MVX-Net | 多模型三位像素网络用于3D目标检测
上周应该是很多考生难忘的日子,那就是一年一度的考研日,相信很多同学准备了一年都会有好的收获,去理想的大学读研,更希望你们可以加入“计算机视觉战队”,和我们一起来学习人工智能的CV领域,共同进步!


导读
2019/12/23
最近许多关于3D目标检测的工作都集中在设计能够消耗点云数据的神经网络体系结构上。虽然这些方法表现出优异的性能,但它们通常基于单一的模式,无法利用其他模式的信息,如相机。

虽然有几种方法融合了来自不同模式的数据,但这些方法要么使用复杂的流程按顺序处理模式,要么进行后期融合,无法在早期阶段了解不同模式之间的相互作用。
今天我们要说的这个技术,就是提出了Point Fusion和Voxel Fusion:两种简单而有效的早期融合方法,通过利用最近引入的VoxelNet体系结构,将RGB和点云模式结合起来。
对KITTI数据集的评估表明,与只使用点云数据的方法相比,性能有了显著提高。此外,所提出的方法提供了与最先进的多模态算法相竞争的结果,通过使用一个简单的单级网络,在KITTI基准上的六个birds eye view和3D检测类别中获得了前2名。

相关工作
2019/12/23

最近对3D分类的研究集中在使用端到端可训练的神经网络,这种网络可以消耗点云数据,而不需要将它们转换成中间表示,比如depth或bev格式。Qi等人[1]设计了一个直接以点云作为输入并输出类标签的神经网络体系结构。
[1]C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning
on point sets for 3D classification and segmentation. Proc. Computer
Vision and Pattern Recognition (CVPR), IEEE, 2017
通过这种设计,我们可以从原始数据中学习表示。但是,由于设计的局限性以及计算和内存开销的增加,其工作不能应用于检测和定位问题。最近,Zhou[2]通过提出VoxelNet克服了这一问题,VoxelNet涉及点云的体素化和使用Voxel特征编码(VFE)层的堆栈编码体素。
[2]Y. Zhou and O. Tuzel. VoxelNet: End-to-end learning for point cloud based 3D object detection. 2018.
通过这些步骤,Voxelnet可以使用3D区域候选网络进行检测。尽管该方法显示了较好性能,但它依赖于单一的模式,即点云数据。与点云相比,RGB图像提供了更密集的纹理信息,因此需要利用这两种模式来提高检测性能。
如上图所示,与LiDAR-Only VoxelNet相比,MVX-Net有效地融合了多模态信息,从而减少了false positivesnegatives和阴性。
新方法框架
2019/12/23
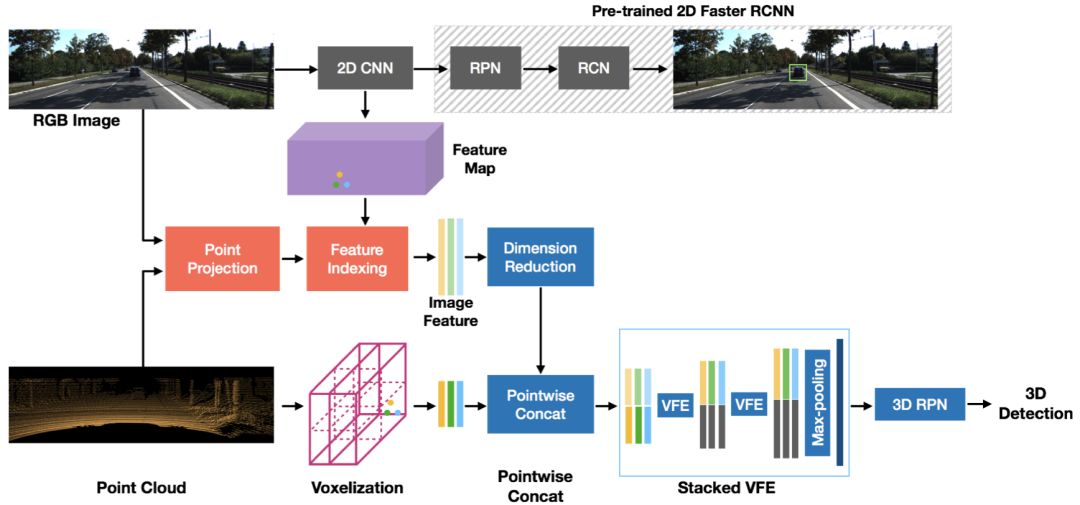
提出的融合技术,如上图所示,是基于VoxelNet体系结构的。为了融合RGB和点云数据中的信息,首先从2D检测网络的最后一个卷积层中提取特征。该网络首先在ImageNet上进行预训练,然后对2D目标检测任务进行微调。这些高级图像特征编码了语义信息,这些信息可以作为先验知识来帮助推断目标的存在。基于前面描述的融合类型(点融合或体素融合),将点或体素投影到图像上,并将相应的特征分别与点特征或体素特征连接起来。详细的2D检测网络,VoxelNet和提出的融合技术将在下面描述。
这种方法的优点是,由于图像特征是在非常早期的阶段,从这两个模态,通过VFE层,网络可以学习总结有用的信息。
此外,该方法利用了LiDAR点云,并将相应的图像特征提升到三维点的坐标上。
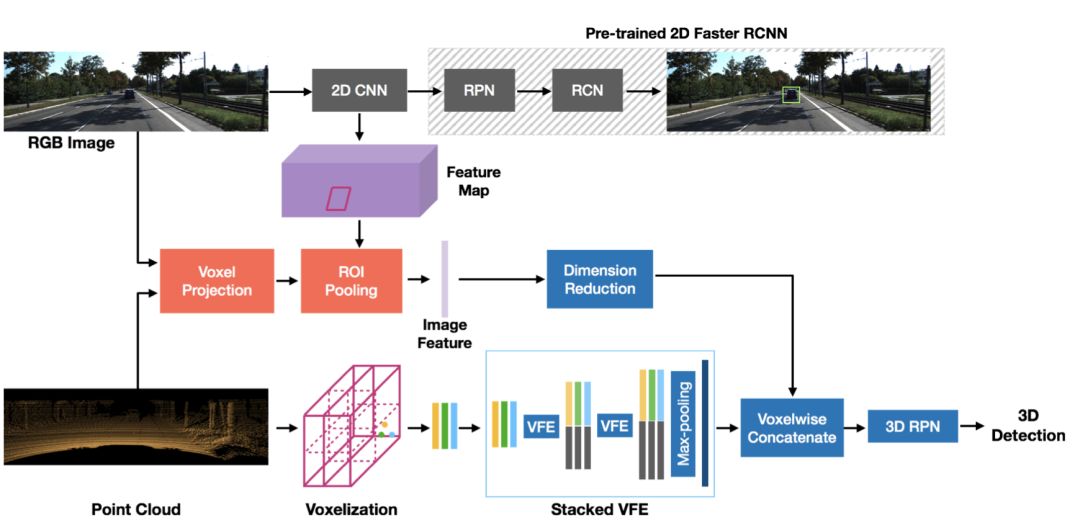
VoxelFusion
与早期结合专长的点融合相比,Voxel Fusionv采用了一种相对较晚的融合策略,其中RGB图像的特征被附加在体素级。VoxelNet的第一阶段涉及到将3D空间划分为一组等距体素。点基于它们所在的位置被分组到这些体素中,然后使用VFE层对每个体素进行编码。
在所提出的Voxel Fusion Method方法中,将每个非空体体素投影到图像平面上,产生一个二维感兴趣区域(ROI)。利用来自预先训练的检测器网络(VGG 16的Cov 5层)的特征映射,将ROI中的特征集合起来生成一个512维特征向量,该特征向量的维数首先降低到64,然后附加到每个体素叠加的VFE层生成的特征向量中。该过程在每个体素处对2D图像中的先验信息进行编码。
虽然Voxel Fusion是一种相对较晚的融合策略,其性能与Point Fusion相比略有下降,但它具有以下优点。
首先,它可以很容易地扩展到将图像信息聚合到空体素,其中LiDAR点由于低LiDAR分辨率或远距离目标而没有采样,从而降低了对高分辨率LiDAR点可用性的依赖。第二,与点融合相比,Voxel Fusion在内存消耗方面更有效。
训练细节
2D检测器:使用标准的Faster RCNN检测框架,这是一个由区域候选网络和区域分类网络组成的两级检测流程。基本网络是VGG 16体系结构,使用ROIAlign操作将最后一个卷积层的特征集合起来,然后将它们转发到第二阶段(RCNN)。我们在Cov5层上使用了四组大小分别为{4,8,16,32}和三个纵横比{0.5,1,2}的锚。当IOU大于0.7时,锚被标记为正;当IOU小于0.3时,锚被标记为负值。在训练期间,图像的最短边被重新标度到600像素。训练数据集采用标准技术,如翻转和添加随机噪声。在RCNN阶段,使用128批大小,25%的样本保留给foreground ROIs。该网络使用随机梯度下降训练,学习速率为0.0005,动量为0.9。
Multimodal VoxelNet:保留了VoxelNet的大部分设置,除了一些简化以提高效率。三维空间分为大小为Vd=0.4,VH=0.2,VW=0.2的体素。采用两套VFE层和三层卷积中间层。根据融合的类型,这些层的输入和输出维数是不同的。
为了减少内存占用,使用与最初工作相同的ResNet块数量的一半来减少RPN;采用与原工作相同的锚匹配策略。对于这两种融合技术,网络在前150个时期都采用随机梯度下降训练,学习速率为0.01,之后学习率衰减了10倍。
此外,由于我们同时使用图像和点云,所以原工作中使用的一些增强策略不适用于所提出的多模态框架,例如全局点云旋转。尽管使用经过修整的RPN进行训练,并且使用较少的数据增强,但与原来的LiDAR-Only VoxelNet相比,所提出的多模式框架仍然能够获得更高的检测精度。
实验
2019/12/23

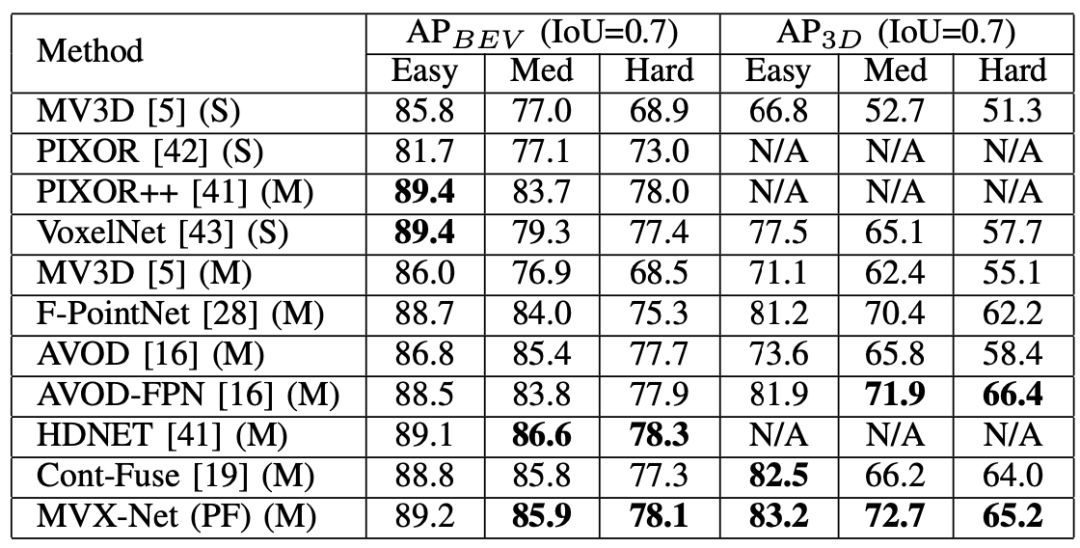
我们将提出的MVX-Net与先前发布的汽车检测任务方法进行比较。为了分析所提出的多模态方法的有效性,还训练了一个基准VoxelNet模型。与多模态方法类似,该模型使用了修剪后的架构,而不使用全局旋转增强。通过将结果与该基准进行比较,可以直接将增益归因于所提出的多模态融合技术。
Table I shows the mean average precision (mAP) scores for VoxelFu- sionand PointFusioncompared to the state-of-the-art meth- ods on the KITTI validation set using 3D and bird’s eye view (BEV) evaluation.
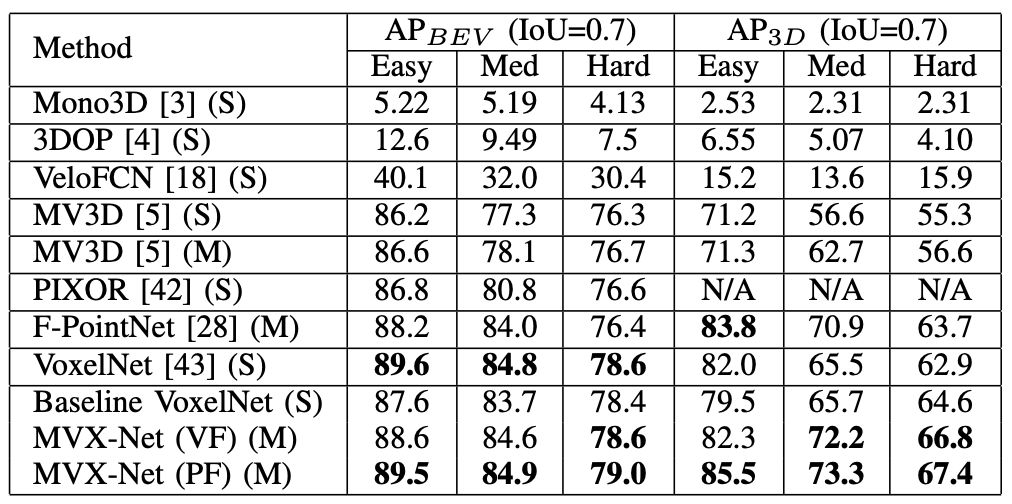
IOU=0.8的Kitti验证集结果比较

END
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!
论文下载:https://arxiv.xilesou.top/pdf/1904.01649.pdf




