不用地图如何导航?DeepMind提出新型双路径强化学习「智能体」架构
来源:雷克世界
原文链接:
https://deepmind.com/blog/learning-to-navigate-cities-without-a-map/
论文:
https://arxiv.org/pdf/1804.00168.pdf
作者:Piotr、Matthew、Mateusz、Karl、Keith、Denis、Karen、Koray、Andrew 、Raia
一直以来,导航都是一项重要的认知任务,它使人类和动物在一个复杂的世界里,在没有地图的情况下,能够穿越遥远的距离。可以这样说,能够在非结构化环境中导航是智能生物的基本能力,因此这对于人工智能的研究和开发具有根本性的作用。
最近,DeepMind提出了一种全新的、双路径智能体结构,该结构采用端到端的强化学习进行训练,可处理城市级规模的真实视觉导航任务。
在你童年生活中,你是如何学会对你所在的社区进行导航的?你是如何导航去你的朋友家、去学校或者去杂货店的?可能没有地图,只要记住街道的视觉外观,就可以沿着路转弯。
当你逐渐探索了你所在的社区之时,你变得更加自信了,掌握了自己的去向,并学习了新的、越来越复杂的路径。你可能短暂地迷失过方向,但又因为地标的出现,或者甚至可能是通过看太阳找到一个即时指南针,从而再次找到了你的路线。
在《学习在不使用地图的情况下在城市中进行导航》这篇论文中,我们呈现了一种交互的导航环境,它使用了来自谷歌街景 (Google Street View)的第一人称视角照片,并将该环境进行游戏化以训练人工智能。
根据街景图片的标准,人脸和车辆牌照都被模糊了且无法辨认。我们建立了一个基于神经网络的人工智能体,它可以利用视觉信息(来自街景图像的像素)来学习如何在多个城市中进行导航。
请注意,这项研究是关于广义的导航的,而不是驾驶;我们没有使用交通信息,也没有试图对车辆控制进行建模。

我们的智能体在不访问该环境地图的情况下,在外观上多样化的环境中进行导航
当智能体到达目标目的地(例如,特定的一对纬度和经度坐标)时,它就会得到奖励。它就像一个快递员,有着无止境的交付任务,但它没有地图。
随着时间的推移,人工智能体学会以这种方式跨越整个城市。我们还证明了,我们的智能体可以在多个城市中学习这项任务,然后鲁棒性地适应一个新的城市。

在巴黎进行训练的智能体的定格拍摄。
以上这些图像与城市的地图叠加在一起,显示出目标位置(红色)以及智能体位置和视野(绿色)。注意,智能体并没有看到地图,只有目标位置的经纬度坐标。
学习在不需要构建地图的情况下进行导航
我们背离了那种依赖于显式测绘和探索的传统方法(就像试图将自己定位并同时绘制地图的那种制图师)。与此相反,我们的方法是学习人类过去常常使用的那种方法进行导航——没有地图、GPS定位或者其他的辅助手段,只使用视觉观察。
我们构建了一个神经网络智能体,它输入从环境中观察到的图像,并预测在该环境中它应该采取的下一步行动。
我们使用深度强化学习来对它进行端到端的训练,类似于最近的一些关于学习如何在复杂的3D迷宫中进行导航的研究,以及在玩游戏中使用引入了无监督辅助任务的强化学习的研究。
与那些在小规模模拟迷宫环境中进行的研究不同,我们利用了城市规模的真实世界数据,包括复杂的十字路口、人行道、隧道,以及横跨伦敦、巴黎和纽约的各种拓扑结构。此外,我们使用的方法还支持特定城市的学习和优化,以及泛化的、可迁移的导航行为。
可以迁移到新城市的模块化神经网络架构
我们智能体中的神经网络由三部分组成:
1)一个能够处理图像并提取视觉特征的卷积网络;
2)一个特定于地区的循环神经网络,它隐式任务是负责记忆环境以及学习“这里”(智能体的当前位置)和“那里”(目标的位置)的表征;
3) 不因地区改变的循环网络,它生产出智能体行为的导航策略。
特定于地区的模块被设计为可互换的,正如其名称所示,这个模块对于智能体所导航的每个城市来说都是独一无二的,但视觉模块和策略模块是可以不因地区改变的。
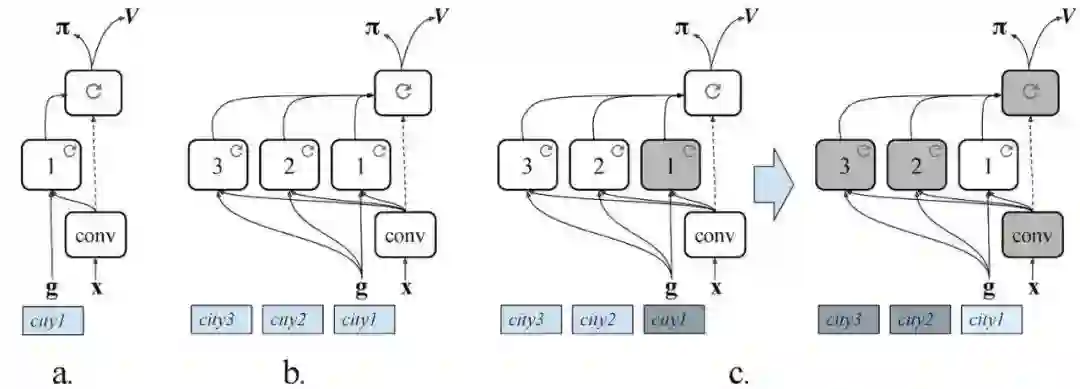
城市导航(CityNav)架构(a)、多城市导航(MultiCityNav)架构与每个城市的特定地区路径(b)作比较,以及对将智能体调整到新城市时的训练和迁移过程(c)作出说明。
就像在谷歌街景界面中一样,智能体可以在适当的位置进行旋转,或者在可能的情况下前进到下一个全景图。
与谷歌地图和街景环境不同的是,该智能体没有看到小箭头、局部地图或全局地图,也没有看到著名的小黄人(Pegman):它需要学习区分开放的道路和人行道。在现实世界中,目标目的地可能在几公里之外,并需要智能体跨过数百幅全景图才能到达目的地。
我们证明了,我们所提出的方法可以提供一种将知识迁移到新城市的机制。和人类一样,当我们的智能体访问一个新城市时,我们希望它必须学习一套新的地标,但不需要重新学习它的视觉表征或它的行为(例如,沿着街道向前走,或者在十字路口转弯)。
因此,我们使用了多城市(MultiCity)架构,首先在许多城市进行了训练,然后我们冻结了策略网络和视觉的卷积网络,并且在一个新城市中只有一条特定于地区的路径。
这种方法使智能体能够获得新的知识,而不会忘记它已经学过的知识,这与渐进式神经网络架构(progressive neural networks architecture.)类似。
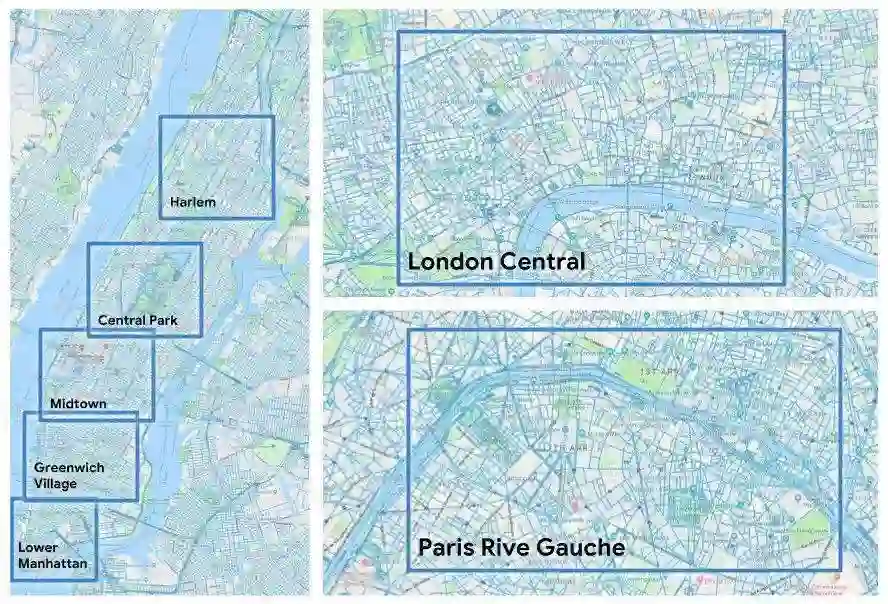
在该研究中所使用的曼哈顿的五个区域
研究导航是研究和发展人工智能的基础,尝试在人工智能体中复制导航也能帮助科学家了解其生物学基础。
论文简述

可以这样说,能够在非结构化环境中导航是智能生物的基本能力,因此这对于人工智能的研究和开发具有根本性的作用。
远程导航是一项复杂的认知任务,它依赖于开发一个空间的内部表征,以可识别的地标和具有鲁棒性的视觉处理为基础,可同时支持连续的自我定位(“我在这里”)和目标表示(“我将去那里”)。
基于最近进行的将深度强化学习应用于迷宫导航问题的研究,我们提出了一种可应用于城市规模的端到端深度强化学习方法。认识到成功的导航依赖于通用策略与特定于地区的知识的集成,我们提出了一种双路径体系架构,可以将特定地区的特征封装起来,同时仍然能够迁移到多个城市。
我们展示了一个交互式导航环境,它使用Google StreetView作为其照片内容和全球范围性的覆盖范围,并且证明我们的学习方法使得智能体能够学习在多个城市进行导航,并且能够穿过可能在数公里之外的目标目的地。
点击链接可以观看视频,里面概述了我们的研究,以及在不同城市环境和迁移任务中经过训练的智能体,链接地址:https://goo.gl/ESUfho。
一直以来,关于导航这一主题吸引了各种研究学科和技术领域科学家们的关注,从希望破解网格代码和位置细胞(place cells)的神经科学家角度来看,它一度成为研究的主题;同时对于希望构建可以到达特定目的地的移动机器人研究来说,它也是机器人研究的一个基本方面。
大多数算法都涉及在探索阶段构建显式映射,然后通过该表征进行规划和行动。在这项研究中,我们试图通过提出一种新方法并展示其在大规模实际环境中的性能,从而挑战端到端深度强化学习的导航极限。
正如人类可以不依赖地图、GPS定位或其他辅助工具而学习在城市中进行导航一样,我们的目标是证明神经网络智能体可以仅通过使用视觉观察便可横穿整个城市。
为了实现这一目标,我们设计了一个交互式环境,使用Google StreetView中的图像和基本连接信息,并提出了一种可在环境中导航的双路径智能体体系结构(见下图)。
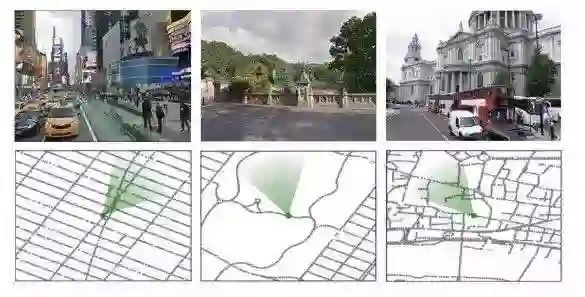
我们的环境根据StreetView的实际场所构建的。
上图显示了纽约市(时代广场、中央公园)和伦敦(圣保罗大教堂)的不同景观和相应的局部地图。绿色圆锥表示智能体的位置和方向。
通过使用可以从任务奖励中进行学习的深度强化学习方法(例如,导航到目的地),在某些领域内,学习直接通过视觉输入进行导航已被证明是可能的。
最近的研究已经证明,强化学习智能体可以学习对家庭场景(Zhu等人于2017年、Wu等人于2018年提出)、迷宫(Mirowski等人于2016年提出)和3D游戏(例如Lample和Chaplot于2017年提出)进行导航。
尽管取得了成功,但众所周知,深度强化学习方法数据低效且对环境干扰异常敏感,并且在游戏和模拟环境中的成功要远远高于其在实际环境中的应用。因此,它们不可以用于基于真实图像的大规模视觉导航,从而它也是我们此次研究的主题。
我们的贡献
本文的主要贡献是提出了一种全新的、双路径智能体结构,该结构采用端到端的强化学习进行训练,可处理城市级规模的真实视觉导航任务。
我们提出的智能体展示了目标依赖性学习,这意味着策略和价值函数必须学会适应一系列作为输入而给定的目标。
此外,该方法具有一种循环神经结构,即支持特定语言环境的学习,也支持通用的、可迁移的导航行为。平衡这两项能力是通过将循环神经路径从智能体的通用导航策略中分离出来实现的。
该路径解决了两点需求。首先,它接收并解释了环境给出的当前目标。其次,它封装并记忆了单个城市地区的特征和结构。
因此,我们不使用地图或外部存储器,而是提出了具有两条循环路径的体系架构,这可以有效解决单个城市中具有挑战性的导航任务,并仅通过训练新的特定语言环境路径即可迁移到新的城市或地区。
我们在一个新的强化学习交互环境中演示了所提出的智能体架构,该环境将现实世界的图像作为智能体观测,具有全球规模性和多样性,以及聚于建立在Google StreetView之上的现实世界的基础内容。
在该环境中,我们研发了一项遍历任务,要求智能体在伦敦、巴黎和纽约市内完成从一点到另一点的导航。我们任务的现实世界类比是,在一个给定的城市中,信使从一点A出发(该点是任意选定的),到指定的地点B,这一过程中没有给出该区域的地图,也没有给出从A到B的路线,更没有给出各点的具体方位。
导航是一项重要的认知任务,它使人类和动物能够在没有地图的情况下穿越复杂的世界。我们提出了一种解决城市级现实环境中任务的深度强化学习导航方法,引入并分析了一项新的信使任务,同时,我们还提出了一个多城市神经网络智能体架构,演示了该如何将其迁移到新的新环境。




