

大型语言模型(LLMs)在各种与代码相关的任务中取得了显著进展,特别是在从自然语言描述生成源代码的代码生成任务中,这些模型被称为代码LLMs。由于其在软件开发中的实际意义(例如GitHub Copilot),这个新兴领域吸引了学术研究人员和行业专业人士的广泛关注。尽管从自然语言处理(NLP)或软件工程(SE)或两者的角度,研究人员对各种代码任务的LLMs进行了积极探索,但目前缺乏一篇专门针对代码生成LLM的全面且最新的文献综述。在本综述中,我们旨在弥补这一空白,通过提供一篇系统的文献综述,为研究人员调查代码生成LLM的最新进展提供有价值的参考。我们引入了一个分类法,对代码生成LLM的最新发展进行分类和讨论,涵盖数据整理、最新进展、性能评估和实际应用等方面。此外,我们还提供了代码生成LLM发展的历史概览,并使用广泛认可的HumanEval和MBPP基准进行经验比较,以突出代码生成LLM能力的逐步提升。我们识别了学术界与实际开发之间的关键挑战和有前景的机会。此外,我们建立了一个专门的资源网站(https://codellm.github.io),以持续记录和传播该领域的最新进展。
引言
大型语言模型(LLMs),例如ChatGPT[171]的出现,深刻改变了自动化代码相关任务的格局[45],包括代码补全[78, 152, 233, 244]、代码翻译[48, 121, 211]和代码修复[109, 170, 176]。LLMs一个特别有趣的应用是代码生成,这项任务涉及从自然语言描述中生成源代码。尽管各研究对其定义有所不同[47, 191, 204, 232],但在本综述中,我们采用一致的定义,将代码生成定义为自然语言到代码(NL2Code)任务[15, 16, 264]。这一领域因其在学术界和工业界都引起了广泛兴趣,开发了如GitHub Copilot[45]、CodeGeeX[275]和Amazon CodeWhisperer等工具,这些工具利用先进的代码LLMs来促进软件开发。 最初对代码生成的研究主要利用启发式规则或专家系统,例如基于概率文法的框架[9, 57, 113]和专门的语言模型[59, 74, 106]。这些早期技术通常较为僵化且难以扩展。然而,基于Transformer的大型语言模型的引入改变了这一范式,使其成为首选方法,因其具备更高的能力和灵活性。LLMs的一个显著特点是其跟随指令的能力[51, 164, 173, 238, 250],即使是新手程序员也可以通过简单表达需求来编写代码。这一新兴能力使编程变得更加大众化,使更广泛的受众能够接触编程[264]。在代码生成任务中的LLMs表现出显著改进,如HumanEval排行榜所示,从PaLM 8B[49]的3.6%到LDB[279]的95.1%在Pass@1指标上的提升。由此可见,HumanEval基准[45]已成为评估LLMs代码能力的事实标准[45]。
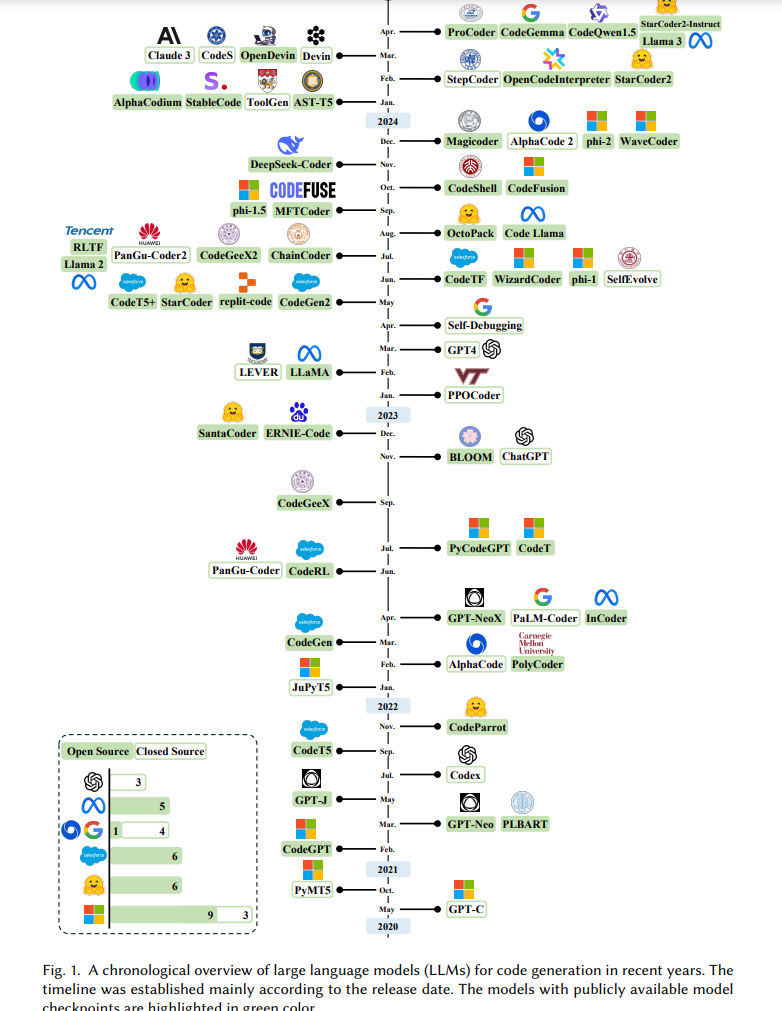
为了提供全面的时间演变概览,我们展示了LLMs用于代码生成的发展概览,如图1所示。代码生成LLMs的格局由一系列模型组成,其中一些模型如ChatGPT[173]、GPT4[5]、LLaMA[217, 218]和Claude 3[13]用于通用应用,而其他如StarCoder[132, 151]、Code LLaMA[196]、DeepSeek-Coder[79]和Code Gemma[54]则专门针对代码任务。代码生成与最新LLM进展的融合尤为关键,特别是当编程语言可以被视为多语言自然语言的不同方言时[15, 275]。这些模型不仅符合软件工程(SE)的要求,还推动了LLMs向实际生产的进步[271]。
尽管近期的综述从自然语言处理(NLP)、软件工程(SE)或两者结合的视角对代码LLMs进行了探讨[91, 264, 271, 278],它们通常涵盖了广泛的代码相关任务。仍然缺乏专门回顾代码生成高级主题的文献,如精细数据整理、指令调优、与反馈对齐、提示技术、自主编码代理的发展、检索增强代码生成、LLM作为代码生成的评审等。一个相关的重要研究[15, 264]也集中在文本到代码生成(NL2Code)的LLMs上,但主要考察了2020年至2022年发布的模型。因此,这一显著的时间差距导致了缺乏考虑最新进展的最新文献综述,包括如CodeQwen[215]、WizardCoder[154]和PPOCoder[204]等模型,以及前述高级主题的全面探索。
鉴于需要一个专门且最新的文献综述,本综述旨在填补这一空白。我们提供了一篇系统综述,为研究人员快速探索代码生成LLMs的最新进展提供了基础性参考。我们引入了一个分类法,对最近的进展进行分类和审视,涵盖数据整理[154, 231, 240]、高级主题[42, 47, 94, 125, 146, 152, 164, 166, 177, 205, 266]、评估方法[45, 85, 111, 284]和实际应用[45, 275]。这一分类法与代码生成LLM的完整生命周期相一致。此外,我们指出了关键挑战并识别了桥接研究与实际应用之间的有前景机会。因此,本综述使NLP和SE研究人员能够全面了解代码生成LLM,突出前沿方向和当前的障碍与前景。 综述的其余部分按照我们在图3中概述的分类法结构组织。在第2节中,我们介绍了LLM与Transformer架构的基础知识,并制定了代码生成LLM的任务。接下来在第3节中,我们提出了一种分类法,对代码生成LLMs的完整过程进行分类。在第4节中,我们在该分类框架内深入探讨代码生成LLMs的具体细节。在第5节中,我们强调了桥接研究与实际应用差距的关键挑战和有前景的机会,并在第6节总结本工作。
分类
近期大型语言模型(LLMs)开发的激增导致大量这些模型通过持续预训练或微调被重新用于代码生成任务。这一趋势在开源模型领域尤为明显。例如,Meta AI最初公开了LLaMA [217]模型,随后发布了专为代码生成设计的Code LLaMA [196]。类似地,DeepSeeker开发并发布了DeepSeek LLM [25],随后扩展为专门用于代码生成的变体DeepSeek Coder [79]。Qwen团队基于其原始的Qwen [19]模型开发并发布了Code Qwen [215]。微软则推出了WizardLM [250],并正在探索其面向编程的对应模型WizardCoder [154]。谷歌也加入了这一行列,发布了Gemma [214],随后发布了Code Gemma [54]。除了简单地将通用LLMs适用于代码相关任务外,还出现了大量专门为代码生成设计的模型。值得注意的例子包括StarCoder [132]、OctoCoder [164]和CodeGen [169]。这些模型强调了以代码生成为重点开发的LLMs的趋势。 认识到这些发展的重要性,我们提出了一种分类法,对代码生成LLMs的最新进展进行分类和评估。此分类法如图3所示,作为研究人员快速熟悉该动态领域最新技术的全面参考。 在接下来的章节中,我们将对与代码生成相关的每个类别进行深入分析。这将包括问题的定义、要解决的挑战以及对最突出的模型及其性能评估的比较。
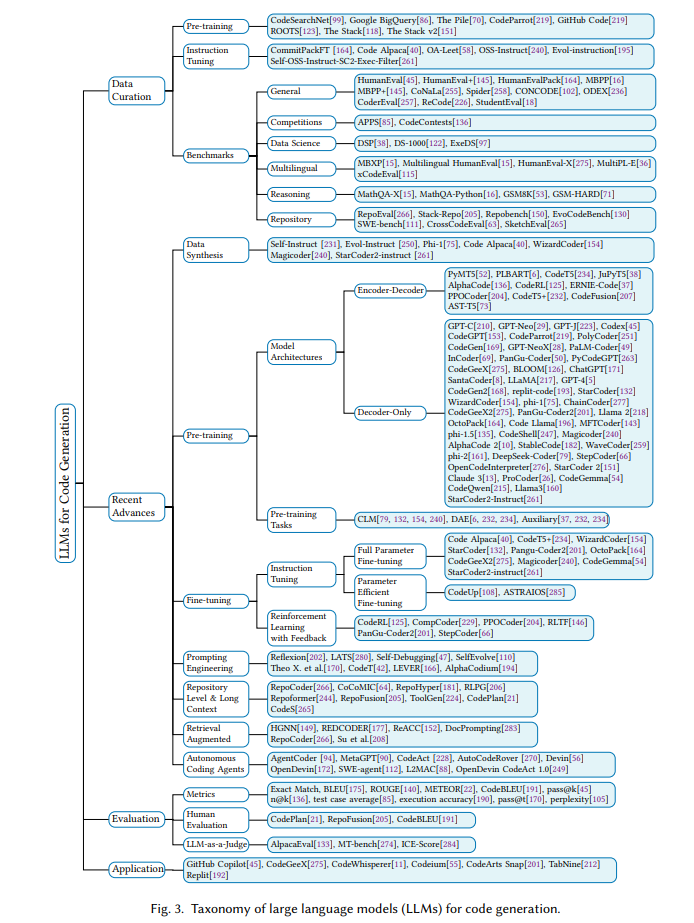
大型语言模型(LLMs)与Transformer架构在多个领域引发了革命性变革,其在代码生成中的应用尤为显著。这些模型遵循一个全面的过程,从代码数据的整理和合成开始,然后是包括预训练和微调在内的结构化训练方法,并使用复杂的提示工程技术。最近的进展包括集成了库级和检索增强的代码生成,以及自主编码代理的发展。此外,评估LLMs的编码能力已成为该研究领域的重要组成部分。 在接下来的章节中,我们将详细探讨这些与代码生成相关的LLMs各个方面。第4.1节将介绍在LLMs开发的各个阶段中使用的数据整理和处理策略。第4.2节将讨论旨在缓解高质量数据稀缺性的数据合成方法。第4.3节将概述用于代码生成的LLMs的流行模型架构。第4.4节将探讨全参数微调和参数高效微调的技术,这些技术对于将LLMs调整为代码生成任务至关重要。第4.5节将通过强化学习和利用反馈的力量,阐述提升代码质量的方法。第4.6节将深入研究通过策略性使用提示来最大化LLMs的编码能力。第4.7和4.8节将分别详细说明库级和检索增强代码生成的创新方法。此外,第4.9节将讨论自主编码代理这一令人兴奋的领域。最后,第4.11节将提供一些利用LLMs进行代码生成的实际应用见解,展示这些复杂模型的现实世界影响。通过这一全面探索,我们旨在强调LLMs在自动化代码生成领域的意义和潜力。 结论
在本综述中,我们提供了一篇系统的文献综述,为研究代码生成LLMs最新进展的研究人员提供了宝贵的参考。我们详细介绍和分析了数据整理、最新进展、性能评估和实际应用。此外,我们还展示了近年来代码生成LLMs演变的历史概览,并使用广泛认可的HumanEval和MBPP基准进行经验比较,以突出代码生成LLMs能力的渐进提升。我们还识别了学术界与实际开发之间的关键挑战和有前景的机会,以供未来研究。此外,我们建立了一个专门的资源网站,以持续记录和传播该领域的最新进展。我们希望本综述能够为代码生成LLMs提供一个全面而系统的概览,促进其蓬勃发展。我们乐观地相信,LLMs最终将改变编码的各个方面,自动编写安全、有用、准确、可信且可控的代码,如同专业程序员一样,甚至解决当前人类无法解决的编码问题。
