

深度学习在许多领域中表现出了显著的成功,包括计算机视觉、自然语言处理和强化学习。这些领域中的代表性人工神经网络包括卷积神经网络、Transformers 和深度 Q 网络。在单模态神经网络的基础上,引入了许多多模态模型以解决视觉问答、图像描述和语音识别等一系列任务。具身智能中遵循指令的机器人策略的兴起推动了被称为视觉-语言-动作模型(VLA)的新型多模态模型的发展。它们的多模态能力已经成为机器人学习中的基础要素。为了增强多样性、灵活性和泛化性等特性,提出了各种方法。一些模型通过预训练来优化特定组件,另一些则旨在开发能够预测低级动作的控制策略。某些VLA模型作为高级任务规划器,能够将长远任务分解为可执行的子任务。在过去几年中,出现了大量的VLA模型,反映了具身智能的快速进展。因此,通过一篇全面的综述来捕捉这一不断发展的领域是至关重要的。
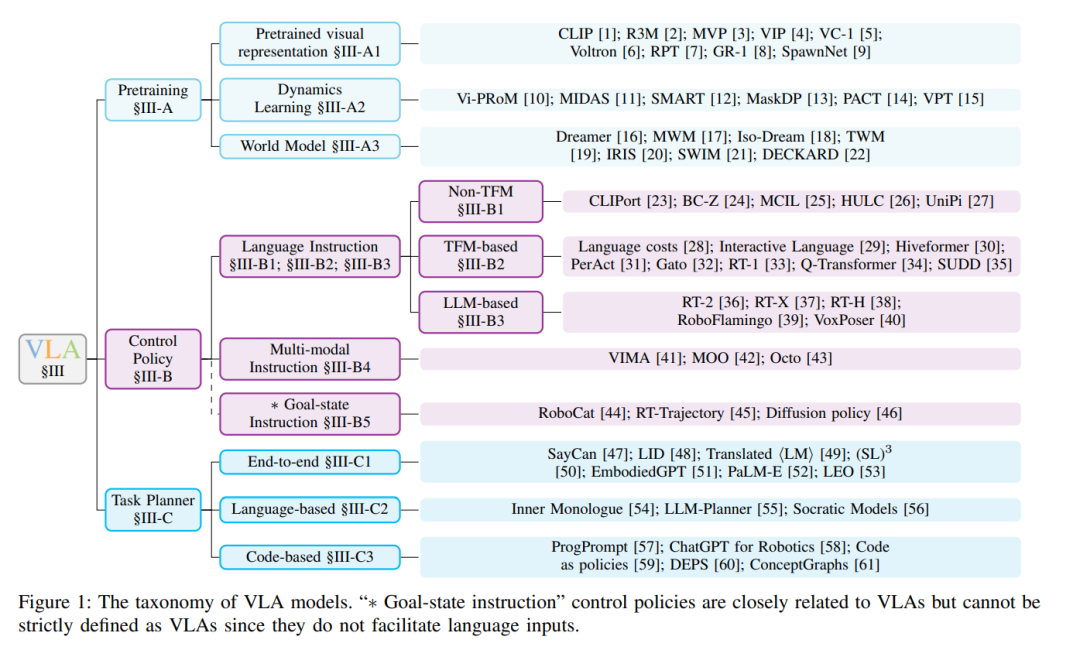
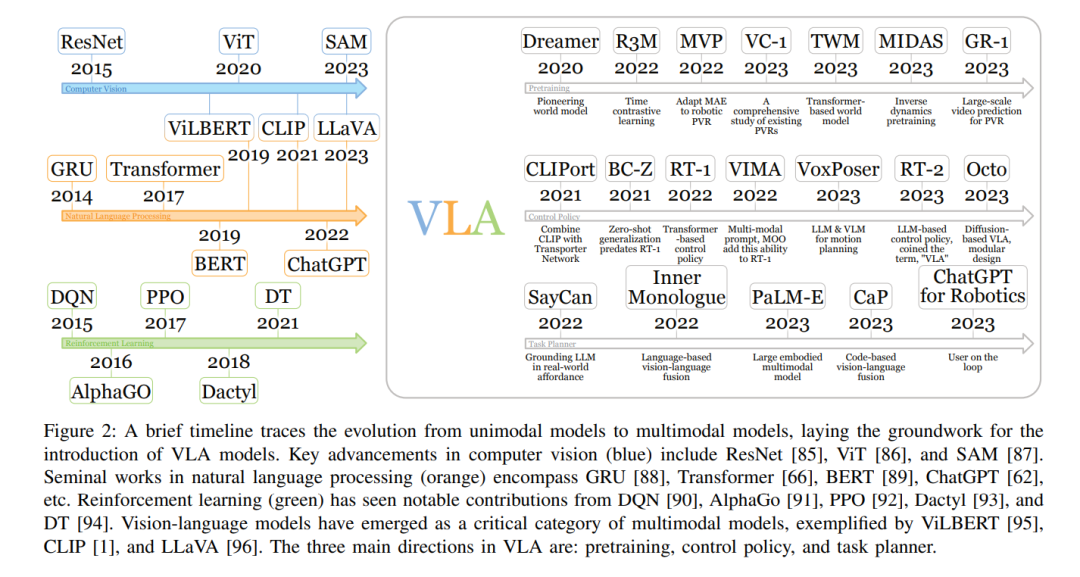
视觉-语言-动作模型(VLA)代表了一类旨在处理多模态输入的模型,结合了视觉、语言和动作模态的信息。该术语最近由RT-2 [36]提出。VLA模型被开发用于解决具身智能中的指令跟随任务。与以ChatGPT [62]为代表的对话式AI等其他形式的AI不同,具身智能需要控制物理实体并与环境互动。机器人是具身智能最突出的领域。在语言条件的机器人任务中,策略必须具备理解语言指令、视觉感知环境并生成适当动作的能力,这就需要VLA的多模态能力。相比于早期的深度强化学习方法,基于VLA的策略在复杂环境中表现出更优越的多样性、灵活性和泛化性。这使得VLA不仅适用于像工厂这样的受控环境,还适用于日常任务,如烹饪和房间清洁 [33]。 深度学习的早期发展主要由单模态模型组成。在计算机视觉(CV)领域,AlexNet [63]展示了人工神经网络(ANNs) [64]的潜力。循环神经网络(RNNs) [65]为许多自然语言处理(NLP)模型奠定了基础,但近年来,Transformers [66]逐渐占据了主导地位。深度Q网络证明了ANNs能够成功解决强化学习问题。借助于各个机器学习领域单模态模型的进步,多模态模型已经演变得足够强大,可以应对各种任务 [67],如视觉问答、图像描述和语音识别等。 基于强化学习的传统机器人策略主要集中在受控环境中的有限任务集,如工厂和实验室。例如,[68]训练了一个专门用于抓取物品的策略。然而,对于更具多样性的多任务策略的需求正在增长,类似于最近在大型语言模型(LLMs) [62], [69]和视觉-语言模型(VLMs) [70]中的发展。开发多任务策略更具挑战性,因为它需要学习更广泛的技能并适应动态和不确定的环境。此外,任务规范增加了另一个层次的复杂性。一些方法使用单热向量来选择任务 [71],但它们受限于训练集中任务的数量。 基于预训练视觉基础模型、大型语言模型(LLMs)和视觉-语言模型(VLMs)的成功,视觉-语言-动作模型已经证明其在应对这些挑战方面的能力。来自最新视觉编码器的预训练视觉表示帮助VLA在感知复杂环境时提供更精确的估计,如物体类别、物体姿态和物体几何形状。随着语言模型 [36], [69]能力的增强,基于语言指令的任务规范成为可能。基础VLMs探索了将视觉模型和语言模型整合的多种方式,包括BLIP-2 [72], Flamingo [70]等。这些不同领域的创新赋予了VLA解决具身智能挑战的能力。 不同的VLA在重点方面有所不同,如图1所示的分类法所描述。一些VLA通过为机器人任务专门设计的预训练任务来增强其预训练的视觉表示,主要集中在获取改进的视觉编码器。同时,大量工作致力于机器人控制策略。在这一类别中,语言指令被输入到控制策略中,策略根据环境生成动作。这些动作随后被传送到运动规划器以执行。相反,另一类VLA作为高级任务规划器,抽象掉了低级控制。这些模型专注于将长远的机器人任务分解为可执行的子任务。这些子任务然后由控制策略逐一完成,最终完成整个任务。 相关工作。尽管目前缺乏针对VLA的综述,但相关领域的现有综述为VLA研究提供了宝贵的见解。在计算机视觉领域,综述涵盖了从卷积神经网络 [73]到Transformers [74]的各种视觉模型。自然语言处理模型在综述 [75], [76]中得到了全面总结。强化学习的深入综述可在综述 [77]–[79]中找到。图神经网络的综述也有相关文献 [80]。此外,现有的视觉-语言模型综述为VLA提供了灵感 [67], [81]–[83]。另外,也有一篇关于早期具身智能工作的综述 [84]。 贡献。这篇综述是具身智能领域首篇深入的视觉-语言-动作模型综述。
- 综合评述。我们对具身智能中新兴的VLA模型进行了全面评述,涵盖了各种方面,包括架构、训练目标和机器人任务。
- 分类法。我们引入了当前机器人系统中层次结构的分类法,包括三个主要组成部分:预训练、控制策略和任务规划器。预训练技术旨在增强VLA的特定方面,如视觉编码器或动力学模型。低级控制策略根据指定的语言命令和感知的环境执行低级动作。高级任务规划器将长远任务分解为由控制策略执行的子任务。 -** 丰富的资源**。我们提供了训练和评估VLA模型所需资源的概述,通过比较其关键特性来调查最近引入的数据集和模拟器。此外,我们还包括了广泛采用的机器人控制和具身推理任务的基准。
- 未来方向。我们概述了该领域当前的挑战和未来的机会,如解决数据稀缺性、增强机器人灵活性、实现不同任务、环境和具身的泛化以及提高机器人安全性。 论文组织。§ II-A概述了单模态模型的代表性发展和里程碑。由于视觉-语言模型与视觉-语言-动作模型密切相关,§ II-B对视觉-语言模型的最新进展进行了比较。§ III探讨了各种类型的视觉-语言-动作模型。§ IV总结了具身智能的最新数据集、环境和基准。挑战和未来方向包含在§ V中。
视觉-语言-动作模型(VLA)是处理视觉和语言的多模态输入并输出机器人动作以完成具身任务的模型。它们作为具身智能领域中指令跟随机器人策略的基石。这些模型依赖于强大的视觉编码器、语言编码器和动作解码器。为了提升在各种机器人任务中的表现,一些VLA优先获取卓越的预训练视觉表示(见III-A节);另一些则专注于优化低级控制策略,能够接收短期任务指令并生成通过机器人运动规划可执行的动作(见III-B节);此外,还有一些VLA从低级控制中抽象出来,专注于将长远任务分解为由低级控制策略可执行的子任务(见III-C节)。因此,低级控制策略和高级任务规划器的结合可以视为层次化策略,如图3所示。本节内容组织涵盖了这三个主要方面。

