![]()
聚类分析在机器学习和数据挖掘中起着不可或缺的作用。学习一个好的数据表示方法对于聚类算法是至关重要的。近年来,利用深度神经网络学习聚类友好表示的深度聚类已经广泛应用于各种聚类任务中。现有的深度聚类研究主要集中在单一视图领域和网络架构上,忽略了聚类的复杂应用场景。为了解决这个问题,在本文中,我们从数据源的角度对深度聚类进行了全面的考察。在不同的数据源和初始条件下,我们从方法论、先验知识和体系结构方面系统地区分了聚类方法。具体地,将深度聚类方法分为传统的单视图深度聚类、半监督深度聚类、深度多视图聚类和深度转移聚类四大类。最后,讨论了深度聚类在不同领域的开放挑战和潜在的未来机遇。
随着网络媒体的发展,可以很容易地收集到大量的、复杂度高的数据。通过对这些数据的精确分析,我们可以挖掘出这些结论的价值,并将这些结论应用于许多领域,如人脸识别[1],[2],情感分析[3],[4],智能制造[5],[6]等。可用于对具有不同标签的数据进行分类的模型是许多应用程序的基础。对于有标签的数据,理所当然地使用标签作为最重要的信息作为指导。对于未标记的数据,寻找一个可量化的目标作为模型构建过程的指导是聚类的关键问题。在过去的几十年里,人们提出了大量的浅层模型聚类方法,包括基于质心的聚类[7]、[8],基于密度的聚类[9]、[10]、[11]、[12]、[13],基于分布的聚类[14],分层聚类[15],集成聚类[16]、[17],多视图聚类[18]、[19]、[20]、[21]、[22]、[23]等。这些浅层模型只有在特征具有代表性的情况下才有效,而在复杂数据上,由于特征学习能力较差,其性能往往受到限制。
为了将原始复杂数据映射到易于聚类的特征空间,许多聚类方法都侧重于特征提取或特征变换,如PCA[24]、核方法[25]、谱方法[26]、深度神经网络[27]等。
在这些方法中,深度神经网络由于其出色的非线性映射能力和在不同场景下的灵活性,是一种很有前途的方法。一种设计良好的基于深度学习的聚类方法(简称深度聚类)旨在有效地从数据中提取更多对聚类友好的特征,并同时对学习到的特征进行聚类。在深度聚类领域已经做了大量的研究,也有一些关于深度聚类方法[28],[29],[30],[31]的综述。具体而言,现有的深度聚类系统综述主要集中在单视图聚类任务和神经网络的体系结构上。例如,Aljalbout等人[28]只关注基于深度自编码器(AE或DAE)的深度单视图聚类方法。Min等人[29]从不同深度网络的角度对深度聚类方法进行了分类。Nutakki等[30]根据训练策略将深度单视图聚类方法分为三大类:多步顺序深度聚类、联合深度聚类和闭环多步深度聚类。Zhou等人[31]通过特征学习与聚类模块的交互方式对深度单视图聚类方法进行分类。但在现实世界中,用于聚类的数据集总是相关联的,例如,阅读的品味与电影的品味相关联,同一个人的侧脸和正面应该被标记为相同的。针对这些数据,基于半监督学习、多视图学习和迁移学习的深度聚类方法也取得了显著进展。不幸的是,现有的综述并没有过多地讨论它们。
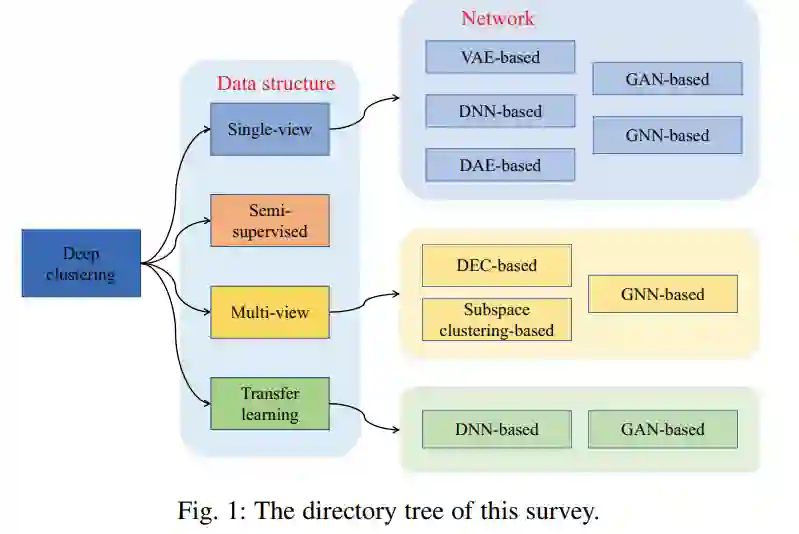
因此,从数据源和初始条件的角度对深度聚类进行分类非常重要。本文从数据初始设置的角度结合深度学习方法对深度聚类进行了总结。我们从网络和数据结构的角度介绍了深度聚类的最新进展,如图1所示。具体来说,我们将深度聚类方法组织为以下四类:
![]()
在传统的聚类任务中,通常假设数据具有相同的形式和结构,称为singleview或单模态数据。用深度神经网络(DNNs)提取这些数据的表示形式是深度聚类的一个重要特征。然而,更值得注意的是不同的应用深度学习技术,这些技术与dnn的结构高度相关。为了比较具体DNN的技术路线,我们将这些算法分为五类: 基于深度自编码器(DAE)的深度聚类、基于深度神经网络(DNN)的深度聚类、基于变分自编码器(VAE)的深度聚类、基于生成对抗网络(GAN)的深度聚类和基于图神经网络(GNN)的深度聚类。
当待处理数据包含少量先验约束时,传统的聚类方法无法有效利用这些先验信息,而半监督聚类是解决这一问题的有效方法。目前,深度半监督聚类的研究还没有得到很好的探索。然而,半监督聚类是不可避免的,因为通过向模型中添加额外的约束损失信息,使聚类方法成为半监督聚类方法是可行的。
在现实世界中,数据往往来自不同的特征收集器或具有不同的结构。我们称这些数据为“多视图数据”或“多模态数据”,其中每个样本都有多个表示。基于多视图学习的深度聚类的目的是利用多视图数据中所包含的一致性和互补性信息来提高聚类性能。此外,多视图学习的思想可能对深度单视图聚类具有指导意义。本文将深度多视图聚类归纳为三大类:基于深度嵌入聚类、基于子空间聚类和基于图神经网络聚类。
对于实例数量有限且维度较高的任务,有时我们可以找一个助手来提供额外的信息。例如,如果任务A与另一个任务B相似,而任务B比任务A具有更多的信息用于聚类(B是有标记的或B比A更容易聚类),那么将信息从B转移到A是有用的。无监督域适应(unsupervised domain adaption, UDA)转移学习包括两个域:有标记的源域和无标记的目标域。迁移学习的目标是将从源任务中学到的知识或模式应用到不同但相关的目标任务。基于迁移学习的深度聚类方法旨在利用相关任务的信息提高当前聚类任务的性能。
在研究相应的聚类方法之前,有必要注意聚类数据的不同特征和条件。本文从数据来源和初始条件两个方面对现有的深度聚类方法进行了系统的分类。分析了不同聚类方法的优缺点和适用条件。最后,我们提出了深度聚类领域的一些有趣的研究方向
![]()
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取100000+AI主题知识资料