面向神经机器翻译的篇章级单语修正模型

作者 | 刘辉
单位 | 东北大学
编辑 | 唐里
刘辉,东北大学自然语言处理实验室2018级研究生,研究方向为机器翻译。
东北大学自然语言处理实验室由姚天顺教授创建于 1980 年,现由朱靖波教授、肖桐博士领导,长期从事计算语言学的相关研究工作,主要包括机器翻译、语言分析、文本挖掘等。团队研发的支持140种语言互译的小牛翻译系统已经得到广泛应用。

1、背景
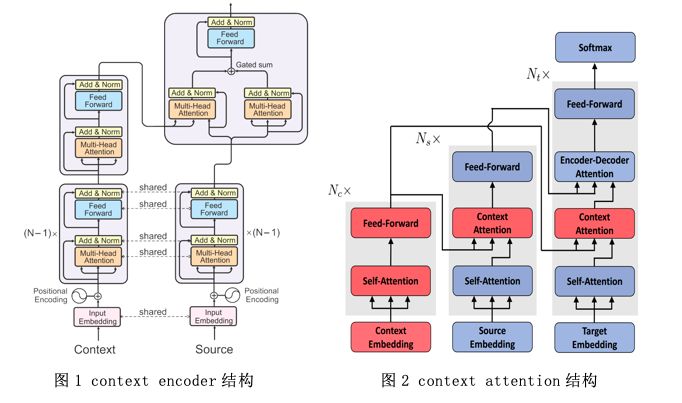
2、DocRepair模型

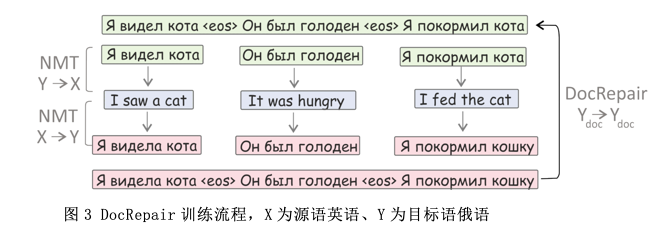
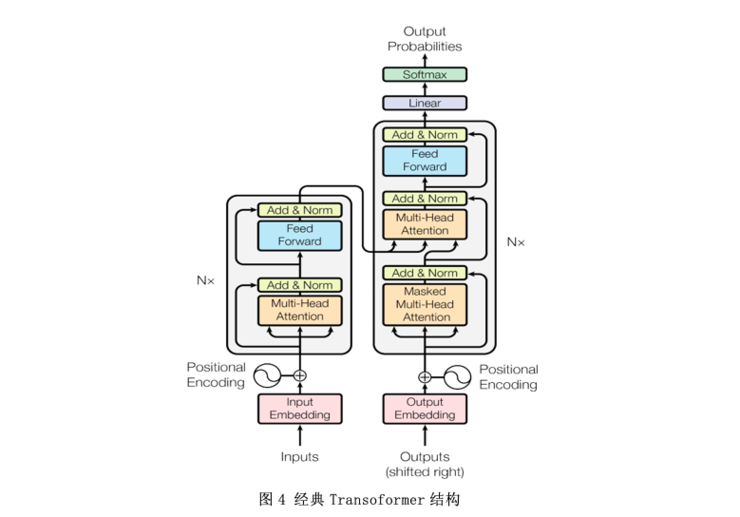
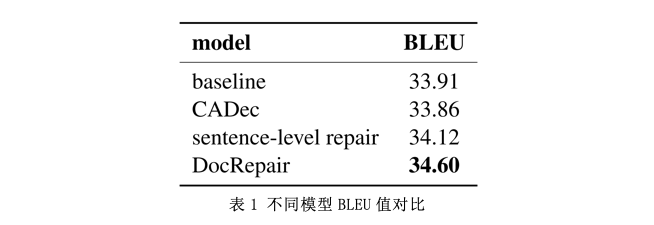
3、实验
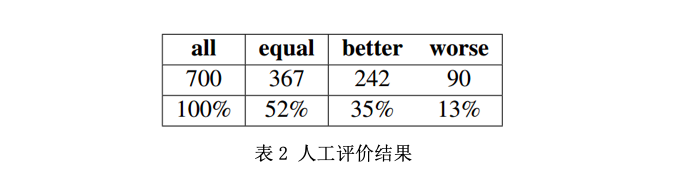
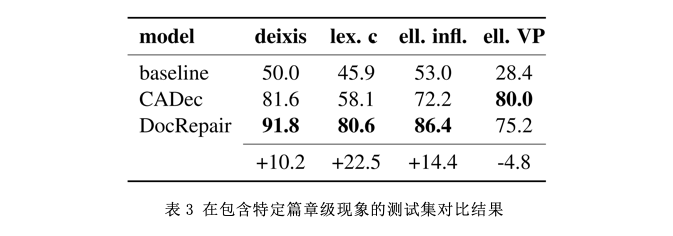
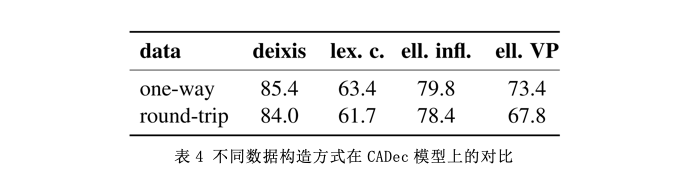
4、总结
相关文章



登录查看更多
相关内容

专知会员服务
79+阅读 · 2019年12月29日
专知会员服务
7+阅读 · 2019年12月19日
Arxiv
15+阅读 · 2018年10月11日
Arxiv
3+阅读 · 2018年3月20日




相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
专知会员服务
7+阅读 · 2019年12月19日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日
Arxiv
3+阅读 · 2018年3月20日