Google提出FollowNet:使用深度强化学习训练机器人遵循指令进行导航
原文来源:arXiv
作者:Pararth Shah、Marek Fiser、Aleksandra Faust、J. Chase Kew、Dilek Hakkani-Tur
「雷克世界」编译:嗯~是阿童木呀、KABUDA、EVA
人们经常通过观察周围的环境和遵循指令在未知的环境中进行导航。而这些指导指令主要由地标和方向指示性指令以及其他常用词语组成。最近,Google将类似于人类的指令遵循应用到机器人在二维工作空间中的导航任务,为智能体提供指令,并对其进行训练以遵循指令。为了进行有效导航,Google提出了FollowNet,它是一个用于学习多模态导航策略的端到端的可微神经架构。可提高智能体在环境中的导航能力。
理解和遵循由人类提供的指令可以使机器人在未知的情况下进行有效的导航。我们提供了FollowNet,它是一个用于学习多模态导航策略的端到端可微的神经架构。FollowNet将自然语言指令以及视觉的深度输入映射到运动原语(locomotion primitive)。FollowNet在执行导航任务时使用注意力机制来处理指令,该机制以其视觉的深度输入为条件,以集中于命令的相关部分。
深度强化学习(deep reinforcement learning,DRL)的稀疏奖励要同时学习状态表征、注意力函数和控制策略。我们在一个复杂的自然语言指令的数据集上评估我们的智能体,以通过一个丰富、真实的模拟家庭数据集来指导智能体。我们指出,FollowNet智能体学习执行以前不可见的用类似词汇描述的指令,并成功地沿着在训练期间未遇到的路径进行导航。在没有注意力机制的情况下,智能体与基线模型相比显示出30%的改进,在新指令下的成功率为52%。
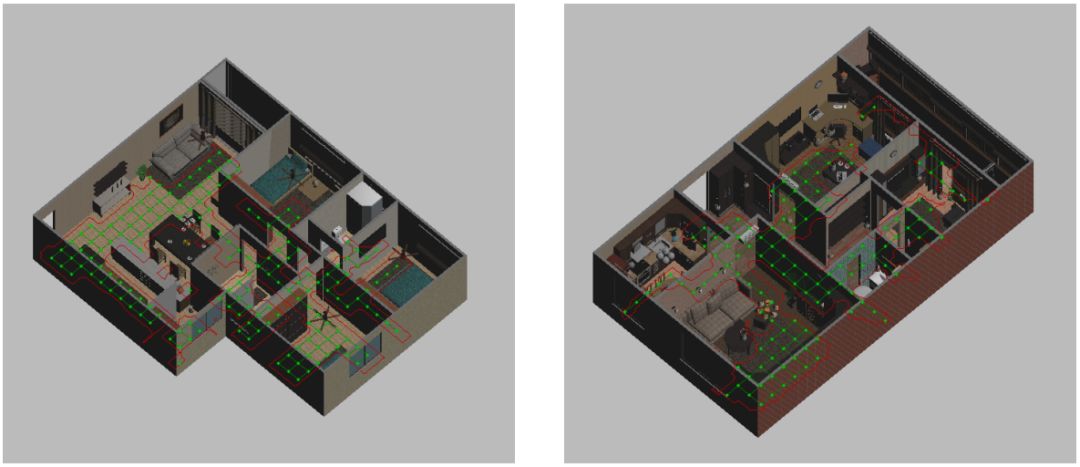
图1:用于从自然语言指令学习导航的房屋的三维渲染。
人们经常通过观察周围的环境和遵循指令在未知的环境中导航。这些指令主要由地标和方向性指令以及其他常用词语组成。例如,人们可以在一个他们以前没有去过的家中找到厨房,通过遵循以下的指令:“在餐桌处右转,然后再左转(Turn right at the dining table, then take the second left)”。
这个过程需要视觉上的观察,例如在视野范围内的餐桌或关于典型门厅的知识,并执行在这个方向上的动作:向左转。这里的复杂性有多个维度:有限的视野,像“second”这样的修饰词,像“take”和“turn”这样的同义词,理解“take left left”指的是门,等等。
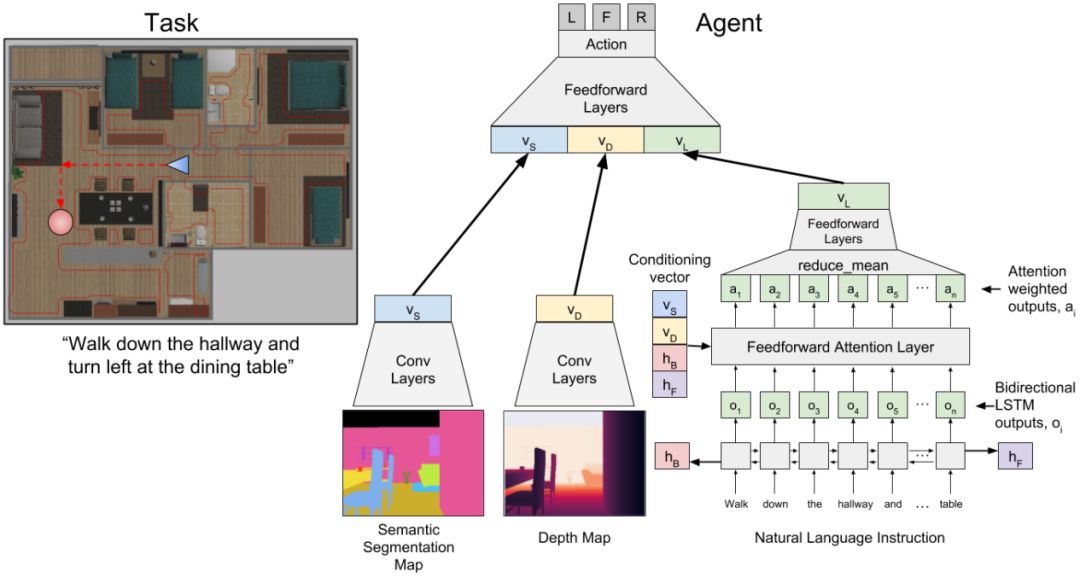
图2:将视觉和语言输入映射到导航动作的神经模型。左图:一个示例任务,其中机器人从蓝色三角形指定的位置和方向开始,并且必须到达由红色圆圈指定的目标位置。机器人会收到一条自然语言指令,以便沿着图像下方列出的标有红色的路径行进。右图:FollowNet架构。
在本文中,我们将类似于人类的指令遵循应用到机器人在二维工作空间中的导航(图1)。我们给机器人提供了与上述机器人类似的示例指令,并训练了一个深度强化学习(DRL)智能体以遵循指令。当从不同的位置出发时,该智能体会被测试它遵循新指令的程度。我们通过一个新的深度神经网络架构FollowNet(图2)完成了这项工作,该架构是使用Deep Q-Network (DQN)来进行训练的。
观察空间由自然语言指令和从机器人的有利位置(vantage point)得到的视觉深度观察组成(图4b)。策略的输出是下一个要执行的运动原语(motion primitive)。机器人沿着无障碍的网格(obstacle-free grid)移动,但是指令要求机器人移动超过可变数量的节点以到达目的地。我们使用的指令(表I)包含隐式编码的房间(implicitly encoded room)、地标和运动原语。
在上面的例子中,“厨房”是目标位置的房间。“餐桌”是一个地标示例,在这个点上,智能体可能会改变方向。在没有智能体的知识的情况下,房间和地标都被映射到成群的网格点。我们使用的是稀疏奖励,只有当智能体到达一个路标的时候才会给它一个奖励。

表1:在训练过程中所使用的指令样本。
可以这样说,FollowNet架构的新颖之处在于一种语言指令注意机制(language instruction attention mechanism),它是以智能体的感官观察为基础条件的。这使得智能体能够做两件事。首先,它追踪指令命令,并在探索环境时关注不同的部分。其次,它将运动原语(motion primitives)、感官观察和指令的各个部分与收到的奖励相关联,从而使智能体能够泛化到新的指令中。
我们评估智能体在新指令和新运动计划中的泛化程度。首先,我们评估一下,在智能体所熟悉的房屋中,它对先前不可见的两步指示的遵循执行程度。结果表明,该智能体能够完全遵循52%的指令,局部性遵循61%的指令,比基线增加30%。其次,相同的指令对一组不同的起始位置来说是有效的。
例如,“离开房间”这一指令对于房间内的任何起始位置来说都是有效的,但机器人为完成任务而需要执行的运动计划可能会非常不同。为了了解运动计划泛化到新的起始位置的程度,我们评估智能体对一个它已经在其经过训练的指令(最多五步的方向)的遵循执行情况,但是现在是从新的起始位置开始的。智能体能够局部性地完成70%的指令,完全性地完成54%的指令。从这个角度来看,多步骤的指令对于人们来说也是具有一定的挑战性的。
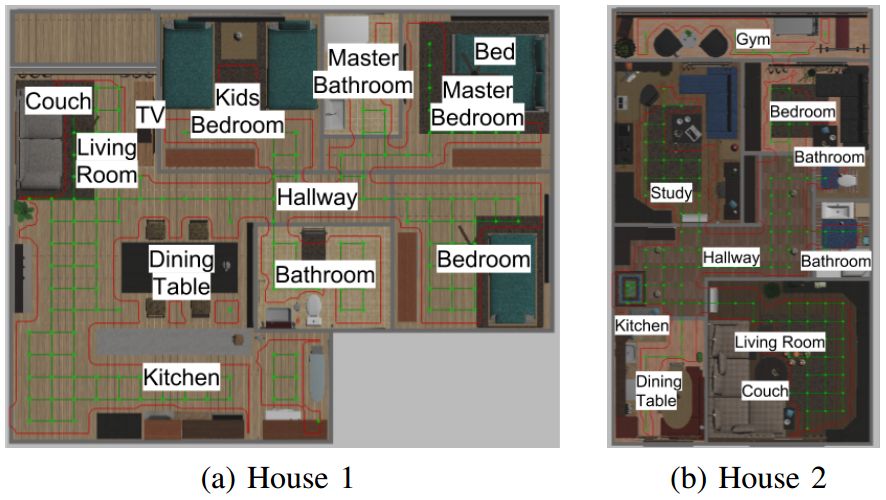
图3:环境中的地标和网格。
端到端的导航方法(End-to-end navigation methods)使用深度强化学习机器人的感官观察和相对目标位置。在这项研究中,我们提供的是自然语言指令而不是明确的目标,因此智能体必须学会对指令加以解释从而完成目标。将强化学习应用于机器人的一个挑战是状态空间表征。大的状态空间减慢了学习速度,因此经常使用不同的近似技术。这些例子包括概率路线图(PRM)和简单的空间离散化。在这里,我们对二维工作空间进行离散化,并允许智能体通过网格从节点移动到节点。本质上,我们假设机器人可以通过执行与动作相对应的运动原语来避开障碍物并在两个网格点之间安全地进行移动。
深度学习在学习自然语言和视觉,甚至在结合视觉和语言学习方面取得了巨大成功。要想应用于机器人运动规划和导航,语言学习通常需要一定程度的解析,其中包括正式的表述、语义分析、概率图模型、编码和对齐或基础任务语言。然而,通过自然语言学习目标标记,主要是通过学习将自然语言指令解析为一种层次结构,用于机器人动作规划和执行以及主动学习过程。这里,与P. Anderson等人于2017年发表一篇文论相类似,我们的目标是隐式学习地标(目标)和运动原语的标签,以及它们对视觉观察的解释。与之不同的是,我们在FollowNet上使用DQN来学习导航策略。其他研究使用课程(curriculum)来完成一个环境中的多项任务。

图4:FollowNet智能体的语义分割图观察。颜色对应于物体类型(智能体不知道),并且在房屋和有利位置之间保持一致。沙发为绿色(a和c),餐桌为黄色(b和c)。
另一项结合3D导航、视觉和自然语言的研究工作是学习回答问题。这些问题源于一组指定的问题,其中,某些关键词被替换。在我们的研究工作中,提供给智能体的语言指令是由四名人员独立创建的,并且在未经任何处理的情况下就提交至智能体。有几种方法从未过滤的语言和视觉输入中学习。在这些方法中,视觉输入是整个规划环境的图像。相反,FollowNet仅接收部分环境观测。
本文介绍了FollowNet体系结构,该体系结构使用注意力机制来处理基于多模式感官观察的自然语言指令,以作为DQN中的动作值函数逼近器。经过训练的模型只使用视觉和深度信息来学习自然语言指令。结果表明,我们可以同时学习方向性指令的泛化和标志识别。智能体在大多数时间(在幼儿阶段)成功地遵循了新的两步指令(novel two-step directions),比基线水平提高了30%。在今后的研究工作中,我们的目标是在一个更大的数据集上训练智能体,跨多个领域开展更为深入的分析和经验评估工作,并探索跨不同环境的泛化能力。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”




