【泡泡图灵智库】PointNet:用于三维分类与分割的点集深度学习(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation
作者:Charles R.Qi,Hao Su,Kaichun Mo and Leonidas J.Guibas
来源:CVPR 2017
编译:谭艾琳
审核:杨宇超
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——PointNet:用于三维分类与分割的点集深度学习,该文章发表于CVPR 2017。
点云是一种重要的几何数据结构。由于它不规则的形式,大部分研究人员都将这种数据转换成规则的三维体素网格或者图像集合。然而,这样做会使数据量不必要地变大并导致一些问题。在这篇论文中,我们设计了一种新型的能直接处理点云的神经网络,它能很好地遵循输入点的置换不变性。我们将这个网络命名为PointNet,该网络为目标分类、部分分割和场景语义解析的应用提供了一个统一的架构。虽然PointNet十分简单,但是它十分高效。从经验来说,该网络表现出的强大性能和当前最优越的方法对等甚至更好。我们提供了理论分析来帮助理解该网络学习的内容,以及该网络在输入变化和损坏的情况下性能仍然如此稳定的原因。
主要贡献
1、本文提出了一种能直接处理无序三维点云的新型神经网络。
2、本文为该网络的稳定性和高效性提供了彻底的经验和理论分析;
3、在多个数据集上评估了该模型。
算法流程
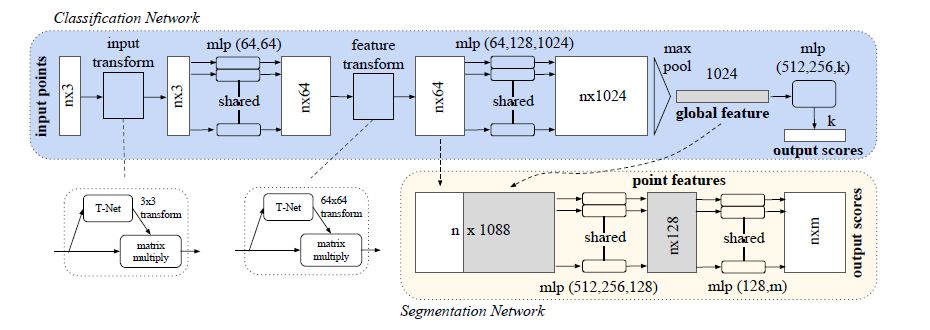
图1 本文网络的结构图
1、PointNet模型网络结构
分类网络将n个点作为输入,利用输入和特征变换,然后通过最大池化层聚焦点特征。输出k个类别的分类分数。分割网络是分类网络的一个延伸。它结合了全局特征、局部特征以及每个点输出的分数。“mlp”代表多层感知器,括号中的数字代表层的大小,批量标准化和线性修正单元应用到了每一层。Dropout用在分类网的最后一个多层感知器中。
1.1 三大关键模块
作为对称函数的最大池化层聚焦来自所有点的信息;局部信息和全局信息融合的结构;和两个可以对齐输入的点和点特征的联合对准网络。
1.2 设计原因
1.2.1 对无序输入的对称函数
为了使模型对输入置换具有不变性,有如下的三种方法可以实现:1)将输入分类成规范顺序;2)将输入转换成序列去训练循环神经网络,但是通过各种置换增加训练数据;3)仅仅使用一个对称函数来聚焦来自每个点的信息。
分类听起来很简单,在高维空间中实际上并不存在一般意义上的点置换的稳定排序。其次,循环神经网络对短序列(12个)输入顺序具有相当良好的稳定性,但去处理成千上万个输入元素仍然非常难。本文的基本模型非常简单,利用多层感知网络和最大池化层函数搭建,这样效果很好。
1.2.2 局部信息和全局信息的融合
点云分割需要局部和全局信息的组合。在计算出全局点云特征向量之后,本文通过将全局特征和每个点的特征相结合,将全局点云特征向量反馈给每个点的特征来达到局部和全局信息的融合。
1.2.3 联合对准网络
在特征提取之前,将所有的输入集合对齐到一个规范化空间中去。本文通过一个迷你网络(T-net)预测了一个仿射变换矩阵,并直接对输入点的坐标进行了这种变换。该网络由点的独立特征提取、最大池化层和全连接层的基本模型所组成。
2、理论分析
2.1 通用逼近
本文网络对连续集合函数的通用逼近能力。由于集合函数的连续性,直觉上,对输入点集的轻微置换应该不会对函数值有很大改变,比如分类分数或者分割分数。
定理1.假设f:X→R是关于Hausdorff距离的连续集合函数。任意ε>0,存在一个连续函数h和一个对称函数g(x1,…,xn)= γ◦ MAX,对任何S ϵ X ,
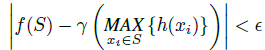
此处的x1,…,xn是集合S中按任意顺序的全体元素,γ是一个连续函数,MAX是将n个向量作为输入然后返回一个元素最大值的新向量。
2.2 瓶颈维度和稳定性
无论从理论上还是实验上,本文都发现最大池化层的维度K极大影响着网络的性能。
定理2:
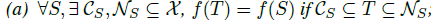
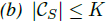
将Cs定义为S的关键点集,将K定义为f的瓶颈维度。本文的网络学会了通过稀疏关键点集总结出形状。实验部分可见,关键点组成了物体的骨架部分。
主要结果
1、 三维目标分类
在ModelNet40形状分类基准库上评估了本文模型。该库中有12311个人造物体类别的CAD模型,其中9843个用于训练,2468个用于测试。比较结果如表1所示。其中所用基线为使用多层感知器对点云的传统特征进行提取。表中可见本文网络实现了最好的性能。仅用全连接层和最大池化层,本文的网络在推理速度上有很强的领先优势,并且很容易在CPU上并行化。但本文方法和多视图的方法(MVCNN)相比还有微小差距,可以认为这是由于从已经渲染的图像中所捕捉到的一些良好的良好细节的丢失所造成的。
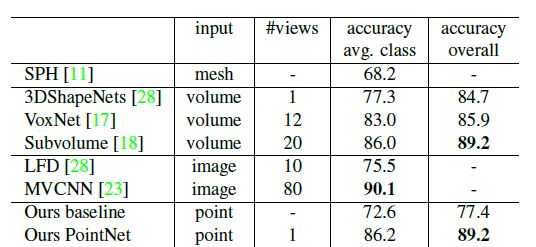
表1 网络在ModelNet40上的分类结果及对比
2、三维目标部分分割
本文用ShapeNet部分数据集评估了模型,该数据集包含了来自16个类别的16881个形状。评估指标为mIoU。该部分比较了本文模型分割版与两种传统方法,结果如表2可见。PointNet方法在mIoU指标上实现了最好的性能。本文网络在多数类别上超越了基线且mIoU有2.3%的提升。

表2 ShapeNet部分数据集上的分割结果
3、场景语义分割
本文用斯坦福三维语义解析数据集做实验。首先将点按照房间分开,然后将房间采样成1mx1m的方块,训练PointNet的语义版预测方块中每个点的类别。训练时,随机从运行中的每个方块采样4096个点。测试时将会测试所有的点。

表3 场景语义分割的结果(13个类别的平均IoU)
从上述结果来看,PointNet的性能大大超越基线方法。图2为其定性分割结果。本文网络可以顺畅输出预测值,并对丢失的点的遮挡物具有良好的鲁棒性。

图2 场景语义分割的定性结果
基于从我们的网络输出的语义分割结果,本文进一步建立了一个针对目标连通分量的三维目标检测系统。本文在表4中比较了目前顶尖的方法。
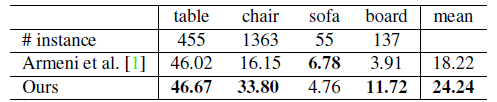
表4 场景中三维目标检测的结果
4、结构设计选择
4.1 与其他顺序不变性方法对比
至少有三种方法来保持输入点集的顺序不变性,该实验与下面两个对比实验都将用到ModelNet40数据集。
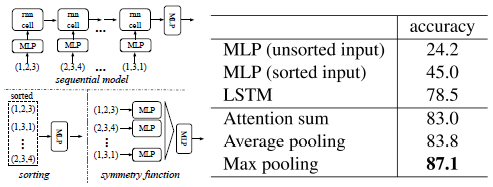
图3 实现顺序不变性的三种方法
所进行实验的对称操作包括最大池化层,平均池化层和基于权重和注意力机制。如图3所示,最大池化操作表现出最好的性能,并远超其他方法。
4.2 输入变换和特征变换的有效性
该实验为了证明网络中的输入变换和特征变换(用于对齐)的积极作用。使用输入变换对性能带来了0.8%的提升。下表为测试效果,性能指标为ModelNet40测试集上的整体分类准确性。

表5 输入特征变换的效果
4.3 鲁棒性测试
该实验为了证明PointNet不仅简单有效,而且对各种输入损坏也有良好的鲁棒性。性能指标为对ModelNet40测试集的整体分类准确性。左图为有50%的点丢失时,网络的准确性仅下降2.4%以及随机输入采样时下降3.8%。中间图表明网络对异常值有很好的鲁棒性。右图为置换,分别对每个点加上高斯噪声,显示了网络对点置换性的稳定性。
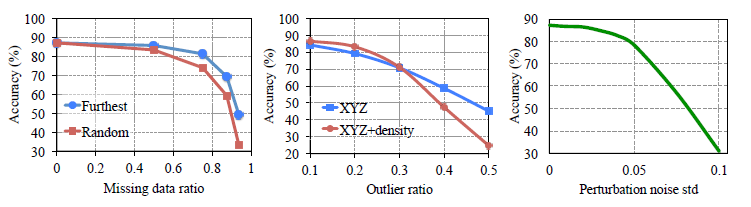
图4 PointNet鲁棒性测试

Abstract
Point cloud is an important type of geometric data structure. Due to its irregular format, most researchers transform such data to regular 3D voxel grids or collections of images. This, however, renders data unnecessarily voluminous and causes issues. In this paper, we design a novel type of neural network that directly consumes point clouds, which well respects the permutation invariance of points in the input. Our network, named PointNet, provides a unified architecture for applications ranging fromobject classification, part segmentation, to scene semantic parsing. Though simple, PointNet is highly efficient and effective. Empirically, it shows strong performance on par or even better than state of the art. Theoretically,we provide analysis towards understanding of what the network has learnt and why the network is robust with respect to input perturbation and corruption.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



