【复旦大学-SP2020】NLP语言模型隐私泄漏风险

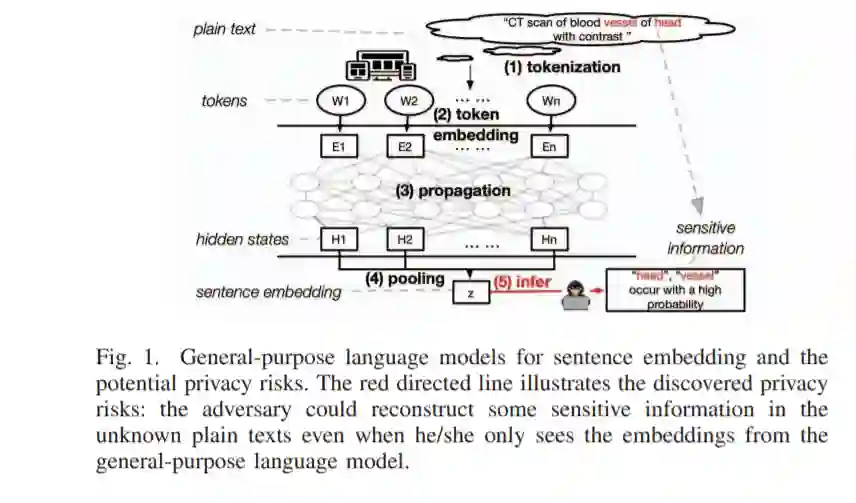
最近,在自然语言处理(NLP)中构建通用语言模型(如谷歌的Bert和OpenAI的GPT-2)用于文本特征提取的新范式出现了。对于下游建模,已经出现并开始在各种下游NLP任务和现实世界系统(例如,谷歌的搜索引擎)中发现它的应用。为了获得通用的文本嵌入,这些语言模型具有高度复杂的体系结构,具有数百万个可学习的参数,通常在使用之前对数十亿个句子进行预处理。众所周知,这种做法确实提高了许多下游NLP任务的最新性能。但是,改进的实用程序不是免费的。我们发现,通用语言模型中的文本嵌入会从纯文本中捕获很多敏感信息。一旦被对手访问,嵌入信息可以被反向设计,以披露受害者的敏感信息,以进行进一步的骚扰。尽管这样的隐私风险可能会对这些有前途的NLP工具的未来影响造成真正的威胁,但是目前还没有针对主流行业级语言模型的公开攻击或系统评估。为了弥补这一差距,我们首次系统地研究了8种最先进的语言模型和4个不同的案例。通过构建两个新的攻击类,我们的研究表明上述隐私风险确实存在,并可能对通用语言模型在身份、基因组、医疗保健和位置等敏感数据上的应用造成实际威胁。例如,当我们从病人的医疗描述的Bert embeddings中推断出精确的疾病位置时,我们向几乎没有先验知识的对手展示了大约75%的准确性。作为可能的对策,我们提出了4种不同的防御(通过舍入、差异隐私、对抗性训练和子空间投影)来混淆无保护的嵌入,以达到缓解的目的。在广泛评估的基础上,我们还对每一种防御所带来的效用-隐私权衡进行了初步分析,希望能对未来的缓解研究有所帮助。
https://www.computer.org/csdl/proceedings-article/sp/2020/349700b471/1j2LgooZ4fS
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PRLM” 就可以获取《【复旦大学-SP2020】NLP语言模型隐私泄漏风险》专知下载链接





