CVPR 2020丨码隆科技提出 SiamAttn,将孪生网络跟踪器的性能提至最优水平

编辑 | 丛 末

论文地址:https://arxiv.org/abs/2004.06711
本篇论文中,码隆科技提出了可变形孪生注意力网络(Deformable Siamese Attention Networks,缩写为 SiamAttn),以此来提升孪生网络跟踪器的特征学习能力。这种注意力机制为跟踪器提供了一种自适应地隐式更新模板特征的方法。实验表明,SiamAttn 明显超越了现有最新算法,达到了目前的最优水平。
基于孪生网络的目标跟踪器在视觉目标跟踪任务上取得了非常出色的表现。然而,在以往大多数孪生网络跟踪器中,它们的目标模板特征在跟踪过程中都是不会进行更新的;并且目标与搜索区域的特征在计算过程中相互独立,这是现有孪生网络跟踪的性能瓶颈所在。
不同于以往的方法,在本文中,我们提出了可变形孪生注意力网络(Deformable Siamese Attention Networks,缩写为 SiamAttn),以此来提升孪生网络跟踪器的特征学习能力。为此,我们设计一个新的孪生注意力机制,其中包括可变形的自注意力机制和互注意力机制。自注意力机制通过空间注意力和通道注意力可学习到强大的上下文信息和选择性地增强通道特征之间的相互依赖;而互注意力机制则可以有效地聚合与沟通模板和搜索区域之间丰富的信息;可变形卷积层的加入使得该模块能更灵活地根据目标外观对卷积区域进行采样。这种注意力机制为跟踪器提供了一种自适应地隐式更新模板特征的方法。
此外,我们还设计了一个区域修正模块来对预测结果进行修正,该模块进一步预测目标更准确的包围框和目标的掩膜,最终得到更准确的跟踪结果。
下方的 gif 展示了部分 SiamAttn 在 VOT2018 数据集上的测试结果,我们在六个标准的跟踪性能测试集上测试了 SiamAttn,和另外四个高水准的跟踪器结果对比可见,SiamAttn 的跟踪结果要更加准确,并且对于目标的外观变化、复杂背景、遮挡以及邻近物体的干扰更加鲁棒。因此实验表明 SiamAttn 明显超越了现有最新算法,达到了目前的最优水平。




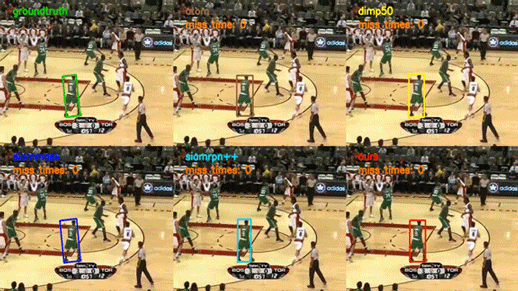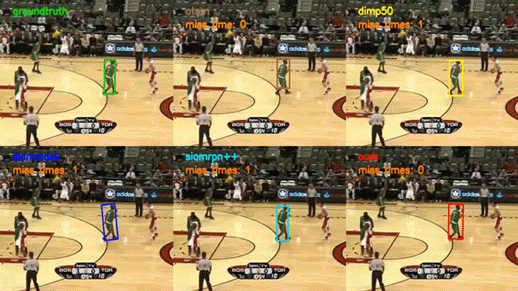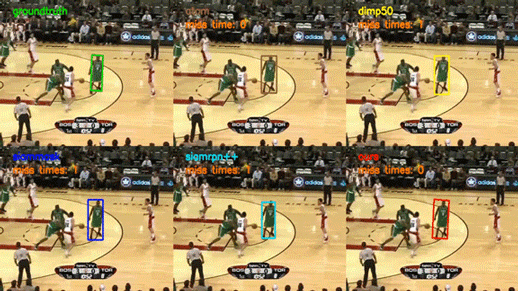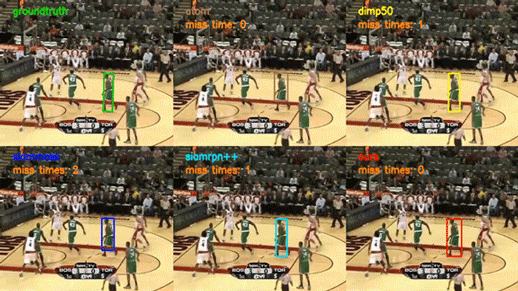
视觉目标跟踪的目标是对一段视频里面的目标物体进行准确的跟踪。该任务在自动驾驶、人机交互、机器感知等领域均有非常广泛的应用,但由于目标的变形、运动、遮挡、复杂背景等原因,建立一个快速和鲁棒的跟踪器具有很大的挑战性。
近些年由于深度学习技术的快速发展,目标跟踪任务也得益于深度学习技术所提供的强大的特征表达能力。如 SiamFC、SiamRPN、DaSiamRPN、SiamRPN++、SiamMask 等基于孪生网络结构的跟踪器,均获得了很好的跟踪效果。
但是,因为孪生网络跟踪器完全是在线下通过大量从视频中提取出来的成对的帧进行训练,因此通常在跟踪过程中,模板特征并不会进行更新。这导致了它们对于外观具有很大变化、变形、遮挡的目标的跟踪过程中,很容易导致跟踪漂移。一方面它们在目标的卷积特征计算过程中,模板和搜索区域的特征提取通常是相互独立并没有进行交互,另一方面也会丢弃掉很大部分的背景信息,而这些背景信息对于区分目标和邻居的干扰物十分重要。
受到计算机领域里注意力机制的成功应用的启发,我们提出了一个可变形孪生注意力网络来解决目标跟踪问题。我们将会描述一种新的可变形注意力机制,该机制可提高网络对于目标特征的表达能力、使得特征对于目标外观的变化拥有更强的鲁棒性,对目标和邻近干扰物或复杂背景有更好的区分能力。
本文的主要贡献总结如下:
我们设计了一种新的孪生注意力机制,该注意力机制计算了可变形的自注意力特征和互注意力特征。自注意力特征在空间域上学习到丰富的图像上下文信息,在通道域上选择性地增强通道特征之间的相互依赖;互注意力特征聚合与沟通模板和搜索区域之间丰富的信息,提高了特征的区分能力。
我们设计了一个区域修正模块,在经注意力的特征的基础上,来对预测结果进行进一步的修正,同时生成跟踪目标的包围框和掩膜。该模块可使跟踪的结果更加准确。
为了检验 SiamAttn 的性能,我们在六个标准的跟踪性能测试集上测试了 SiamAttn,实验表明 SiamAttn 明显超越了现有最新算法,达到了目前的最优水平,同时在使用 ResNet-50 作为骨架网络的基础上,保持了实时的速度。
在视频的第一帧给出需要跟踪的目标的位置,我们的目标是在视频序列接下来的每一帧中都给出该目标准确的位置。通常基于孪生网络结构的跟踪器的做法是将第一帧给定的目标模板和接下来的待搜索区域同时输入到孪生网络当中提取出特征,然后对这两个特征进行互相关操作,得到的响应图就代表模板在搜索区域不同位置的得到响应的响应值大小,然后对该响应图再进行进一步的回归得到最终目标的位置。
如图 2 所示,我们提出的 SiamAttn 包含四个部分:输入、可变形孪生注意力模块、孪生 RPN 模块还有区域修正模块。
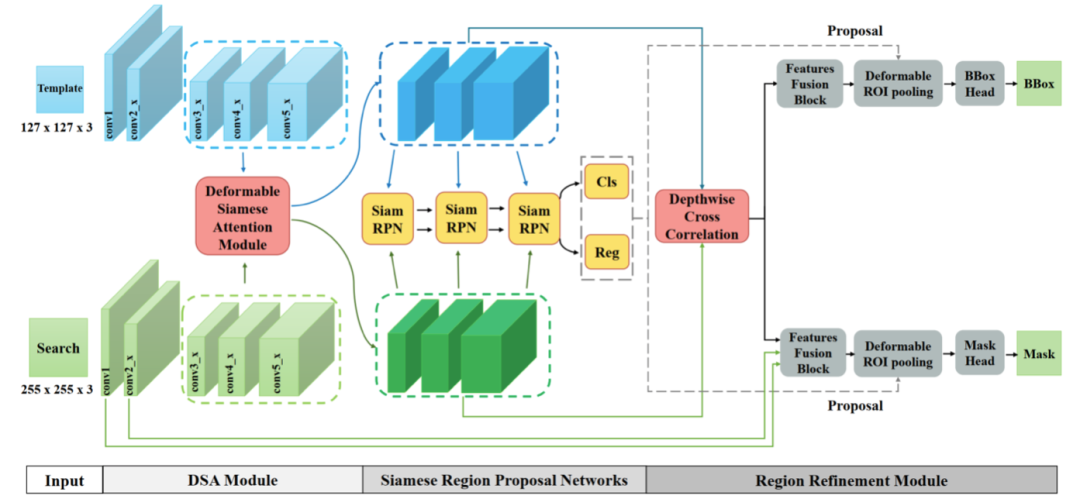
图 2 SiamAttn 的总体结构图,它包含四个部分:输入、可变形孪生注意力模块、孪生 RPN 模块还有区域修正模块。我们使用 ResNet-50 作为骨干网络来提取输入图片的特征,并将 S3、S4、S5 的特征输入到 DSA 模块进行注意力增强;然后将经过增强的特征输入到 Siamese RPN,产生一个最佳的 proposal;最后由区域修正模块对该 proposal 进行最后的修正。
1、可变形孪生注意力模块
可变形孪生注意力(Deformable Siamese Attention, DSA)模块将模板和搜索区域的特征作为输入,然后对其应用孪生注意力机制,最终输出经过增强的特征。如图 3 所示,DSA 模块又包含两个子模块:自注意力子模块和互注意力子模块。
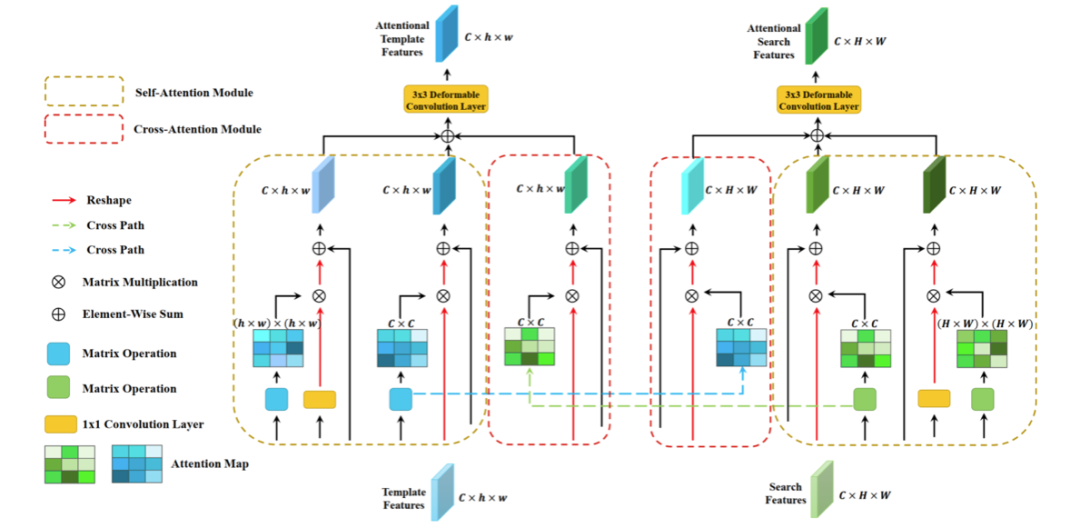
图 3 可变形孪生注意力模块总体结构图
自注意力子模块兼顾通道和空间位置两个方面。不同于分类任务和检测任务,它们的目标类别都是预先设定的,而目标跟踪则是类别无关的任务,事先并不知道需要跟踪目标的类别,而是在视频的第一帧给出,并在整个跟踪过程中固定。而在卷积神经网络中,每一个通道的响应通常反应了某种特定类别的响应,也就是说大部分通道的响应类别与跟踪目标不同,因此,同等地对待每一个通道的响应会限制网络特征的表达能力。另一方面,受感受野的限制,网络特征中的每一个空间位置都只能捕捉到附近的局部信息,因此,学习到全局上下文信息对于特征表达能力也非常重要。自注意力模块通过计算出通道的注意力特征图来自适应地对每一个通道的响应进行加权,将不相关通道的响应的影响降低;通过计算出空间位置的注意力特征图来捕捉空间每一个位置的信息,使得每一个位置的特征都能捕捉到图像全局的信息。
互注意力子模块则致力于改变孪生网络两个分支在计算特征的过程中缺乏沟通的现状。通常来说,模板分支和搜索分支的特征直到进行互相关操作的时候,才会进行交互,而在此之前,相互独立。然而,在提取特征的过程中,对每一个分支来说,另外一个分支的信息至关重要。尤其对于目标跟踪任务,很常见的一种情况就是多个类似的目标同时出现在相互的附近,甚至相互进行遮挡。如果孪生网络两个分支在计算特征的过程中就进行有效的信息交互,则有助于各自捕捉到更有用的信息。而互注意力子模块首先根据每个分支自己的信息计算出注意力特征图,然后将这个特征图传送到另外一个分支,接收到特征图的分支则根据这个特征图来增强自己提取到的特征,最终实现更有效的特征提取。
在每个分支的最后,我们还加入了可变形卷积以替代常规的卷积,使网络的感受野更加灵活。目标跟踪过程中通常伴随着大量的变形、遮挡、角度变换等情况,常规卷积正方形的采样方式限制了网络感受野的灵活性,而可变形卷积的灵活性则十分适用于解决目标跟踪的问题。因此,在平衡计算效率和精度的情况后,我们在孪生网络每个分支的最后加入了 3*3 的可变形卷积层。
图 4 显示了经过 DSA 模块和不经过 DSA 模块的特征响应对比图,可以看出,使用了 DSA 模块的特征响应要更加准确,能对周围干扰物和背景进行更有效的区分。

图 4 目标响应的可视化结果示例。第一列为搜索区域图,第二列为不经过 DSA 模块网络对目标得到的响应图,第三列为经过 DSA 模块网络对目标得到的响应图。
2、区域修正模块
我们使用 Siamese RPN 来进行 proposal 的提取,然后对于 Siamese RPN 提取出来的最佳 proposal(得分最高),我们提出一个区域修正模块来对其进行进一步的修正,其中包括更准确的包围框的预测以及对应目标掩膜的预测。
我们首先根据 proposal 的位置,使用可变形 RoI Pooling 提取出对应区域的特征。而后使用两个轻量的卷积 head 来作进一步的预测:其中一个回归它的包围框,而另一个则对目标的掩膜进行预测。
在 ATOM 和 SiamMask 等跟踪器中,它们对包围框或者掩膜的预测都是进行密集地预测,而在 SiamAttn 中,则是使用单独的卷积 head 进行预测,因此它的计算效率非常高而且能得到更准确的预测结果。
3、损失函数
SiamAttn 的整个训练过程是端到端的,而训练损失函数为各个模块的损失函数的加权和。损失函数计算公式如下:
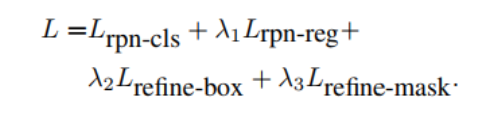
其中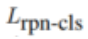
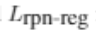
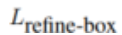

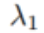
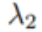
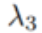
1、公共数据集评估结果
我们在 OTB2015、UAV123、VOT2016、VOT2018、LaSOT 和 TrackingNet 这六个标准的跟踪性能测试集上验证了 SiamAttn 的有效性。从表中可以看出我们的方法达到了非常好的效果,尤其是对于 VOT 这种需要带旋转的包围框来更好地定位目标的数据集,SiamAttn 有更为明显的提升。
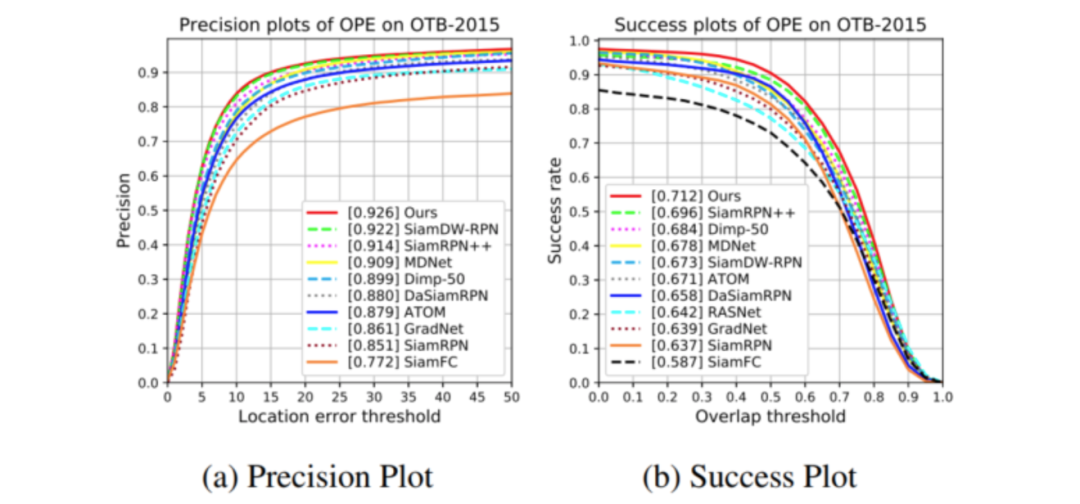
图 5 OTB-2015 实验结果图
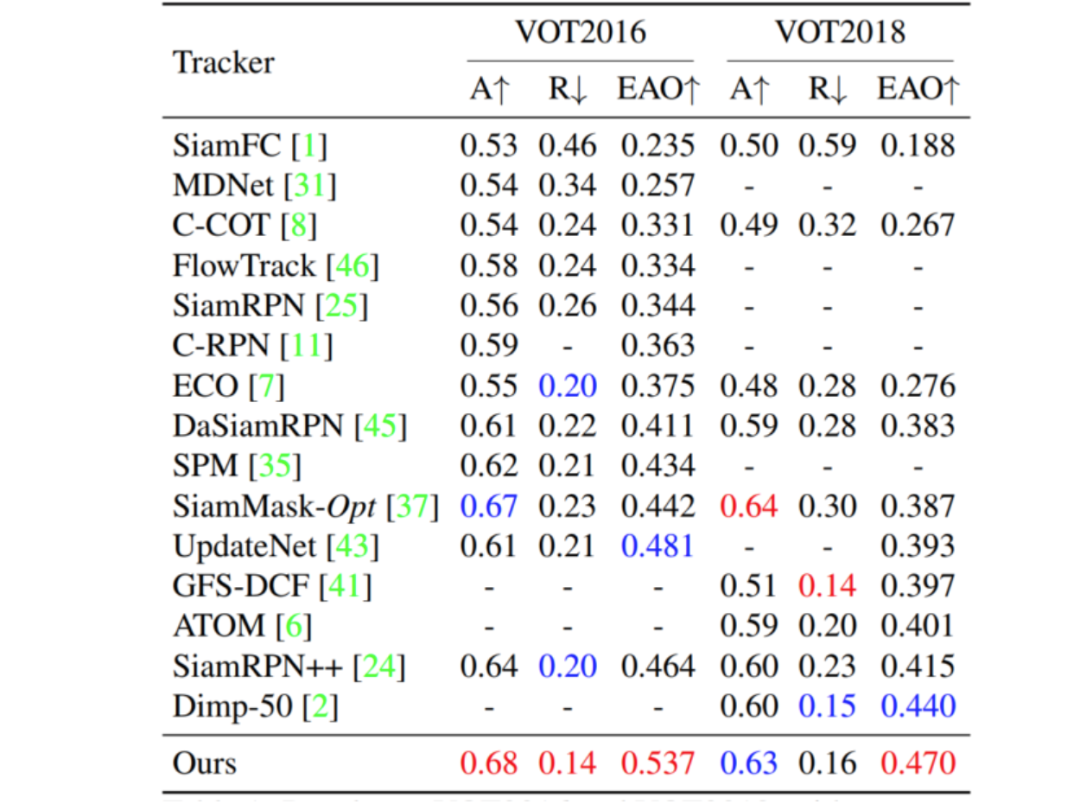
图 6 VOT 实验结果图

图 7 UAV123 实验结果图

图 8 LaSOT 实验结果图

图 9 TrackingNet 实验结果图
2、消融实验
在 Ablation study 中,我们也进一步验证了各个子模块对于模型整体性能的贡献。详细的分析见 paper 和 supplementary。
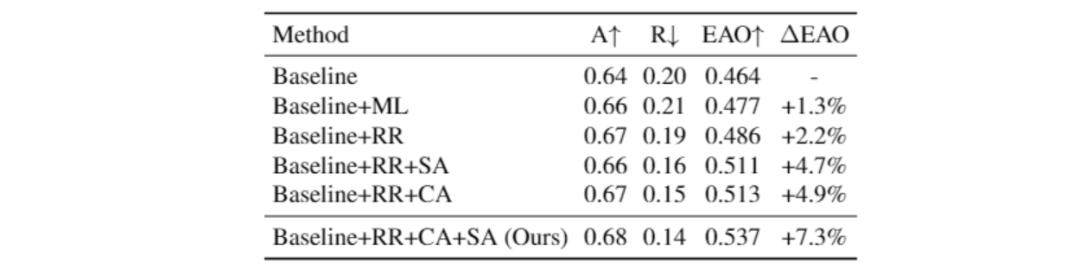
图 10 SiamAttn 各个子模块对于模型整体性能的贡献

图 11 可变形卷积和池化对模型性能的影响

图 12 不同训练集对模型性能的影响
我们提出一个解决目标跟踪任务的新型跟踪器:SiamAttn。在该跟踪器中引入了效果显著的孪生注意力机制,其中包括自注意力和互注意力,以帮助模型获得更好的目标区分能力。与以往的跟踪器不同的是,该注意力机制提供了一种自适应地隐式更新模板特征的方法,并且引入了可变形卷积层和可变形池化层增大与灵活化了每个点的感受野,以确保提取到目标更有效的特征。并且设计了一个轻量的区域修正模块来进一步提升目标跟踪的准确性。在保持实时的情况下,多个数据集上的大量实验都证明了我们的方法的有效性。

上方图片为 SiamAttn 在 VOT2018 数据集上的测试结果。它表明 SiamAttn 有能力跟踪与分割大多数包含不同尺寸、不同动作、发生形变以及拥有复杂背景的目标。
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京/深圳
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:cenfeng@leiphone.com




