https://arxiv.org/abs/2301.05712
1. 引言深度监督学习算法在计算机视觉(computer vision, CV)和自然语言处理(natural language processing, NLP)等领域取得了令人满意的性能。监督学习算法通常需要大量的标记样本才能获得更好的性能。由于以下两个主要原因,在ImageNet等大规模数据库上训练的模型被广泛用作预训练模型,然后进行微调以用于其他任务(表1)。首先,在不同的大规模数据库上学习到的参数提供了一个很好的起点。因此,在其他任务上训练的网络可以更快地收敛。其次,在大规模数据库上训练的网络已经学习到相关的层次特征,这有助于减少其他任务训练过程中的过拟合问题,特别是当其他任务中的示例数量较少或训练标签有限时。**不幸的是,在许多真实的数据挖掘和机器学习应用中,虽然可以找到许多未标记的训练样本,但通常只有有限的标记样本。**标记的示例通常是昂贵、困难或耗时的,因为它们需要有经验的人类注释人员的努力。例如,在web用户特征分析中,可以很容易地收集到大量的web用户特征,但标注这些数据中的非盈利用户或盈利用户需要检查、判断,甚至是耗时的跟踪任务,需要有经验的人工评估人员执行,成本非常高。另一方面,在医疗领域,无标签样本可以很容易地从常规体检中获得。然而,对如此多的病例进行逐一诊断,给医学专家带来了沉重的负担。例如,为了进行乳腺癌诊断,放射科医生必须为大量容易获得的高分辨率乳房x光片中的每个焦点分配标签。这个过程通常非常低效和耗时。此外,监督学习方法存在虚假关联和泛化误差,容易受到对抗攻击。为了缓解监督学习的两个局限性,许多机器学习范式被提出,如主动学习、半监督学习和自监督学习(SSL)。本文主要讨论SSL。SSL算法被提出,用于从大量未标记的实例中学习良好的特征,而无需使用任何人工标注。SSL的一般流程如图1所示。在自监督预训练阶段,设计预定义的前置任务供深度学习算法求解,并根据输入数据的某些属性自动生成用于前置任务的伪标签。然后,训练深度学习算法来学习解决前置任务;在自监督预训练过程完成后,学习到的模型可以作为预训练模型进一步迁移到下游任务(特别是当只有相对较少的样本可用时),以提高性能并克服过拟合问题。

由于在自监督训练期间不需要人工标注来生成伪标签,SSL算法的一个主要优点是它们可以充分利用大规模未标记数据。使用这些伪标签进行训练的自监督算法取得了有希望的结果,自监督和监督算法在下游任务中的性能差距缩小了。Asano et al.[1]表明,即使在单一图像上,SSL也可以令人惊讶地产生泛化良好的低级特征。SSL[2] -[19]最近受到越来越多的关注(图2)图灵奖获得者,在第八届国际学习表征会议(ICLR 2020)上做了主题演讲,他的演讲题目是“the future is self - supervised”。Yann LeCun和Yoshua Bengio都获得了图灵奖,他们说SSL是人类级别的智能[20]的关键。谷歌学者表示,目前已经发表了大量与SSL相关的论文。例如,2021年发表了大约18,900篇与SSL相关的论文,每天大约有52篇论文,或每小时超过两篇论文(图2)。为了防止研究人员迷失在如此多的SSL论文中,并整理最新的研究成果,我们试图及时提供这一主题的调研。

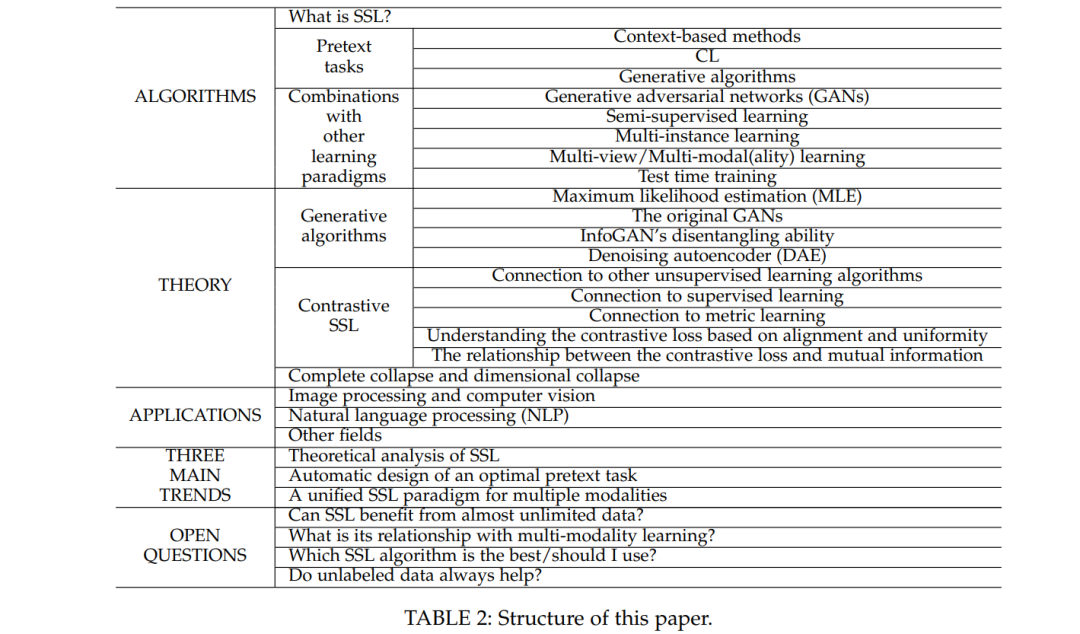
本文的其余部分组织如下。第2-7节从算法、理论、应用、三个主要趋势、开放问题和性能比较的角度介绍SSL,如表2所示。最后,第8节对调研进行了总结。