

像 DeepSeek-R1 这样的“大型推理模型”(Large Reasoning Models)标志着大语言模型(LLMs)在处理复杂问题方式上的根本性转变。与直接对输入生成答案的方法不同,DeepSeek-R1 会构建详细的多步推理链条,在给出答案之前仿佛会“思考”问题的全过程。这一推理过程对用户是公开可见的,为研究模型的推理行为提供了无限可能,并开启了“思维学”(Thoughtology)这一新兴研究领域。
我们从 DeepSeek-R1 推理构建块的基本分类体系出发,深入分析了其推理长度的影响及可控性、对冗长或混乱上下文的处理方式、文化和安全相关问题,以及 DeepSeek-R1 在类人语言处理与世界建模等认知现象中的定位。我们的研究结果描绘了一幅细致入微的图景。值得注意的是,我们发现 DeepSeek-R1 存在一个推理“最佳区间”(sweet spot),当推理时间过长时,模型性能反而可能受到影响。此外,我们还观察到 DeepSeek-R1 有反复沉湎于既有问题表述的倾向,从而阻碍进一步探索。 我们还指出,相较于其非推理版本,DeepSeek-R1 存在较严重的安全性脆弱性,这种脆弱性甚至可能对安全对齐(safety-aligned)的 LLMs 造成负面影响。
最近在构建大语言模型(LLMs)方面的进展,使研究重点转向了开发具备复杂多步推理能力的模型(DeepSeek-AI 等,2025a;OpenAI,2024)。虽然早期工作主要通过“思维链提示”(chain-of-thought prompting, CoT)来引导模型进行推理(Wei 等,2022;Zhou 等,2023),但我们目前正目睹一个根本性的转变:推理能力被直接内嵌于模型中,使其在生成答案前先进行推理。我们将这类模型称为大型推理模型(Large Reasoning Models, LRMs),并将其推理链称为“thoughts”。
LRMs 逐步生成 thoughts,可用于积累解题进度、自我验证,或探索备选方案,直到模型对最终答案有充分信心为止。图 1.1 展示了 LLM 与 LRM 输出结果的对比。尽管 LLM 的输出中可能包含部分中间推理步骤,但通常缺乏探索能力。此外,一旦出错,LLM 往往无法回溯并尝试其他方法。而 LRM 则通过多方案探索与验证进行推理,并最终总结最佳解法。
LRMs 的进展主要得益于强化学习:模型会对能产生正确答案的推理过程给予奖励(DeepSeek-AI 等,2025a;Kazemnejad 等,2024;Kumar 等,2024;Lambert,2024;OpenAI,2024;Shao 等,2024)。这类模型在测试时也可以利用其生成长推理链的能力,这一过程称为推理时扩展(inference-time scaling)或测试时扩展(test-time scaling):通过强制模型“多思考”以期获得更优解(Muennighoff 等,2025;Snell 等,2025)。在这一系列进展的推动下,LRMs 在复杂推理任务中(如数学解题、代码生成)表现出显著提升。
OpenAI 的 o1 模型(OpenAI,2024)首次展示了 LRM 的巨大潜力,但其推理链及训练方法并未公开,从而限制了学界对其推理行为的深入研究,也引发了对其训练流程的广泛猜测(Rush 与 Ritter,2025)。因此,DeepSeek-R1 的推出产生了重大影响:作为一款性能堪比 o1 的高能力 LRM,且在计算效率上更具优势。

DeepSeek-R1 的突出之处体现在以下几个方面: 1. 它是首个对输入提供完整 thought 访问权限的高性能 LRM; 1. 它的训练流程、模型代码和参数权重均已开源(但训练数据未公开); 1. 其前期版本 R1-Zero 表明,通过强化学习即可获得复杂多步推理、自我验证以及看似“灵光乍现”(aha moments)式的洞察能力,而无需通过监督学习显式教授。
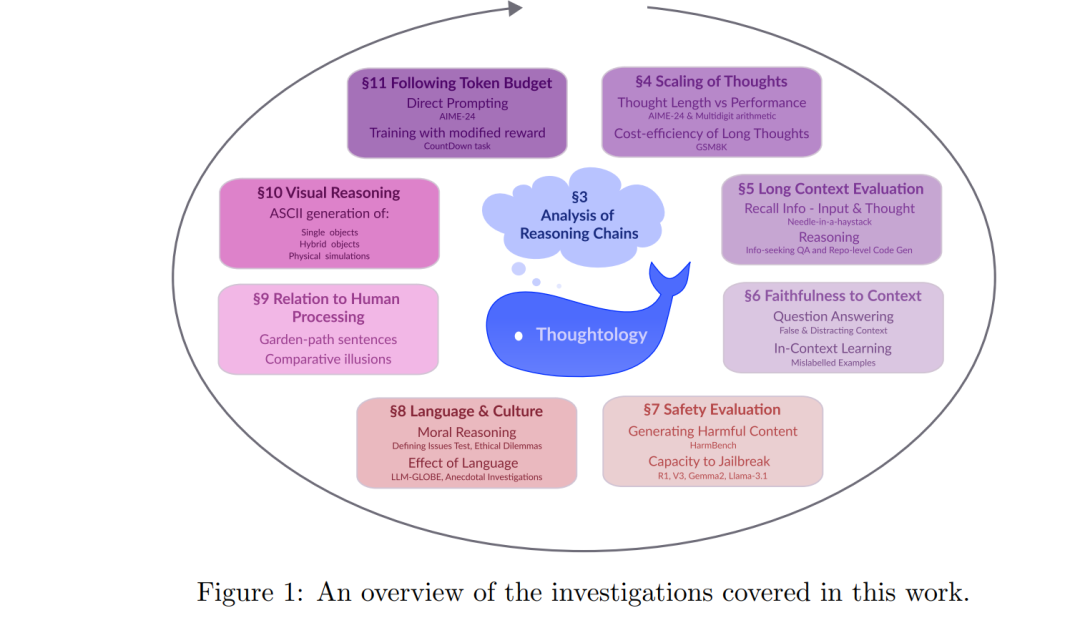
DeepSeek-R1 提供的 thought 透明访问使我们得以系统性地研究其推理行为,我们将这一研究领域称为思维学(Thoughtology)。在思维学的框架下,我们分析了 DeepSeek-R1 推理链中的常见模式、推理长度的影响与可控性、冗长或混乱上下文对其推理过程的影响、其在安全性和文化价值观方面的倾向,以及其与人类语言处理与世界建模之间的相似性。图 1 展示了我们的研究概览,为理解 DeepSeek-R1 的能力边界提供了第一步探索,并为未来的推理改进研究提供了方向。
我们的主要发现包括:
推理结构一致性:DeepSeek-R1 的 thoughts 遵循一致的结构。模型会先明确问题目标,再将问题拆解为中间解,并在此基础上进行多轮再探索或再验证,尽管这些再验证往往缺乏多样性。 * 推理长度非线性影响性能:推理长度的持续增加并不一定提升性能。每类问题存在一个“最佳推理区间(sweet spot)”,超过该范围后准确率会显著下降。且 DeepSeek-R1 无法自主调控其推理长度。 * 上下文与参数知识冲突:当上下文信息与模型参数知识冲突时,DeepSeek-R1 倾向优先采信上下文信息。但当输入或推理链过长时,其表现会变得不稳定,输出混乱、语义失真。 * 安全性脆弱性:与非推理版本 DeepSeek-V3(DeepSeek-AI 等,2025b)相比,DeepSeek-R1 更容易生成有害内容,且更擅长执行“越狱攻击”,从而引发其他 LLM 输出不当信息。 * 文化与语言差异:面对道德或文化类问题时,DeepSeek-R1 在英文提示下的推理时间显著长于中文提示,且会根据语言提供不同文化价值取向的回答。 * 类人语言处理偏差:对于人类感知复杂的语句,DeepSeek-R1 会生成更长的推理链,但对简单语句也常表现出不符合人类逻辑的异常行为。 * 世界建模能力不足:在处理涉及视觉与物理推理的任务中,虽然能识别子组件,但难以整合信息或进行草图迭代,依赖符号与数学推理而非直觉性认知过程。
文章结构概览:
我们将本研究分为五大部分: 模型推理链的结构与模式; 推理长度的影响与控制; 高复杂度上下文下的模型行为; 安全性与文化适应性问题; 推理过程与人类认知现象的对比。
在第 2 节中,我们简要回顾了 LRMs 的发展背景与 DeepSeek-R1 的设计理念;第 3 节详细分析了其推理模式,发现其思维链常由问题定义、问题拆解与反复重建三个阶段组成,并且频繁的重建过程(我们称之为反刍(rumination))是其长推理链的主要来源。 第 4 节探讨了推理长度对数学推理任务的影响,并指出存在一个问题相关的最优推理区间。我们也研究了推理长度与性能之间的权衡,发现 DeepSeek-R1 存在效率瓶颈,设置 token 限额可以在几乎不影响性能的前提下大幅降低计算成本。第 11 节进一步评估了 DeepSeek-R1 遵循提示中 token 限额的能力,并通过概念验证实验探讨了基于 token 限额设定奖励的训练方法。 第 5 和第 6 节将 DeepSeek-R1 投入更真实的上下文任务中,分析其处理大段输入与冗长推理链的能力,以及其如何应对与参数知识冲突的误导性输入。 第 7 节和第 8 节聚焦于安全性与文化行为,发现 DeepSeek-R1 在输出有害信息与执行越狱攻击方面的能力远超 V3,并在多语言提示下展现出不同文化偏好。 第 9 和第 10 节分析了 DeepSeek-R1 与人类认知之间的相似性与偏差。尽管其推理链长度与语句复杂度呈现类人对应关系,但其内部结构暴露出循环与非人类逻辑的特征。在视觉与物理推理任务中,DeepSeek-R1 偏向使用符号推理,缺乏直观与迭代过程。



