

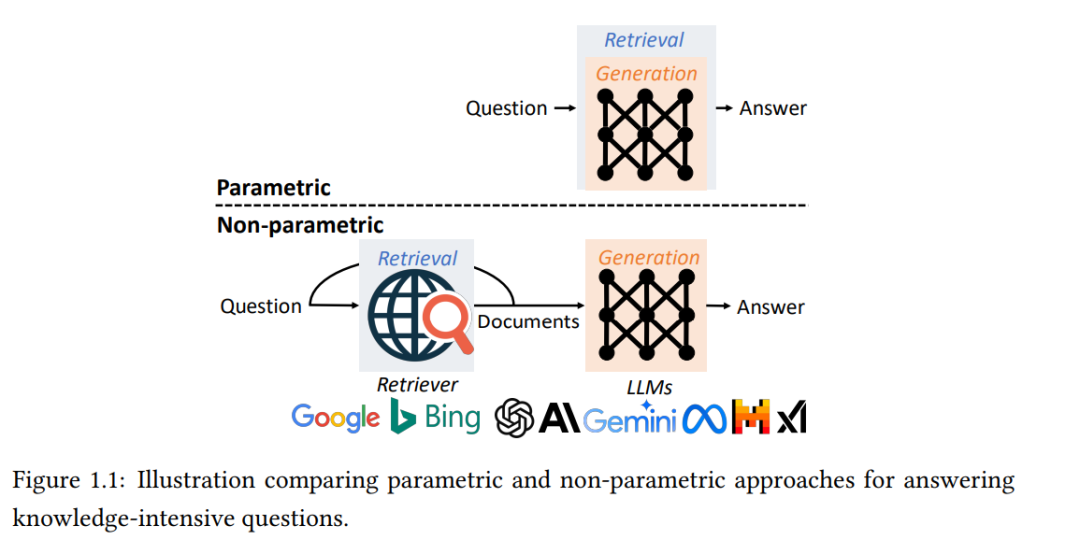
大型语言模型(LLMs)在帮助人们获取信息方面越来越重要,从“世界上最大的冰盖在哪里”这样简单的事实性问题到需要获取实时信息和推理的复杂问题,如“计划一次迈阿密的度假”。有两种处理需要事实知识的问题的范式:参数化方法将知识存储在LLMs的参数中,并通过提示来引出这些知识;非参数化方法将知识检索外包给外部的非参数化数据存储。在本论文中,我们旨在研究、比较并增强这两种范式的能力。 由于LLMs通过在多样的语料库上进行预训练,已经在其参数中积累了大量知识,因此可以在被提示提问时直接生成答案。在论文的第一部分中,我们重点关注利用LLMs参数中包含的事实性知识的参数化方法。我们首先研究通过组合从不同提示中得出的多种预测来提取更多知识的方法。然后,我们校准LLMs,使其在回答超出其知识范围的问题时变得更加可信。我们发现,即使LLMs完全记住文档并能够逐字复述它们,仍然常常无法回答有关这些文档的问题。为了增强LLMs从文档中吸收知识的能力,我们提出了在预训练文档之前进行问题回答任务教学的预指令调整方法。
参数化方法提供了一个简单的接口,但它们存在幻觉问题,并且无法访问实时的外部信息。在论文的第二部分中,我们重点关注通过非参数化数据存储扩展LLMs的非参数化方法,这通常由一个文档语料库和一个检索器构建。标准的检索增强生成(RAG)流程包括基于嵌入的检索器和基于LLM的生成器,通常需要单独的训练程序,并且往往受限于检索器的性能。我们引入了一种将检索与生成融合在单个变换器中的端到端解决方案,并直接使用注意力机制进行检索。为了解决需要详细回答的复杂问题,我们引入了Active RAG,它在生成过程中动态和主动地检索信息。最后,我们通过比较和调和两种范式并提供对未来方向的见解来总结我们的研究。



成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日