自监督如何做推荐?昆士兰大学最新《自监督学习推荐系统》综述论文,阐述对比、生成、预测和混合四大类方法
自监督推荐最新综述论文

基于神经体系结构的推荐系统近年来取得了巨大的成功。但是,在处理高度稀疏的数据时,仍然达不到预期。自监督学习(Self-supervised learning, SSL)作为一种利用无标记数据进行学习的新兴技术,近年来受到了广泛的关注。也有越来越多的研究将SSL应用到推荐中,以缓解数据稀疏问题。本综述对自监督推荐(SSR)的研究成果进行了及时、系统的回顾。在此基础上,我们建立了一个完整的SSR分类体系,将现有的SSR方法分为四大类: 对比型(contrast)、生成型(generative)、预测性(predictive)和混合型(hybrid)。同时,为了促进SSR模型的开发和评估,我们发布了一个开源库SELFRec,它包含了多个基准数据集和评估指标,并实施了一些最先进的SSR模型进行实证比较。最后,指出了当前研究的局限性,并提出了未来的研究方向。
https://www.zhuanzhi.ai/paper/6b548128dd84c330a15c19439e8fb3a8
引言
推荐系统[1]是一个可以发现用户潜在兴趣并简化决策过程的工具,已经广泛应用于各种在线电子商务平台,在创造愉快的用户体验的同时增加收入。近年来,现代推荐系统[2]、[3]、[4]在具有高度表达能力的深度神经架构的支持下取得了巨大的成功,并取得了无与伦比的性能。然而,深度推荐模型天生就需要数据。要利用深度架构,需要大量的训练数据。与众包的图像标注不同,推荐系统中的数据获取成本较高,个性化推荐依赖于用户自己生成的数据,而大多数用户通常只能消费/点击无数项[5]中的一小部分。因此,数据稀疏性问题成为深度推荐模型实现其最大潜力[6]的瓶颈。
自监督学习(Self-supervised learning, SSL)[7]作为一种学习范式,可以减少对手工标签的依赖,并能对大量未标记数据进行训练,最近受到了广泛的关注。SSL的基本思想是通过精心设计的前置任务(即自监督任务)从丰富的无标记数据中提取信息丰富、可转移的知识,其中监督信号是半自动生成的。由于普遍的能力克服标签不足问题,SSL已经应用于广泛的领域包括可视化表示学习[8],[9],[10],语言模型训练的“[11],[12],音频学习[13],表示节点/图分类[14],[15],等等,它已被证明是一个强大的技术。由于SSL的原则与推荐系统对更多注释数据的需求很好地匹配,受SSL在上述领域的巨大成功的推动,现在有大量且不断增长的研究正在将SSL应用到推荐中。
自监督推荐(SSR)的早期原型可以追溯到非监督推荐方法,如基于自动编码器的推荐模型[16]、[17],它们依靠不同的被破坏的数据来重构原始输入以避免过拟合。随后出现了基于网络嵌入的推荐模型[18],[19],其中利用随机行走接近度作为自监督信号,捕捉用户与物品之间的相似性。在同一时期,一些基于生成式对抗网络[20](GANs)的推荐模型[21]、[22]可以看作是SSR的另一种体现,它们增强了用户-物品交互。2018年,在预训练语言模型BERT[12]取得巨大突破后,SSL作为一个独立的概念进入人们的视野。随后,推荐社区开始接受SSL,随后的研究[23],[24],[25]将注意力转移到基于顺序数据的Cloze-like任务的预训练推荐模型上。自2020年以来,SSL经历了一段繁荣时期,最新的基于SSL的方法在许多CV和NLP任务[9],[26]中几乎与监督的同行表现相当。特别是,对比学习(CL)[27]的复兴显著地推动了SSL的前沿。与此同时,[28],[29],[30],[31],[32],[33]也掀起了对SSR的狂热。SSR的模式变得多样化,场景不再局限于序列推荐。
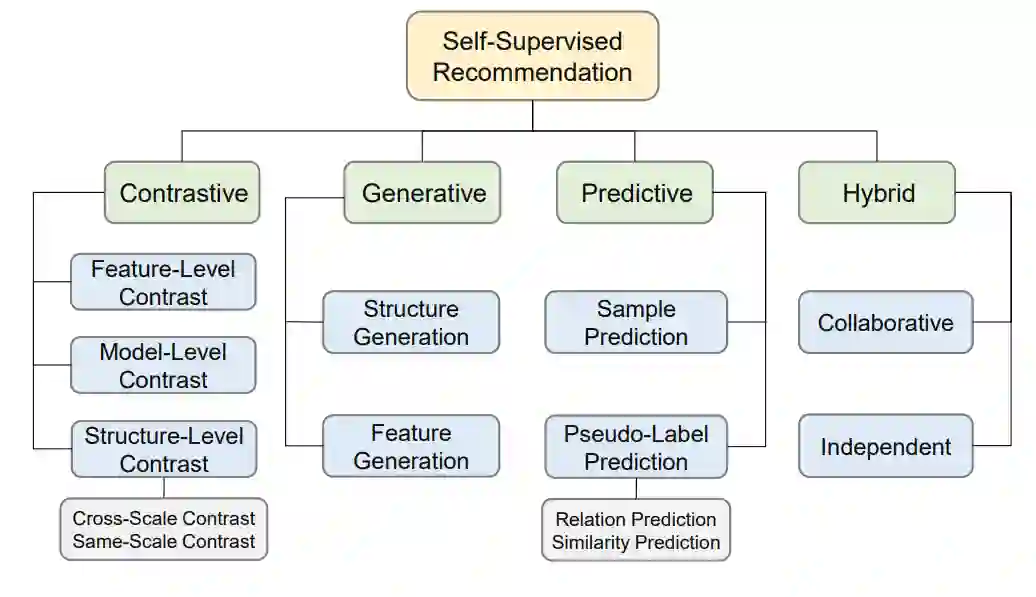
自监督推荐方法体系
虽然在CV、NLP[34]、[7]和图学习[35]、[36]、[37]等领域对SSL进行了一些综述,但在论文数量快速增长的情况下,对SSR的研究还没有进行系统的综述。与上述领域不同的是,推荐涉及到大量优化目标不同的场景,并处理多种类型的数据,因此很难将为CV、NLP和图任务设计的现成SSL方法完美地推广到推荐中。因此,它为新型SSL提供了土壤。同时,高偏数据分布[38]、广泛观察的偏差[39]、推荐系统特有的大词汇量类别特征[40]等问题也催生了一系列独特的SSR方法,丰富了SSL族。随着SSR研究的日益普及,迫切需要对其进行及时、系统的综述,总结已有的SSR研究成果,探讨现有SSR研究成果的优势和不足,以促进未来SSR研究的发展。为此,我们提出了一个最新的和全面的回顾SSR的前沿。总之,我们的贡献有四方面:
我们调研了广泛的SSR方法,以涵盖尽可能多的相关论文。据我们所知,这是第一次针对这个新话题的综述。
我们提供了对SSR的独家定义,并澄清了其与相关概念的联系。在此基础上,我们提出了一个综合的分类方法,将现有的SSR方法分为四大类:对比型、生成型、预测型和杂交型。对于每一个类别,叙述都沿着其概念和提法、涉及的方法及其利弊展开。我们相信,定义和分类为开发和定制新的SSR方法提供了清晰的设计空间。
我们引入了一个开源库,以促进SSR模型的实现和评估。它整合了多个基准数据集和评估指标,并实现了10+最先进的SSR方法进行实证比较。
我们阐明了现有研究的局限性,并确定了剩余的挑战和未来发展SSR的方向。
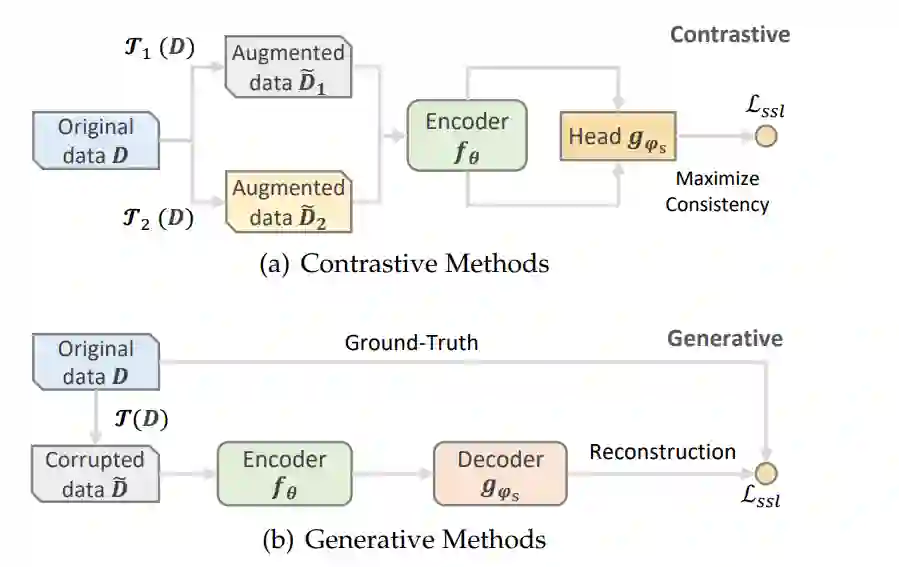
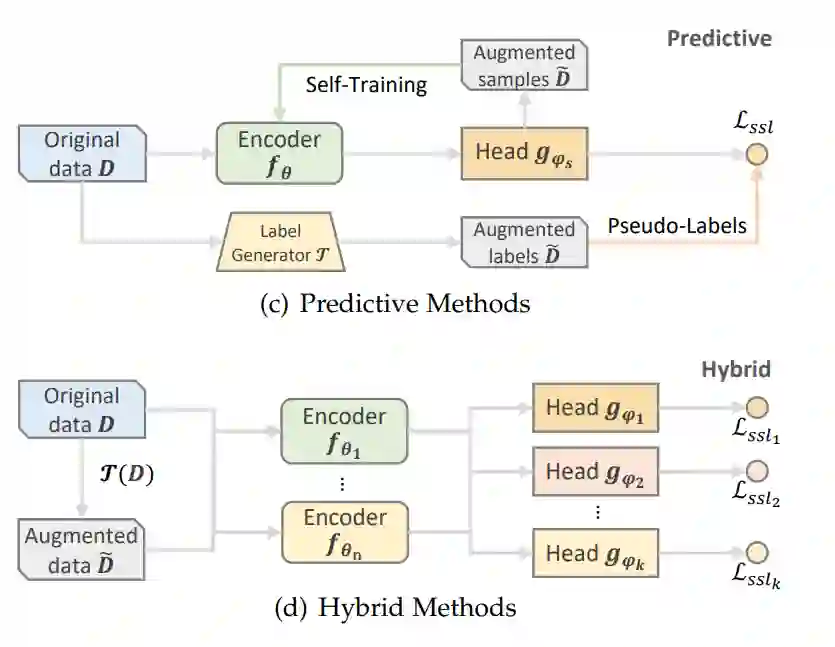
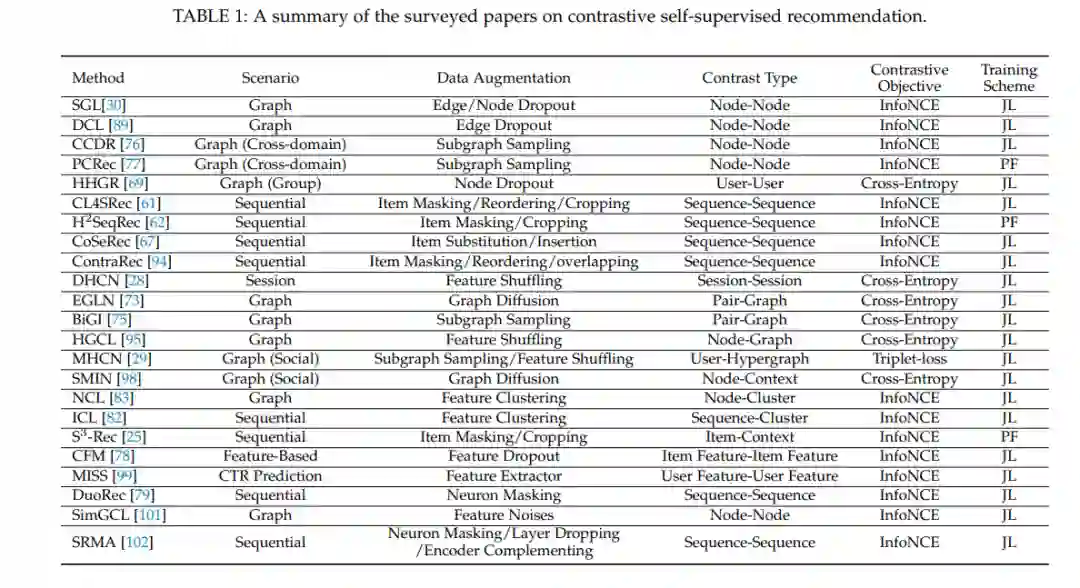
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SSLR” 就可以获取《昆士兰大学最新《自监督学习推荐系统》综述论文》专知下载链接







