

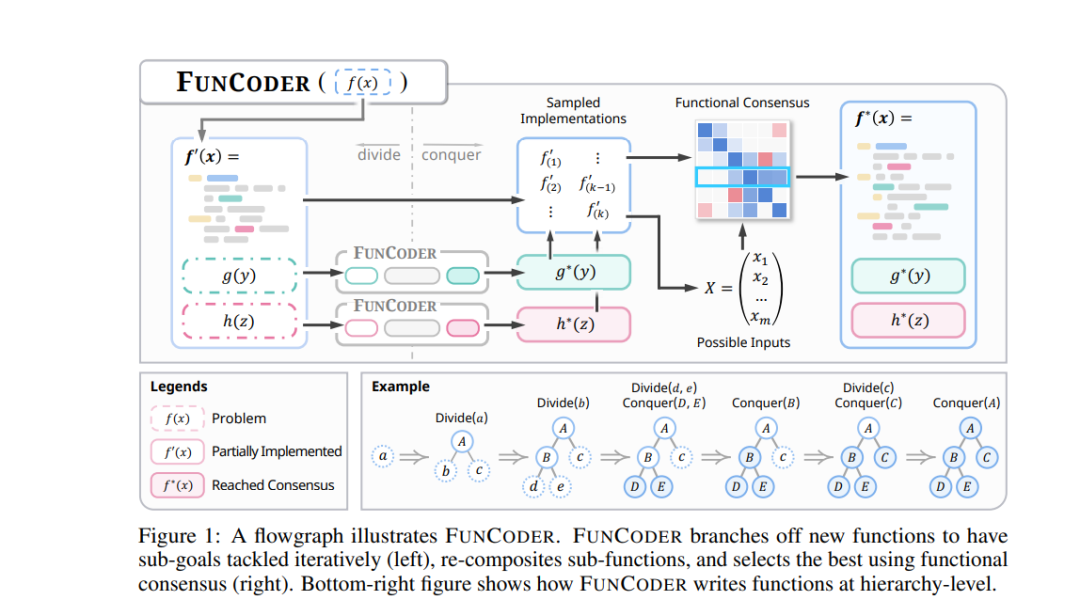
大型语言模型(LLM)在代码生成方面取得了显著进展,但它们在处理具有复杂需求的程序时仍面临挑战。近期的研究尝试通过“规划与求解”(Plan-and-Solve)的分解策略以降低复杂性,并利用自测机制不断优化生成的代码。然而,提前规划复杂需求可能非常困难,同时生成的自测需要非常准确才能实现自我改进。针对这一问题,我们提出了 FunCoder,一个结合了分治(divide-and-conquer)策略和功能共识(functional consensus)的代码生成框架。具体而言,FunCoder 在代码生成过程中递归地将子函数分解为较小的目标,并用树状层次结构加以表示。这些子函数随后会组合在一起,以解决更为复杂的任务。此外,我们通过识别程序行为的相似性来形成共识函数,从而降低错误传播的风险。在 HumanEval、MBPP、xCodeEval 和 MATH 测试中,FunCoder 在 GPT-3.5 和 GPT-4 上相较于现有方法平均性能提升了 9.8%。不仅如此,FunCoder 在较小的模型上同样展现了出色的表现:借助 FunCoder,StableCode-3b 在 HumanEval 测试中的性能超越了 GPT-3.5(提升了 18.6%),并达到了 GPT-4 性能的 97.7%。进一步分析表明,我们提出的动态函数分解方法能够有效应对复杂需求,且功能共识在正确性评估方面优于自测机制。
https://www.zhuanzhi.ai/paper/e9b3b05614fb83a0e858cdc7aa5bf3fa
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2024年11月14日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2024年11月14日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日