视觉变换器(Vision Transformers,ViTs)最近引起了相当大的关注,作为卷积神经网络(CNNs)的有希望替代品,在几个与视觉相关的应用中显现出来。然而,它们庞大的模型尺寸以及高计算和内存需求阻碍了部署,特别是在资源受限的设备上。这强调了针对ViTs的算法-硬件协同设计的必要性,旨在通过定制算法结构和底层硬件加速器来优化它们的性能,以彼此的优势为依托。模型量化通过将高精度数值转换为低精度,减少了ViTs的计算需求和内存需求,允许创建专门为这些量化算法优化的硬件,提高效率。本文提供了ViTs量化及其硬件加速的全面综述。我们首先深入探讨ViTs的独特架构属性及其运行特性。随后,我们检查模型量化的基本原理,接着是对ViTs最先进量化技术的比较分析。此外,我们探索了量化ViTs的硬件加速,强调了硬件友好算法设计的重要性。最后,本文将讨论持续的挑战和未来研究方向。我们在
https://github.com/DD-DuDa/awesome-vit-quantization-acceleration 上持续维护相关的开源材料。
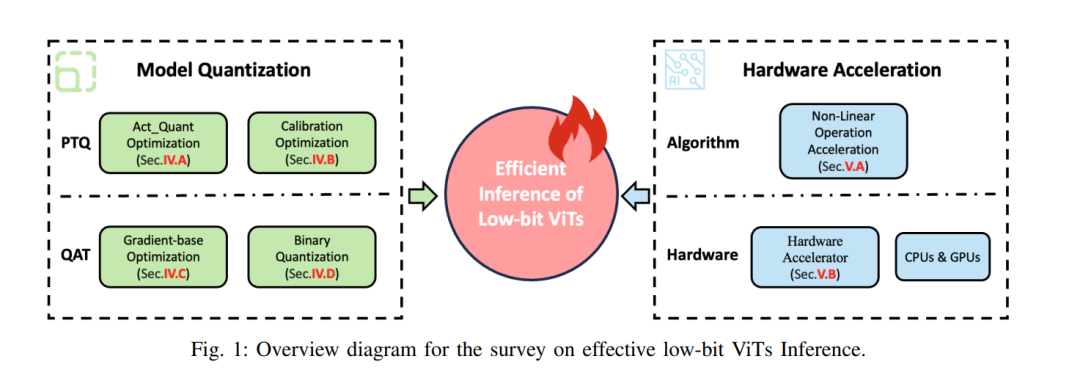
在计算机视觉领域,卷积神经网络(CNNs)历来是基石,已在众多任务中展示出显著的效果。然而,随着变换器(Transformer)架构的出现,情况开始发生变化。变换器在自然语言处理(NLP)中取得了巨大成功之后,被适配用于计算机视觉,形成了视觉变换器(Vision Transformers,ViTs)。ViTs的关键特性是自注意力(self-attention),它允许模型通过学习图像标记序列中元素之间的复杂关系,从而在上下文中分析视觉数据。这种把握更广泛上下文及图像内部依赖关系的能力,推动了基于变换器的视觉模型的迅速发展,并随后将它们确立为多种任务的新基础,包括图像分类、对象检测、图像生成、自动驾驶和视觉问题回答,展示了它们在计算机视觉中的多功能性和变革性影响。 尽管ViTs具备卓越的能力,但由于其本质上庞大的模型尺寸以及自注意力机制导致的计算和内存需求呈二次方增长,特别是在图像分辨率提高时,这些因素显著阻碍了其在计算和内存资源受限的设备上的部署,尤其是在如自动驾驶和虚拟现实等实时应用中,满足低延迟需求和提供高质量用户体验至关重要。这强调了对模型压缩技术如剪枝、量化、知识蒸馏和低秩分解等进步的迫切需要。此外,ViTs的迅速采用不仅归功于算法创新和数据可用性,还归功于处理器性能的提升。虽然CPU和GPU提供广泛的计算多样性,但它们固有的灵活性可能导致效率低下。鉴于ViTs的重复性但又独特的操作特性,利用专门设计的硬件来优化数据重用,从而提高ViT部署的效率,存在明显的机会。 量化是一种将高精度映射为低精度的技术,已成功地促进了轻量级和计算效率高的模型的创建,增强了算法与硬件的交互。在算法方面,有多种专门为ViTs设计的技术,旨在在数据压缩至较低位宽后保持应用的准确性。其中一些技术被设计得更符合硬件友好,考虑到现有的架构,如GPU的INT8/FP8 Tensorcore。在硬件方面,高级量化算法的优化推动了更高效处理器的设计,可能包括更有效的数据重用模块,用于并行处理低位数据。算法和硬件的共同设计是现代硬件加速器开发中的常见方法,显著提高了它们的性能。 然而,近年来发布的大量相关工作使得初学者难以获得全面的概述和清晰的比较结果。此外,一些在不考虑实际硬件的情况下模拟算法设计的方法,在部署时可能导致意外的精度低下。迫切需要一项全面的综述,总结、分析并比较这些方法。本文力求填补这一空白,提供了关于ViTs量化及其硬件加速的广泛回顾。具体而言,我们深入探讨了ViTs量化的细微挑战,从算法和硬件两个角度出发,提供了不同量化方法的纵向比较,并在图1中进行了说明。此外,我们展示了先进的硬件设计解决方案,并推测未来的趋势和潜在机会。与近期的综述相比——有些专注于各种高效技术但不考虑硬件,有些仅限于推理优化且算法细节有限,还有些提供了主要针对大型语言模型的模型压缩的广泛概览——本文提供了详细的描述和比较,以协同的方式处理算法与硬件的相互作用,从而提供了对ViTs量化领域更清晰、更有结构的洞见。 本文的组织结构如下所述。第二部分深入探讨了视觉变换器的架构,介绍了其变体,并通过分析其运行特性和瓶颈进行了剖析。第三部分阐述了模型量化的基本原理。随后,第四部分检查了与ViTs量化相关的迫切挑战,并提供了先前方法性能的比较回顾。第五部分探索了可用于硬件加速的方法范围。最后,第六部分总结了本文,突出了潜在的机会和挑战。