Google最新《高效Transformers》2022综述大全,39页pdf阐述九大类提升Transformers效率方式
![]()
新智元报道
新智元报道
来源:专知
【新智元导读】最近Google的Yi Tay发布了关于Transformers最新论文,提供这类模型的最新进展的全面概述。
Transformer模型是当下的研究焦点,因为它们在语言、视觉和强化学习等领域的有效性。例如,在自然语言处理领域,Transformer已经成为现代深度学习堆栈中不可缺少的主要部分。
最近,提出的令人眼花缭乱的X-former模型Linformer, Performer, Longformer等这些都改进了原始Transformer架构的X-former模型,其中许多改进了计算和内存效率。
为了帮助热心的研究人员在这一混乱中给予指导,本文描述了大量经过深思熟虑的最新高效X-former模型的选择,提供了一个跨多个领域的现有工作和模型的有组织和全面的概述。

论文链接:https://arxiv.org/abs/2009.06732
介绍
Transformer是现代深度学习领域中一股强大的力量。Transformer无处不在,在语言理解、图像处理等许多领域都产生了巨大的影响。因此,在过去的几年里,大量的研究致力于对该模型进行根本性的改进,这是很自然的。这种巨大的兴趣也刺激了对该模式更高效变体的研究。
最近出现了大量的Transformer模型变体,研究人员和实践者可能会发现跟上创新的速度很有挑战性。在撰写本文时,仅在过去6个月里就提出了近12种新的以效率为中心的模式。因此,对现有文献进行综述,既有利于社区,又十分及时。
自注意力机制是确定Transformer模型的一个关键特性。该机制可以看作是一种类似图的归纳偏差,它通过基于关联的池化操作将序列中的所有标记连接起来。一个众所周知的自注意力问题是二次时间和记忆复杂性,这可能阻碍模型在许多设置的可伸缩性。最近,为了解决这个问题,出现了大量的模型变体。以下我们将这类型号命名为「高效Transformers」。
根据上下文,可以对模型的效率进行不同的解释。它可能指的是模型的内存占用情况,当模型运行的加速器的内存有限时,这一点非常重要。效率也可能指计算成本,例如,在训练和推理期间的失败次数。特别是对于设备上的应用,模型应该能够在有限的计算预算下运行。在这篇综述中,我们提到了Transformer在内存和计算方面的效率,当它们被用于建模大型输入时。
有效的自注意力模型在建模长序列的应用中是至关重要的。例如,文档、图像和视频通常都由相对大量的像素或标记组成。因此,处理长序列的效率对于Transformer的广泛采用至关重要。
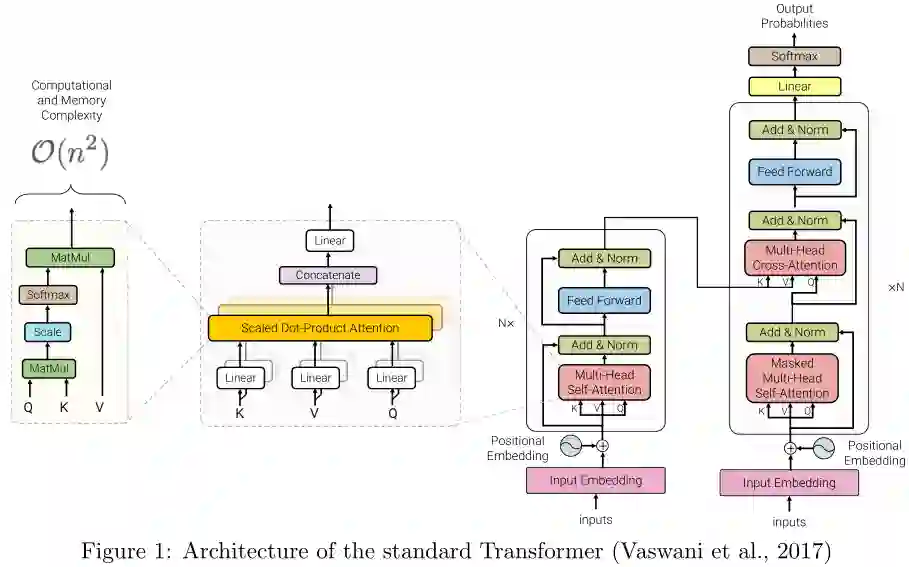
本篇综述旨在提供这类模型的最新进展的全面概述。我们主要关注的是通过解决自注意力机制的二次复杂性问题来提高Transformer效率的建模进展和架构创新,我们还将在后面的章节简要讨论一般改进和其他效率改进。
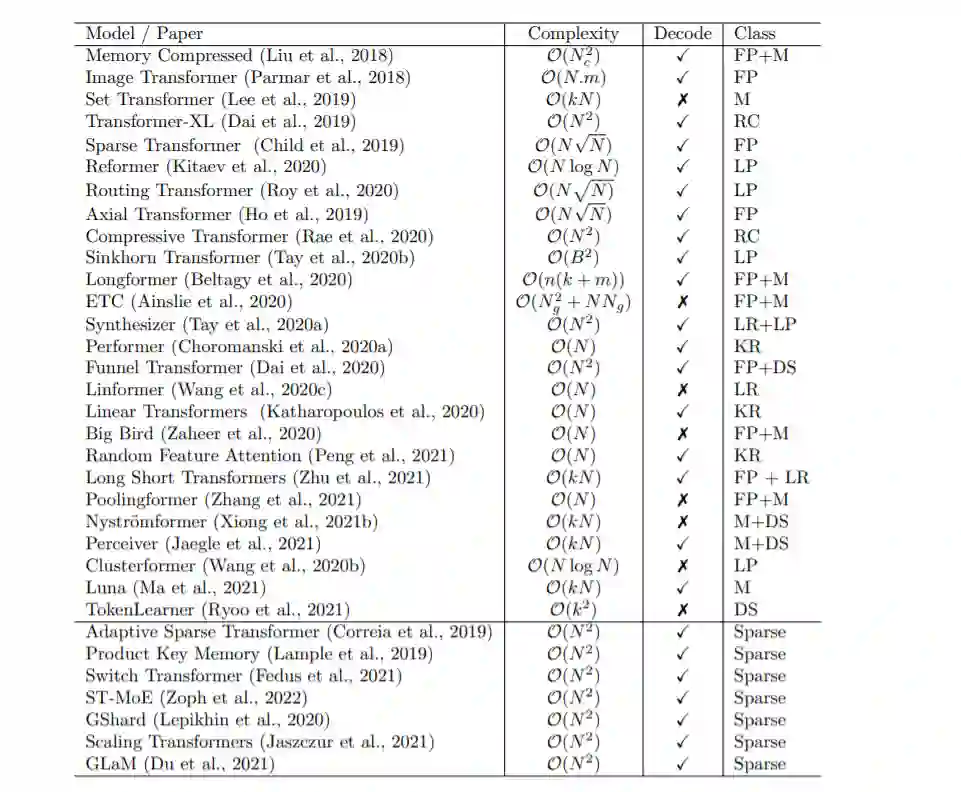
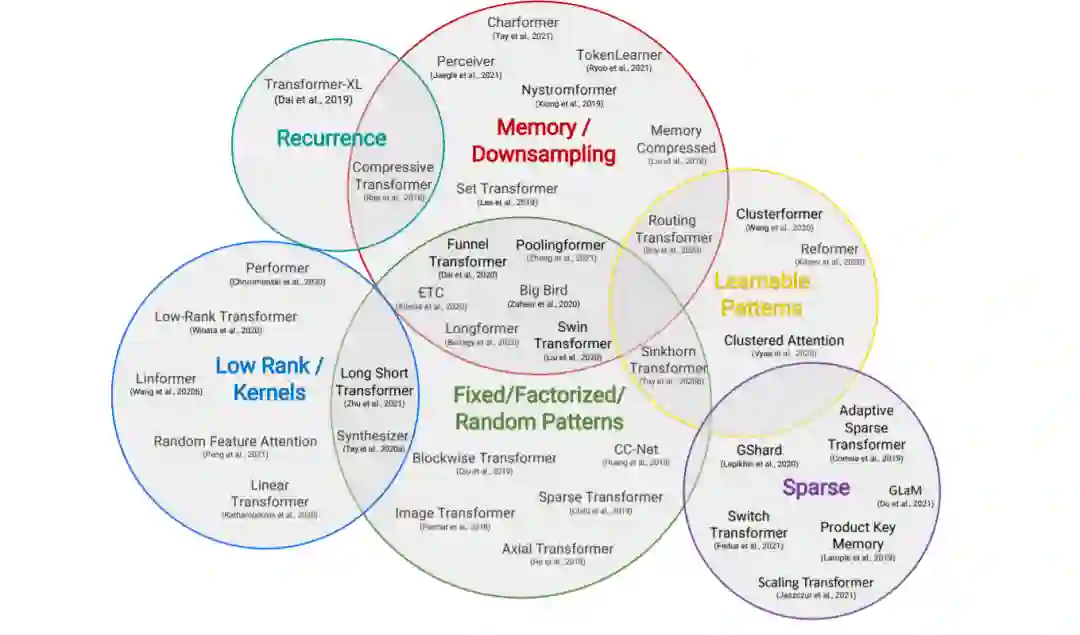
本文提出了一种高效Transformer模型的分类方法,并通过技术创新和主要用例对其进行了表征。特别地,我们回顾了在语言和视觉领域都有应用的Transformer模型,试图对各个领域的文献进行分析。我们还提供了许多这些模型的详细介绍,并绘制了它们之间的联系。
本节概述了高效Transformer模型的一般分类,以其核心技术和主要用例为特征。尽管这些模型的主要目标是提高自注意机制的内存复杂度,但我们还包括了提高Transformer体系结构的一般效率的方法。
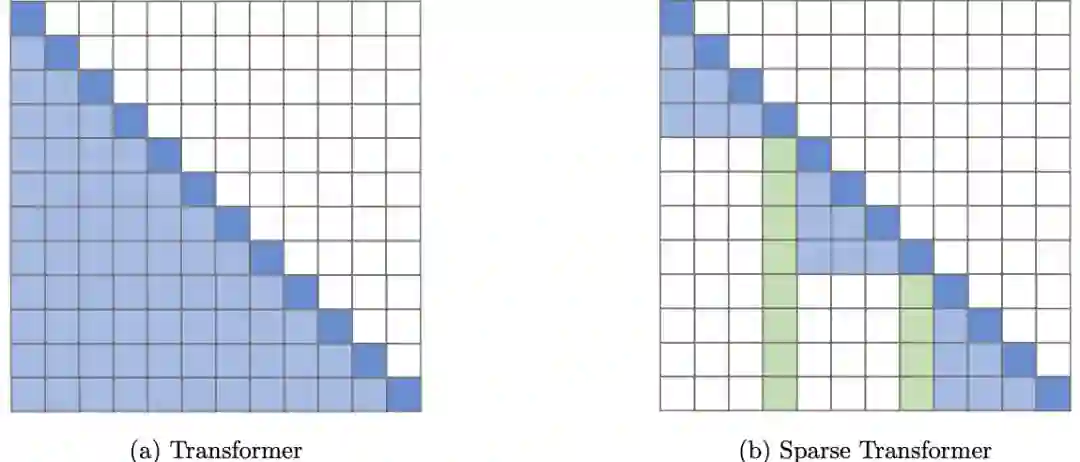
固定模式(FP)——对自注意最早的修改是通过将视野限制在固定的、预定义的模式(如局部窗口和固定步距的块模式)来简化注意力矩阵。
组合模式(CP)——组合方法的关键思想是通过组合两个或多个不同的访问模式来提高覆盖率。例如,Sparse Transformer通过将一半的头部分配给每个模式,将跨步注意力和局部注意力结合起来。类似地,轴向Transformer运用了一系列以高维张量作为输入的自注意计算,每个计算都沿着输入张量的单个轴。从本质上说,模式的组合以与固定模式相同的方式降低了内存复杂度。但是,不同之处在于,多个模式的聚合和组合提高了自注意机制的整体覆盖率。
可学习的模式(LP) -固定的,预先确定的模式的扩展是可学习的模式。不出所料,使用可学习模式的模型旨在以数据驱动的方式学习访问模式。学习模式的一个关键特征是确定令牌相关性的概念,然后将令牌分配到桶或集群。值得注意的是,Reformer 引入了一种基于哈希的相似性度量,以有效地将令牌聚为块。类似地,路由Transformer对令牌使用在线k-means聚类。同时,Sinkhorn排序网络通过学习对输入序列的块进行排序,暴露了注意权值的稀疏性。在所有这些模型中,相似函数与网络的其他部分一起端到端训练。可学习模式的关键思想仍然是利用固定模式(块状模式)。然而,这类方法学会了对输入标记进行排序/聚类——在保持固定模式方法的效率优势的同时,实现了序列的更优全局视图。
神经记忆——另一个突出的方法是利用可学习的侧记忆模块,它可以一次访问多个令牌。一种常见的形式是全局神经存储器,它能够访问整个序列。全局标记充当一种模型内存的形式,它学习从输入序列标记中收集数据。这是在Set transformer中首次引入的诱导点方法。这些参数通常被解释为「内存」,用作将来处理的临时上下文的一种形式。这可以被认为是参数关注的一种形式。ETC 和Longformer也使用了全局记忆令牌。在有限的神经记忆(或诱导点)中,我们能够对输入序列执行一个初步的类似于池的操作来压缩输入序列——在设计高效的自注意模块时,这是一个可以随意使用的巧妙技巧。
低秩方法——另一种新兴的技术是通过利用自注意矩阵的低秩近似来提高效率。
内核——另一个最近流行的提高transformer效率的方法是通过内核化来查看注意力机制。
递归——块方法的一个自然扩展是通过递归连接这些块。
下采样——另一种降低计算成本的常用方法是降低序列的分辨率,从而以相应的系数降低计算成本。
稀疏模型和条件计算——虽然不是专门针对注意力模块,稀疏模型稀疏地激活一个参数子集,这通常提高了参数与FLOPs的比率。
参考资料:
https://arxiv.org/abs/2009.06732




