视觉基础模型(Vision Foundation Models, VFMs)和视觉语言模型(Vision-Language Models, VLMs)凭借其强大的泛化能力,近年来在领域泛化语义分割(Domain Generalized Semantic Segmentation, DGSS)任务中受到广泛关注。然而,现有的 DGSS 方法通常仅依赖 VFMs 或 VLMs 中的一种,忽视了它们之间的互补优势。以 DINOv2 为代表的 VFMs 擅长捕捉细粒度特征,而如 CLIP 等 VLMs 则在文本对齐方面表现优异,但往往难以处理粗粒度语义。
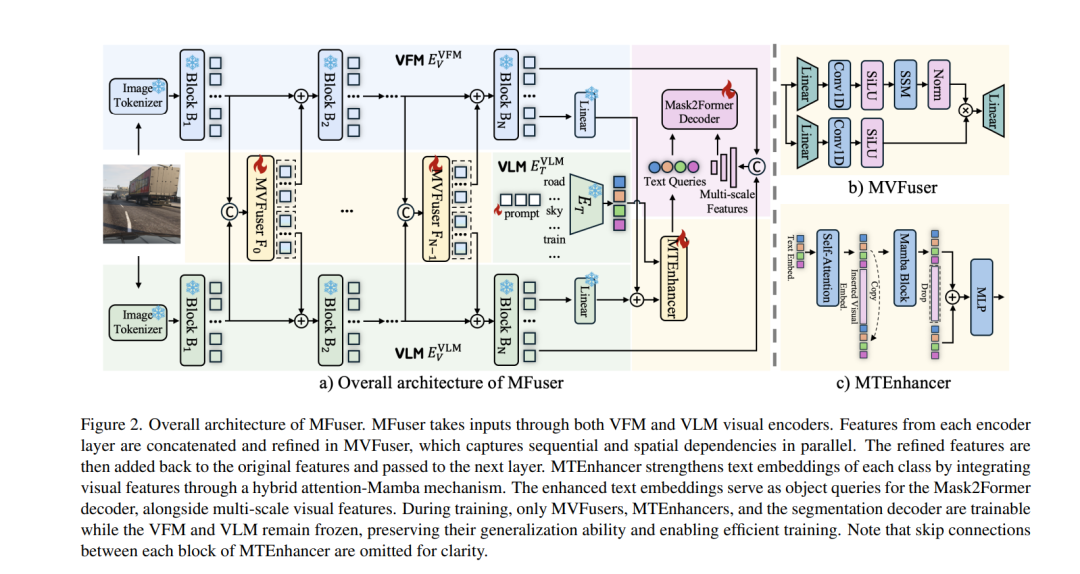
尽管 VFMs 和 VLMs 具备互补能力,但将两者有效融合仍具有挑战性,特别是在注意力机制中,因 patch tokens 数量增多而导致长序列建模难度增加。为此,我们提出了 MFuser,一种基于 Mamba 的新型融合框架,可高效整合 VFMs 与 VLMs 的优势,同时在序列长度上保持线性可扩展性。 MFuser 主要包括两个关键组件: * MVFuser:作为协同适配器(co-adapter),用于联合微调两种模型,同时捕捉序列与空间动态信息; * MTEnhancer:一种融合注意力机制与 Mamba 的混合模块,通过引入图像先验对文本嵌入进行增强。
我们的方法在实现精确特征定位的同时,也保持了强文本对齐能力,且不会引入显著的计算开销。大量实验表明,MFuser 在多个基准测试上显著优于现有的 DGSS 方法:在合成到真实(synthetic-to-real)场景中达到 68.20 mIoU,在真实到真实(real-to-real)场景中达到 71.87 mIoU。 项目代码已开源,地址为:
👉 https://github.com/devinxzhang/MFuser