

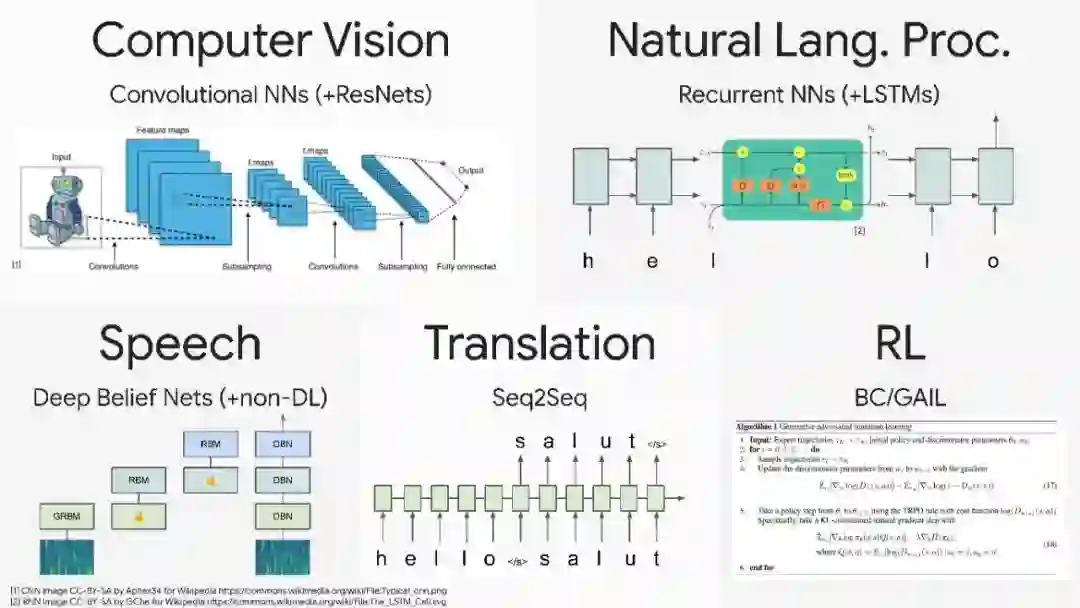
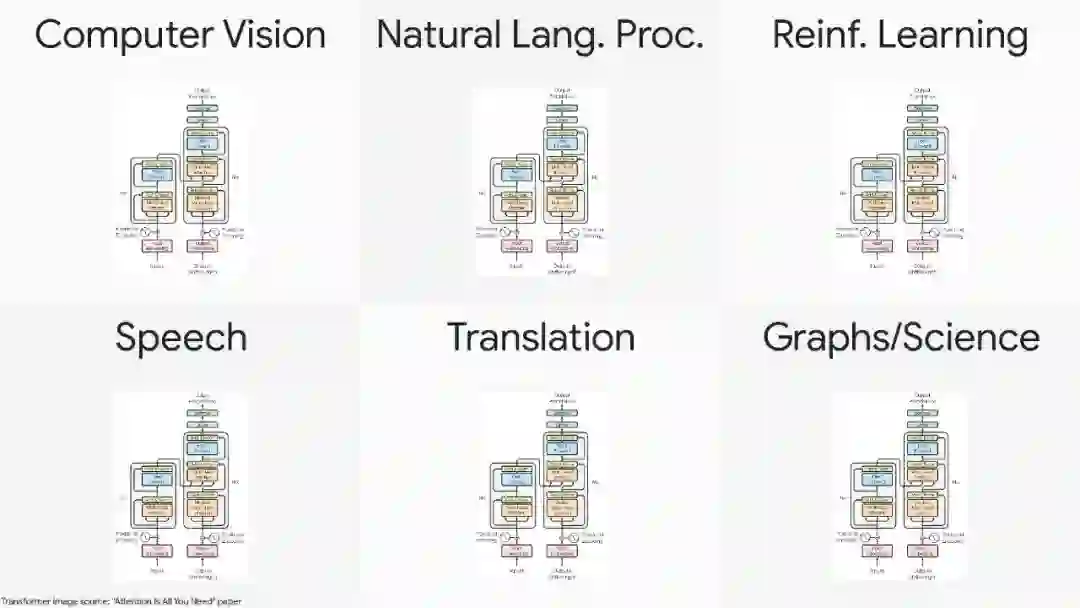
本次演讲将讨论通过大规模的预训练和少样本迁移来学习一般的视觉表示,特别关注Vision Transformer (ViT)架构,它将transformers推广到视觉领域。Transformer模型架构最近引起了极大的兴趣,因为它们在语言、视觉和强化学习等领域的有效性。例如,在自然语言处理领域,Transformer已经成为现代深度学习堆栈中不可缺少的主要部分。最近,提出的令人眼花缭乱的X-former模型如Linformer, Performer, Longformer等这些都改进了原始Transformer架构的X-former模型,其中许多改进了计算和内存效率。为了帮助热心的研究人员在这一混乱中给予指导,本文描述了大量经过深思熟虑的最新高效X-former模型的选择,提供了一个跨多个领域的现有工作和模型的有组织和全面的概述。关键词:深度学习,自然语言处理,Transformer模型,注意力模型
https://www.zhuanzhi.ai/paper/39a97bd373cc6f37c6b2e9026f3422e8


成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
相关主题
相关VIP内容
相关资讯