数据集上进行实验,证明与其他流行的基准规则相比CASTLE始终导致更好的样本外预测。
网址:
https://arxiv.org/abs/2009.13180
4. Causal Imitation Learning with Unobserved Confounders
作者:Junzhe Zhang, Daniel Kumor, Elias Bareinboim
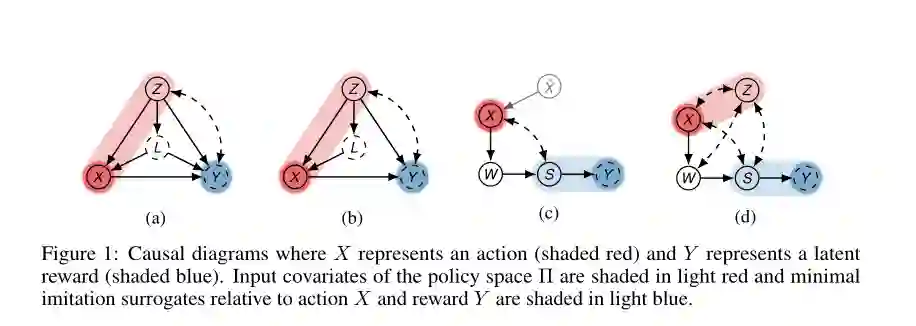
摘要:儿童学习的一种常见方式就是模仿成年人。模仿学习的重点是学习策略与适当的表现,该策略具有由专家产生的演示的适当性能,并具有未指定的性能度量和未观察到的奖励信号。模仿学习的流行方法首先是直接模仿专家的行为策略(行为克隆),或者学习优先观察专家轨迹的奖励函数(逆强化学习)。然而,这些方法依赖于这样一种假设,即专家用来确定其行动的协变量得到了充分观察。在本文中,我们放松这一假设,在学习者和专家的感官输入不同的情况下研究模仿学习。首先,我们提供了一个完整的(既必要又充分的)非参数的图形标准,用于确定模仿的可行性,该标准由有关潜在环境的示范数据和定性假设的组合,以因果模型的形式表示。然后我们表明,当这样一个标准不成立时,模仿仍然可以利用专家轨迹的定量知识。最后,我们开发了一个从专家轨迹学习模仿政策的有效程序。
网址:
https://causalai.net/r66.pdf
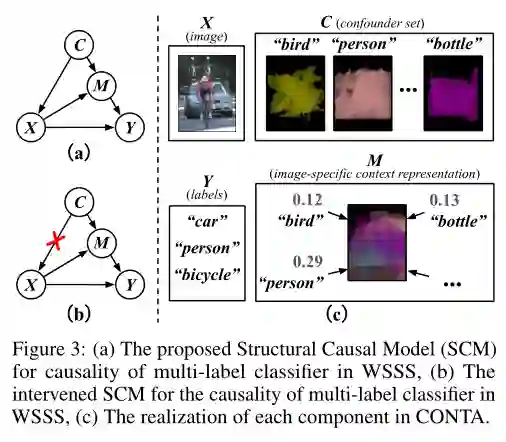
5. Causal Intervention for Weakly-Supervised Semantic Segmentation
作者:Dong Zhang, Hanwang Zhang, Jinhui Tang, Xiansheng Hua, Qianru Sun
摘要:我们提出了一个因果推理框架来改进弱监督语义分割。具体来说,我们的目标是通过仅使用图像级标签(WSSS中最关键的一步)来生成更好的像素级伪图像。我们将伪掩码(pseudo-masks)的边界不明确的原因归因于混淆的上下文。例如,“马”和“人”的正确图像级别分类可能不仅是由于每个实例的识别,还包括它们的共同作用,而且在他们共现的背景下,使模型检验(如:CAM)难以区分界限。受此启发,我们提出一个结构因果模型来分析图像、上下文和类别标签之间的因果关系。在此基础上,我们提出了一种新的方法:上下文调整(CONTA),以消除图像级分类中的混淆偏差,从而为后续的分割模型提供更好的伪掩码(pseudo-masks)作为ground-truth。在PASCAL VOC 2012和MS-COCO上,我们展示了CONTA将各种流行的WSSS方法提升到新的状态。
代码:
https://github.com/ZHANGDONG-NJUST/CONTA
网址:
https://arxiv.org/abs/2009.12547
6. Identifying Causal-Effect Inference Failure with Uncertainty-Aware Models
作者:Andrew Jesson, Sören Mindermann, Uri Shalit, Yarin Gal
摘要:为个人推荐最佳的行动是个人级别因果效应估计的主要应用。在诸如医疗保健等对安全至关重要的领域中,经常需要此应用程序,在这些领域中,对不确定性进行评估并与决策者进行交流至关重要。我们介绍了一种实用的方法,将不确定性估计集成到一类先进的神经网络方法用于个体水平的因果估计。我们的方法使我们能够优雅地处理高维数据中常见的“无重叠”情况,在这种情况下,因果效应方法的标准应用失败了。此外,我们的方法允许我们处理协变量变换,即训练和测试分布不同的情况,这在系统实际部署时很常见。我们表明,当这种协变量变化发生时,正确的建模不确定性可以防止我们给出过度自信和潜在的有害建议。我们用一系列最先进的模型来演示我们的方法。在协变量转移和缺乏重叠的情况下,我们的 uncertainty-equipped方法可以在预测不可信时向决策者发出警告,同时性能优于使用倾向评分来识别缺乏重叠的标准方法。

网址:
https://arxiv.org/abs/2007.00163
请关注专知公众号(点击上方蓝色专知关注)
后台回复“NIPS2020CI” 就可以获取《6篇顶会NeurIPS 2020 因果推理(Causal Inference)相关论文》的pdf下载链接~




