Transformers就是图神经网络?NTU-Chaitanya Joshi论述: 是GNN的一个特例
工程师朋友经常问我:Graph Deep Learning听起来很棒,但是有什么商业上的成功故事吗?它是否部署在实际应用中?
最明显的例子是Pinterest、阿里巴巴和twitter的推荐系统,它的成功之处在于,Transformer架构席卷了NLP行业。
通过这篇文章,我想建立图神经网络(GNNs)和Transformers之间的联系。我将讨论NLP和GNN社区中模型架构背后的直觉,使用方程和图形进行连接,并讨论我们如何合作来推动进展。
让我们从讨论模型架构-表示学习的目的开始。
NLP 表示学习
在较高的层次上,所有的神经网络架构都将输入数据表示为向量/嵌入,并对有关数据的有用统计和语义信息进行编码。这些潜在的或隐藏的表示法可以用于执行一些有用的操作,例如对图像进行分类或翻译句子。神经网络通过接收反馈(通常是通过误差/损失函数)来学习建更好的表示。
对于自然语言处理(NLP),通常递归神经网络(RNNs)以顺序的方式构建句子中每个单词的表示,即,一次一个词。直观地说,我们可以把RNN层想象成一个传送带,在这个传送带上从左到右自回归地处理单词。最后,我们得到了句子中每个单词的一个隐藏特征,我们将其传递给下一个RNN层或用于我们选择的NLP任务。
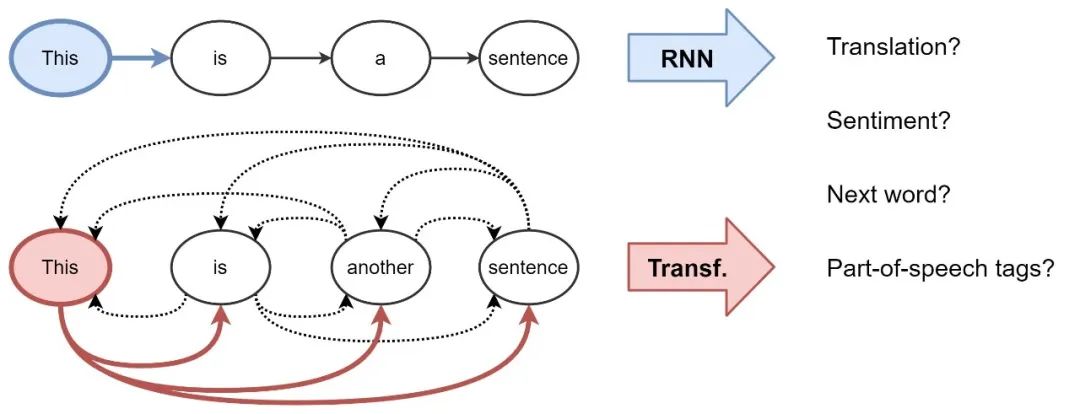
Transformers 最初用于机器翻译,现在已经逐渐取代了主流NLP中的RNNs。该架构采用了一种全新的表示学习方法:完全消除递归,transformer使用一种注意力机制构建每个单词的特征,以确定句子中所有其他单词对前面提到的单词的重要性。知道了这一点,单词的更新特征就是所有单词特征的线性变换的和,并根据它们的重要性进行加权。
拆分 Transformers
让我们通过将前一段翻译成数学符号和向量的语言来发展对体系结构的直觉。我们将句子中第一个单词的隐藏特征h逐层更新如下:
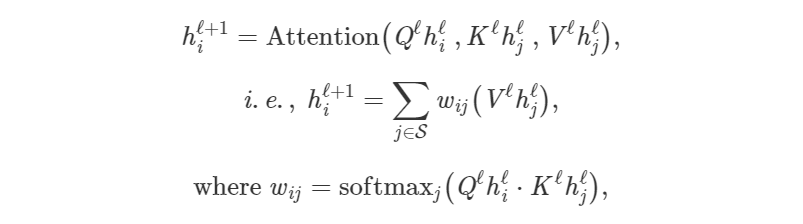

对句子中的每个单词并行执行注意力机制,从而在一个shot中获得它们的更新特征—在RNNs之上的Transformer的另一个加分点,RNNs逐字更新特征。
我们可以通过以下途径更好地理解注意力机制:
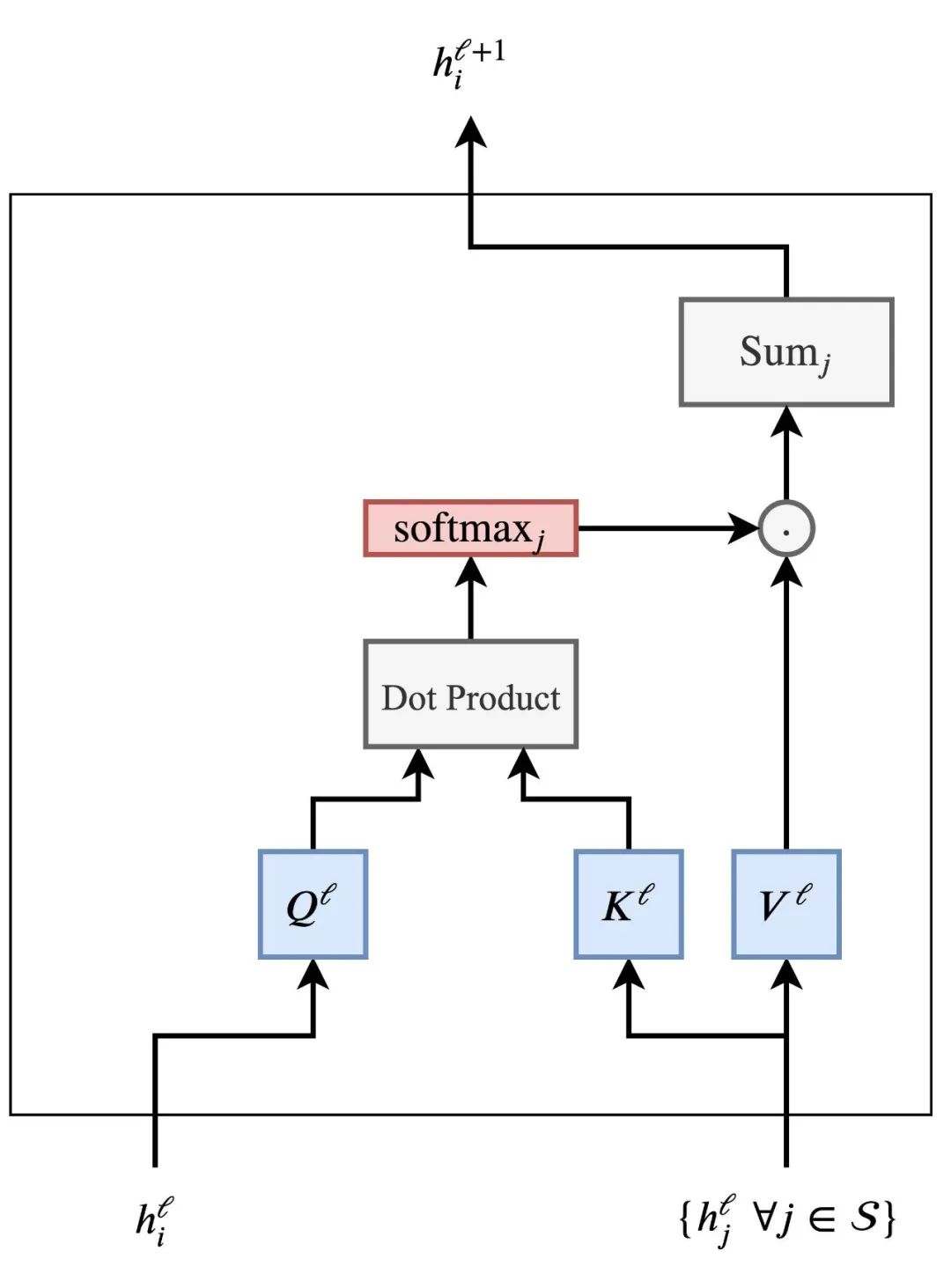

多头注意力机制
让这种点积注意力机制起作用被证明是棘手的——糟糕的随机初始化会破坏学习过程的稳定性。我们可以通过并行执行多个注意力“头”并将结果连接起来(每个头现在有单独的可学习权重)来克服这个问题:

多个头允许注意力机制从本质上“对冲其赌注”,从上一层看不同的转换或隐藏特征的方面。我们稍后会详细讨论。
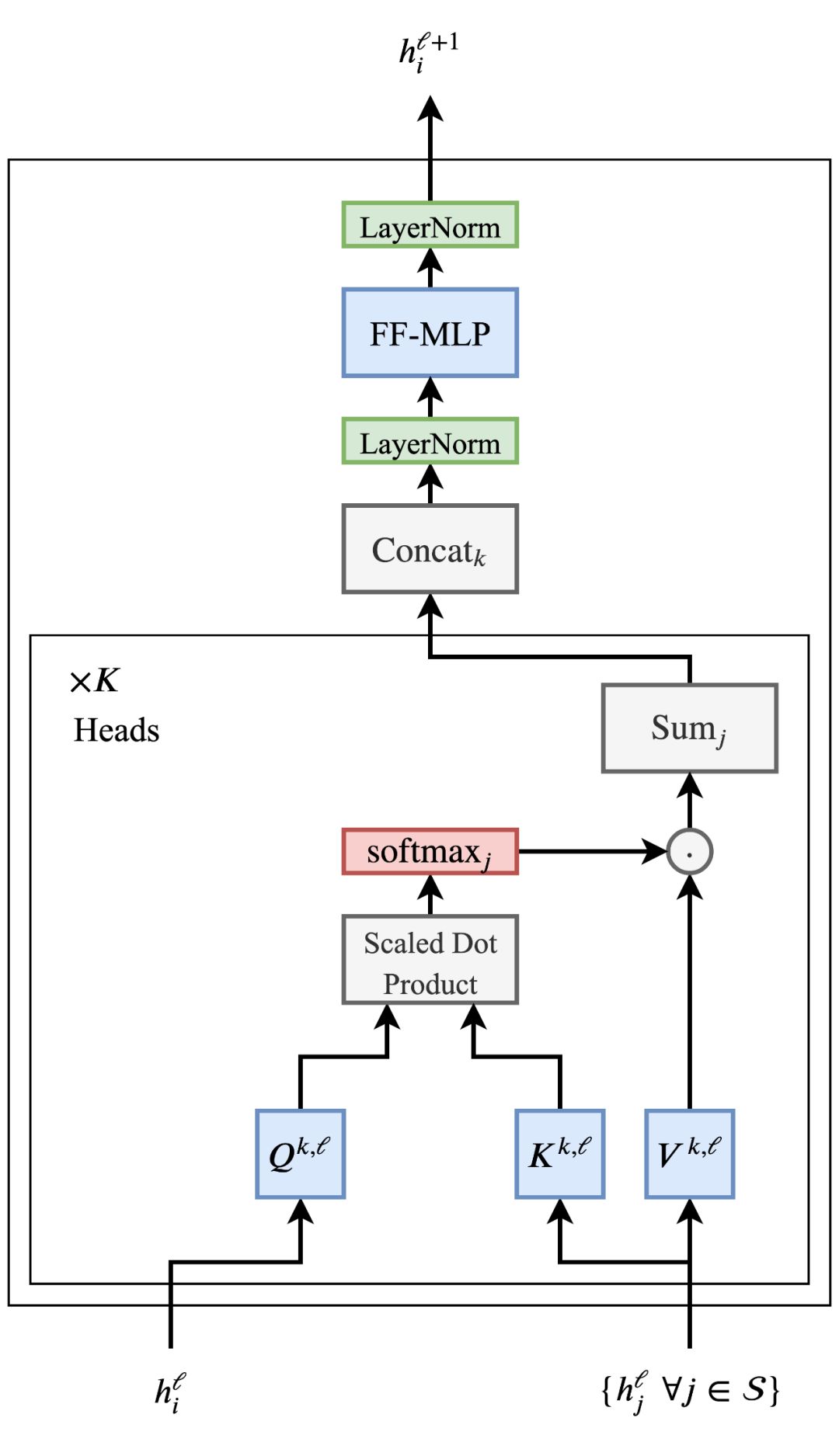
规模问题和前馈子层
Transformer架构也非常适合非常深的网络,这使得NLP社区能够根据模型参数和扩展的数据进行扩展。每个多头注意力子层的输入和输出与前馈子层之间的剩余连接是叠加Transformer 的关键(为了清晰起见,在图中省略)。
GNNs构建图的表示
图神经网络(GNNs)或图卷积网络(GCNs)构建图数据中节点和边的表示。它们通过邻居聚合(或消息传递)实现这一点,其中每个节点从其邻居处收集特性,以更新其周围的本地图结构表示。叠加几个GNN层使模型能够在整个图中传播每个节点的特性——从它的邻居传播到邻居的邻居,等等。

以这个表情符号社交网络为例: GNN产生的节点特征可以用于预测任务,比如识别最有影响力的成员或提出潜在的联系。

邻近节点的总和可以用其他输入大小不变的聚合函数(如简单的mean/max)或更强大的函数(如通过注意机制的加权和)代替。
这听起来熟悉吗?
也许一个流程图将有助于建立连接:

如果我们做多个平行的邻居聚合头,用注意力机制代替对邻居的求和,即,一个加权和,我们得到了图形注意网络(GAT)。加上标准化和前馈MLP,瞧, 我们有了一个图形转换器!
句子是完全连接的词图
为了使连接更加明确,可以将一个句子看作一个完全连接的图,其中每个单词都连接到其他每个单词。现在,我们可以使用GNN为图(句子)中的每个节点(单词)构建特性,然后我们可以使用它执行NLP任务。
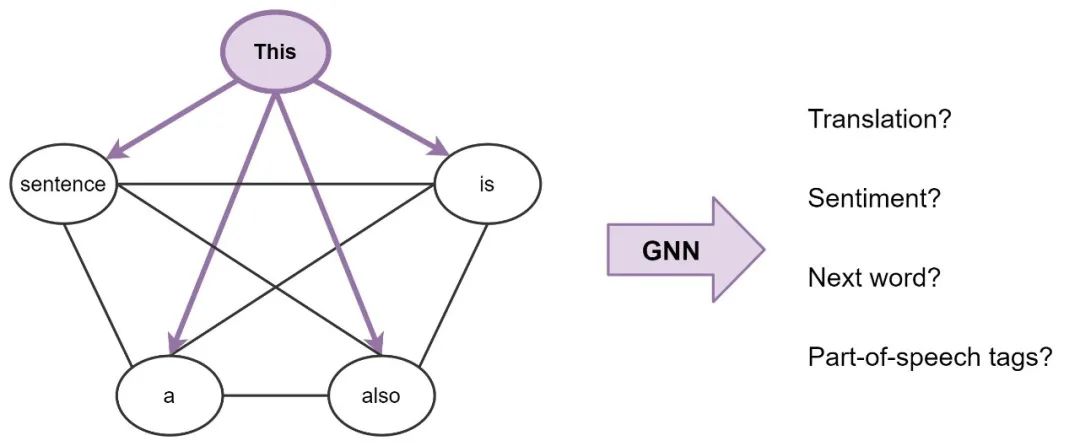
广义地说,这就是Transformers正在做的: 它们是具有多个头部注意力的GNN,作为邻居聚合函数。标准的GNNs聚合本地近邻节点的特征,而NLP的转换器将整个句子视为本地近邻,在每一层聚合每个单词的特征。
重要的是,各种特定问题的技巧——例如位置编码、因果/掩蔽聚合、学习速率表和广泛的预培训——对于Transformers的成功至关重要,但在GNN社区中很少出现。与此同时,从GNN的角度来看待Transformers可以激励我们摆脱算法架构中的许多花哨的东西。
我们可以互相学习什么?
现在我们已经建立了Transformers 和GNNs之间的联系,让我来提出一些想法……
全连通图是NLP的最佳输入格式吗?
在统计NLP和ML之前,像诺姆·乔姆斯基这样的语言学家致力于发展语言结构的正式理论,如语法树/图。Tree LSTMs已经尝试过了,但是transformer /GNNs可能是更好的架构,可以让语言理论和统计NLP更加接近?
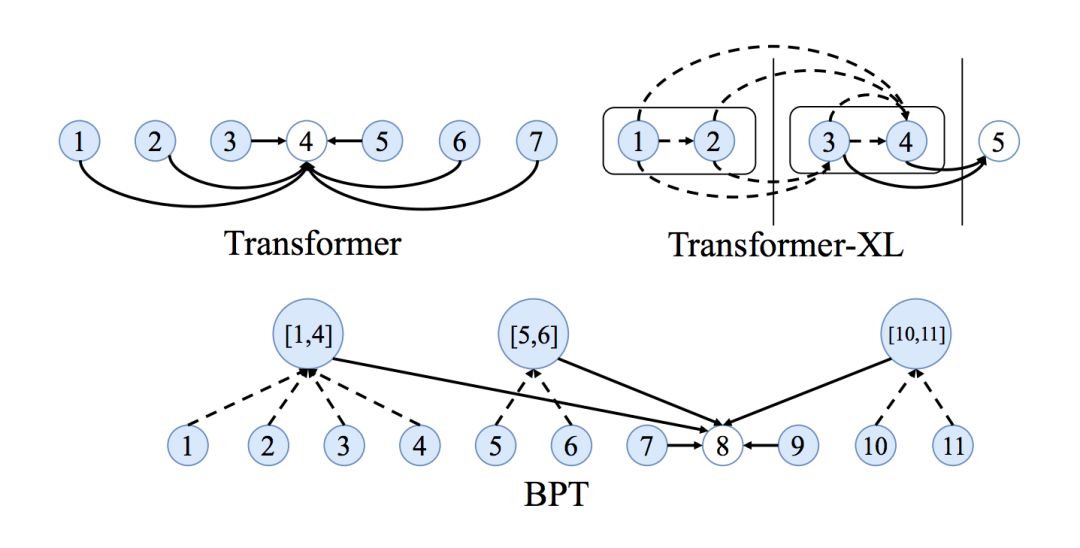
如何学习长期依赖?
全连通图的另一个问题是,它们使得学习单词之间的长期依赖关系变得困难。这仅仅是由于图中的边的数量与节点的数量成二次比例关系,即例如,在一个单词句子中,Transformer/GNN将对成对的单词进行计算。计算规模大到无法控制。
NLP社区对长序列和依赖关系问题的看法很有趣:使注意力机制在输入大小方面变得稀疏或自适应,在每一层中添加递归或压缩,以及使用局部敏感哈希来获得有效的注意力,这些都是更好的Transformers的新想法。
看到来自GNN社区的想法混合在一起会很有趣,例如,用于句子图稀疏化的二进制分区似乎是另一种令人兴奋的方法。
Transformers正在学习“神经语法”吗?
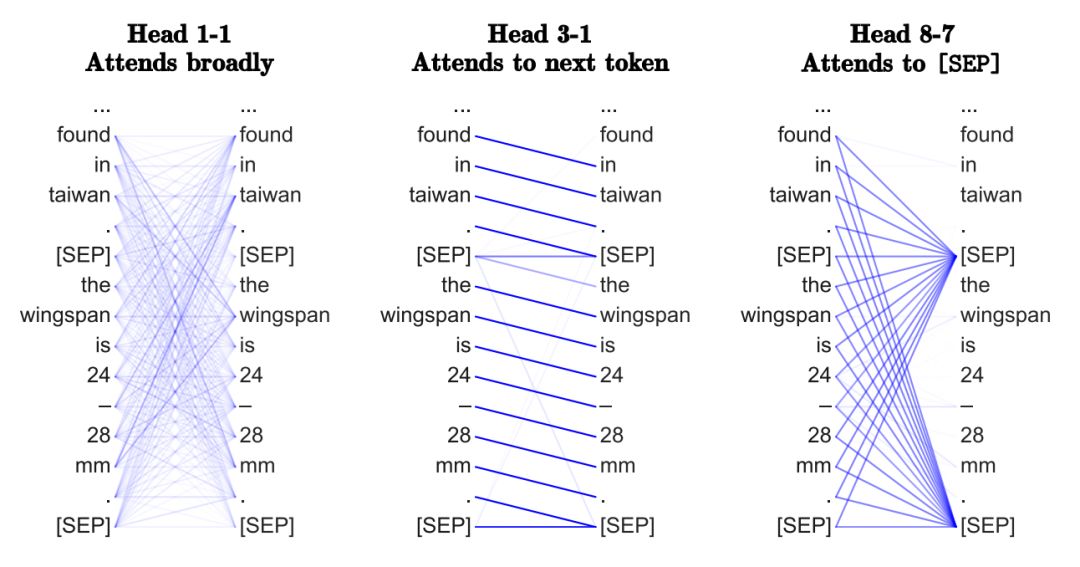
NLP社区已经发表了几篇关于Transformers的有趣文章。基本的前提是,在一个句子中对所有的词对进行注意力作用——目的是确定哪些词对是最有趣的——使转换器能够学习类似于特定于任务的语法。
多头注意力中的不同头脑也可能在“观察”不同的句法属性。
在图的术语中,通过在完整的图上使用GNN,我们能否从GNN如何在每一层执行近邻聚合中恢复最重要的边(以及它们可能包含的内容)?我还不太相信这种观点。
为什么要有多头注意力?为什么注意力?
我更赞同多头机制的优化观点——拥有多个注意力头可以改进学习,并克服糟糕的随机初始化。例如,这些论文表明,“修剪”或删除Transformer head 训练后没有显著的性能影响。
多头近邻聚集机制也被证明在GNNs中是有效的,例如GAT使用相同的多头部注意力,MoNet使用多个高斯核来聚集特征。虽然发明的目的是为了稳定注意力机制,但多头技巧能成为挤出额外模型性能的标准吗?
相反,具有简单聚合函数(如sum或max)的gnn不需要多个聚合头来进行稳定的训练。如果我们不需要计算句子中每个词对之间的成对兼容性,这对Transformer不是很好吗?
Transformer 能否完全摆脱注意力?Yann Dauphin和合作者最近的工作提出了一种替代的ConvNet架构。Transformer ,也可能最终会做一些类似于ConvNets的事情!
为什么Transformers的训练这么难?
阅读最新的Transformer论文让我觉得,在确定最佳学习速率计划、热身策略和衰减设置时,训练这些模型需要一些类似于trick的东西。这可能只是因为模型太庞大,而所研究的NLP任务又太具有挑战性。
但是,最近的结果表明,这也可能是由于规范化和架构内剩余连接的特定排列。
进一步的阅读
要从NLP的角度深入了解Transformer的体系结构,请查看这些令人惊叹的博客文章: 图解Transformer和注解Transformer。
http://jalammar.github.io/illustrated-transformer/
http://nlp.seas.harvard.edu/2018/04/03/attention.html
此外,本博客并不是第一个将GNNs和Transformer 联系起来的博客:以下是Arthur Szlam关于注意力/记忆网络、GNNs和Transformer 之间的历史和联系的精彩演讲。同样,DeepMind介绍了图形网络框架,统一了所有这些思想。DGL团队有一个关于seq2seq(图问题)和构建转换器(GNNs)的很好的教程。
在我们下一篇文章里, 我们会做相反的: 使用GNN架构作为Transformer NLP(基于Transformer 图书馆🤗HuggingFace)。
最后,我们写了一篇将Transformer 应用于草图的论文。一定要去看看!
https://graphdeeplearning.github.io/publication/xu-2019-multi/
参考地址:
https://graphdeeplearning.github.io/post/transformers-are-gnns/
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复"NTUGNN” 就可以获取《【南洋理工大学课程】图神经网络,Graph Neural Networks,附121页PPT》专知下载链接







