视觉物体跟踪新进展:让跟踪器读懂目标语义信息
编者按:视觉物体跟踪(Visual Object Tracking)是视频分析任务中的一个基础问题。从2016年起,深度学习和卷积神经网络开始被大量运用在物体跟踪算法中。其中,全卷积孪生网络成为了近两年最炙手可热的框架,但它训练出的网络主要关注外观特征而无视语义信息,会让跟踪器犯一些匪夷所思的错误。由此,微软亚洲研究院网络多媒体组提出使用双重孪生网络进行视觉物体跟踪的方案SA-Siam,不仅能够关注语义和外观信息,且加入注意力模块使网络关注特定的语义信息,在VOT任务的权威数据集上效果良好地实现了“能跟住”、“不跟错”和“实时跟”的目标。
视觉追踪是人类最基本的视觉能力之一。婴儿在出生两个月左右就已具备了“固视”的能力,即固定的注视一个物体,视线随物体移动。对计算机视觉而言,视觉物体跟踪(Visual Object Tracking,简称VOT)同样是一个基础而经典的问题。通过对物体的检测、识别和跟踪,可以进一步对目标物体的行为进行分析和理解。可以说,VOT是视频分析的基础模块,也是人机交互、智能监控等应用的技术基石。
在计算机视觉研究中,VOT一般指单目标跟踪,即给定一个目标在第一帧中的位置,要求在后续每帧中持续给出该目标的位置(通常用一个边界框标出目标位置)。
VOT的关键是“能跟住”、“不跟错”和“实时跟”。首先,物体在每帧中的位置都是变化的,这种变化可能是由物体本身的形变带来的,也可能是拍摄角度、参数或光照变化引起的,甚至可能是由其它物体的遮挡造成的,因此,“能跟住”其实并不简单;其次,目标物体并不总是单独出现,其周围经常会有看起来相似的其它物体,甚至是看上去差不多的背景。如何保证“不跟错”也是VOT的一个重要挑战;最后,VOT处理的是视频,而视频通常是以24~30帧/秒的速度记录下来的,因此,VOT实时跟踪器至少要达到与视频同样的帧率,这样才具有较高的实用性。
上世纪90年代,由三位著名学者提出的Kanade-Lucas-Tomasi特征跟踪器(简称KLT算法),是当时研究VOT的标杆算法。KLT算法的基本思路是在目标物体内部或边界上找到适合跟踪的特征点,如对比强烈的角点或与周边纹理有显著差异的位置,然后通过跟踪这些特征点预测目标物体的位移、缩放以及旋转等参数,从而确定目标物体在新的视频帧中的位置。KLT算法非常符合我们的直觉,在物体仅出现简单的位移、旋转和形变时能够取得较好的效果,但它很难处理大部分较为复杂的情况。
本世纪初,相关滤波(Correlation Filter,简称CF)的方法也曾引领过一波VOT研究的热潮。CF方法能够处理物体的旋转、光照变化、尺度变化,甚至是部分遮挡。而且,空间域的卷积操作可以由傅里叶变换通过频域的乘法操作来完成,大大节约了计算时间。正当研究者们集中精力提高相关滤波方法的性能之际,深度学习方法异军突起,并以摧枯拉朽之势席卷了计算机视觉研究的各个子领域,VOT领域当然也受到“波及”。
从2016年起,很大一部分物体跟踪算法都利用到了深度学习和卷积神经网络。深度特征由于其表达的丰富性,可以大大提高跟踪性能。然而在传统相关滤波框架中结合深度特征会使得跟踪器的效率大大降低,原因是相关滤波框架要求滤波器随着跟踪的进行而不断更新,而深度特征的提取和更新很难做到实时。为了解决这一问题,Luca Bertinetto等人提出了一个在最近两年中最炙手可热的框架,名为全卷积孪生网络(Fully Convolutional Siamese Network,简称SiamFC)。SiamFC的框架图如下图所示。
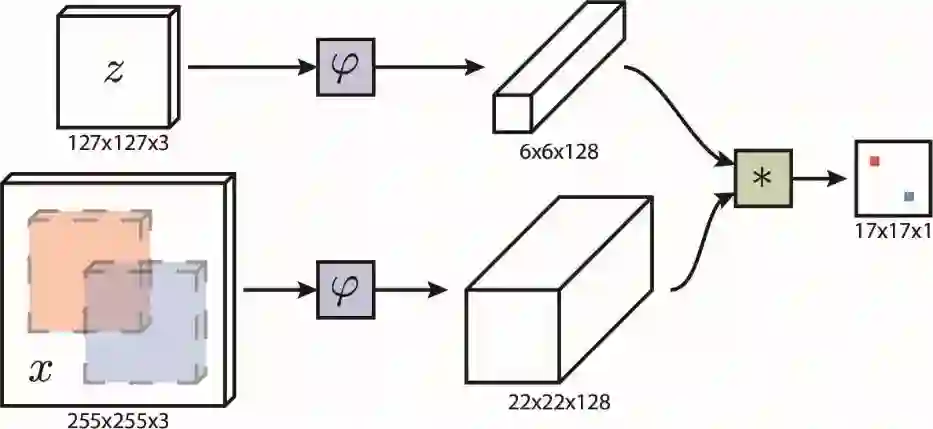
图中z是包含了目标物体的目标图像块,从第一帧视频中截取且无需更新。x是当前帧中的搜索区域。这两个图像块用相同的全卷积网络ψ提取特征,再用相关操作进行匹配,生成响应热力图。在热力图中寻找最大值点,其位置便给出了目标物体在搜索区域内的相应位置。
SiamFC方案一经提出就受到了广泛关注。它几乎是首个基于深度特征却又能保持实时性的跟踪方案,跟踪速度在GPU上达到了86fps(帧每秒),而且其性能超过了绝大多数实时跟踪器。在网络训练时,SiamFC采用了ImageNet VID的数据,配对同一个视频序列中间隔不远的两帧,在相似度匹配的任务下进行训练。在测试时,训练好的网络参数无需调整,而仰仗深度神经网络强大的表达能力,目标模板也无需更新,从而实现了高速、高效的物体跟踪。
但是,由于SiamFC方法中的网络训练是在相似度匹配的任务下进行的,训练数据使用的是一个视频中间隔不大的两帧,因此训练出的网络主要关注外观特征而无视语义信息,而语义信息的缺失会让跟踪器犯下常人看来无法理喻的错误。下图就给出了三个SiamFC方法的典型错误。

最左边的一列图片中用绿色边界框给出了需要跟踪的目标,后两列的图片展示了在不同的后续帧中的跟踪结果。其中紫色框标出的是SiamFC的结果。在第一行的例子中,目标物体是人的头部,在边界框的右上角是颜色较深的头发,剩余大部分区域是颜色较浅的面部区域。因此,在中间列所展示的图片中,SiamFC给出了背景中符合这种灰度模式的一片区域作为跟踪结果。类似的错误也发生在第二行、第三行所展示的示例中。事实上,前两个例子中的目标物体都具有很强的语义信息,即人的头部和人体。如果跟踪器能够从第一个边界框中提取出语义信息,并且用语义信息进行匹配,那么这两个序列中的背景干扰问题就迎刃而解了。
微软亚洲研究院网络多媒体组主管研究员罗翀和其团队创新性的提出了使用双重孪生网络进行视觉物体跟踪的方案,简称为SA-Siam,其中S代表的是语义(Semantic)分支,而A则代表外观(Appearance)分支。SA-Siam方案的框图如下。
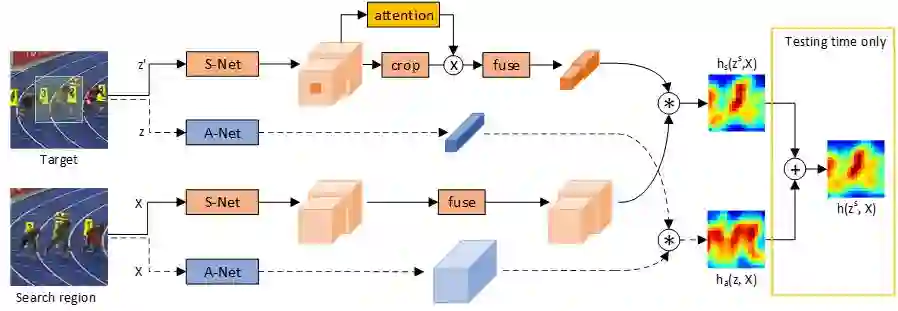
其中由虚线连接的蓝色方框属于外观分支,即原有的SiamFC网络,而实线连接的橘色方框属于语义分支。在语义分支中采用在ImageNet图像分类任务中训练的网络作为语义网络(S-Net),并且冻结该网络中的所有参数,通过训练语义分支中的融合(fuse)模块来实现迁移学习。
在语义分支中,并不是所有具有语义信息的物体都需要重点对待。因此,引入了一个注意力模块,它的目的是突出目标物体,同时弱化非目标物体。在SA-Siam方案中用两种方式实现了注意力模块,一种是非常直观的根据目标物体的形状(主要是边界框的高宽比)进行空间掩码;另一种是使用一个多层神经网络为每个特征通道计算出相应的权重。这两种注意力模块的实现方法都在测试数据集上取得了比较好的效果。在训练中,一个有意思的细节是,语义分支和外观分支需要独立训练,它们所产生的响应热力图仅仅在测试时才会相加合并。这样能够最大限度的维持两个分支的独立性和互补性。
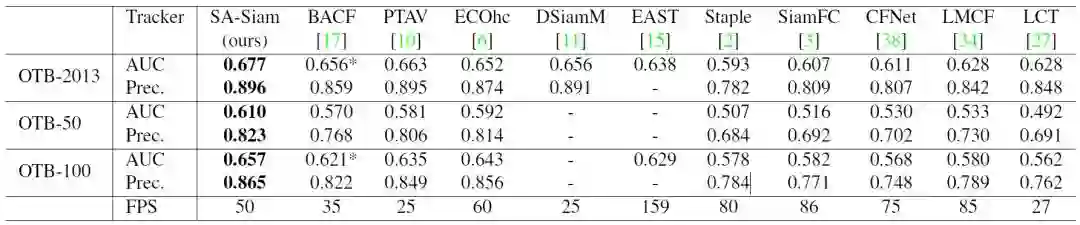
在VOT任务中有两个主要的基准数据集,即OTB(Object Tracking Benchmark)数据集和VOT (Visual Object Tracking)数据集。OTB于2013年由Yi Wu等人首次在CVPR会议上提出,因此首个OTB也被记作OTB-2013或OTB-CVPR2013,OTB-2013数据集包含51个跟踪目标。其后,Yi Wu等人继续扩充并提出了一个包含100个跟踪目标的大数据集,并于2015年发表在T-PAMI杂志上,这个数据集通常被记作OTB-100。与此同时,他们挑选了其中难度较高的50个跟踪目标作为OTB-50。下表展示了SA-Siam在不同OTB数据集上与其他实时跟踪器的性能比较。在SA-Siam提出之时,它的性能远远领先于其它实时跟踪器。
下图中展示了SA-Siam和其它实时跟踪器在几个典型视频序列上的表现,其中SA-Siam的跟踪结果由红色边界框给出。在所有展示的视频中,SA-Siam都取得了良好的跟踪效果,实现了“能跟住”、“不跟错”和“实时跟”。特别值得一提的是最后一行的两个视频,在Skiing序列中跟踪目标是一个从高台飞跃而下的滑雪运动员。由于跟踪目标小、形态变化大、移动速度快,在SA-Siam之前几乎所有的实时跟踪器都在这个序列上失败了。而SA-Siam由于加入了相对稳定的语义信息,无论滑雪者的外观、形态如何变化,跟踪起来都非常顺利。最后一个MotorRolling的序列和Skiing序列有些相似,但目标物体的尺度变化更大,其它跟踪器都不出意外的跟丢了,而SA-Siam却能稳定的追踪到目标。

从以上的实验数据和可视结果不难看出,SA-Siam由于引入语义信息而变得更加稳定,不再轻易受目标物体外观变化的影响。当然,由于沿用了SiamFC的跟踪框架,不对目标模板进行任何更新,因此SA-Siam在处理一些长视频或目标被遮挡的视频序列时还存在一些不足。除此之外,SiamFC的框架还存在着边界框精细定位的不足,当物体发生尺度变化或长宽比变化以及旋转时,无法精细定位出物体边界。我们正在就这些问题开展进一步的研究。
VOT权威挑战赛VOT2018(Visual Object Tracking Challenge 2018)的结果将会在ECCV会议期间(9月14日)公布。在去年的实时跟踪子任务中,排名首位的跟踪器也仅达到了0.212的EAO (Expected Average Overlap,数字越大代表效果越好),而今年预计将有多个实时跟踪器可以在EAO指标上超过0.3。在两个月前召开的CVPR会议和正在召开的ECCV会议上,有关VOT的论文均达到了14篇,这个研究方向的发展之快和火热程度可见一斑。有理由相信,在经过这一轮的高速发展之后,VOT将成为下一个在现实场景下可实际应用的技术。我们也将基于领先的研究成果推动该技术的应用进程。
论文下载链接:
https://arxiv.org/abs/1802.08817
作者简介

罗翀,微软亚洲研究院网络多媒体组主管研究员,中国科学技术大学兼职教授、博士生导师。主要研究方向为视频分析、多媒体通信、多媒体云计算等。在包括ACM Mobicom、IEEE Infocom、IEEE CVPR等顶尖学术会议以及多份IEEE期刊上发表论文50余篇,拥有十余项国际发明专利。
你也许还想看:
● ECCV 2018 | 如何让RNN神经元拥有基础通用的注意力能力
● ECCV 2018 | 迈向完全可学习的物体检测器:可学习区域特征提取方法


9月15日,由北京大学新媒体研究院社会化媒体研究中心主办,比尔及梅琳达·盖茨基金会支持的“乐天行动派2018年度公益盛典”将在中国电影导演中心举行。
盛典将集结企业领袖、社会创新家、热心公益事业的明星及艺术家、NGO代表,以及相关领域的专家学者齐聚一堂,共同递乐观向上的精神,分享他们践行“乐天行动,创变未来”的独特打开方式。
扫描下方“二维码”,马上加入“乐天行动派”!

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。



